Many thanks to Stefan Güttel, Sven Hammarling, Stephanie Lai, Françoise Tisseur and Marcus Webb for organizing the conference and the Royal Society, MathWorks and the University of Manchester for financial support.
Sixteen members of the Numerical Linear Algebra group at the University of Manchester recently attended a two-day creativity workshop in order to generate ideas for our research and other activities. The workshop was facilitated by Dennis Sherwood, who is an expert in creativity and has run many such workshops. Dennis and I have previously collaborated on workshops for the Manchester Numerical Analysis group (2013), the EPSRC NA-HPC Network (2014), and the SIAM leadership (2018).
A creativity workshop brings together a group of people to tackle questions using a structured approach, in which people share what they know about the question, ask “how might this be different” about the aspects identified, and then discuss the resulting possibilities. A key feature of these workshops is that every idea is captured—on flip charts, coloured cards, and post-it notes—and ideas are not evaluated until they have all been generated. This approach contrasts will the all-too-common situation where excellent ideas generated in a discussion are instantly dismissed because of a “that will never work” reaction.
At our workshop a number of topics were addressed, covering strategic plans for the group and plans for future research projects and grant proposals, including “Mixed precision algorithms”, “Being a magnet for talent”, and “Conferences”. Many ideas were generated and assessed and the group is now planning the next steps with the help of the detailed 70-page written report produced by Dennis.
In July 2021, Sven Hammarling, Françoise Tisseur and I organized an online workshop New Directions in Numerical Linear Algebra and High Performance Computing. The workshop brought together researchers working in numerical linear algebra and high performance computing to discuss current developments and challenges in the light of evolving computer hardware. It was held to honour Jack Dongarra on the occasion of his 70th birthday. The workshop had been postponed from July 2020 as a result of the pandemic.
Videos of the talks are now available on the Numerical Linear Algebra Group’s YouTube channel and are included below. Slides for the talks are available on the workshop website.
Sven Hammarling (The University of Manchester), “Jack Dongarra”.
Iain Duff (STFC-RAL and CERFACS), “Jack”
James Demmel (University of California, Berkeley), “New Communication-Avoiding Algorithms, and Fixing Old Bugs in the BLAS and LAPACK”
Piotr Luszczek (University of Tennessee), “Numerical Methods and Across Scales, Precisions and Hardware Platforms”
Cleve Moler (MathWorks), “Computers That I Have Known”
Yves Robert (Ecole Normale Supérieure de Lyon), “25+ Years of Scheduling at ICL”
Françoise Tisseur (The University of Manchester), “Mixed Precision Tall and Thin QR Factorization with Applications”
David Keyes (King Abdullah University of Science and Technology), “Adaptive Nonlinear Preconditioning for PDEs with Error Bounds on Output Functionals”
Zhaojun Bai (University of California, Davis), “Many Eigenpair Computation Via Hotelling’S Deflation”,
Ilse Ipsen (North Carolina State University), “A Few Observations About Summation Algorithms”
Erich Strohmaier (TOP500), “TOP500 and Accidental Benchmarking”
Nick Higham (The University of Manchester), “Solving Dense Linear Systems: A Brief History and Future Directions ”
Jack Dongarra (University of Tennessee, Oak Ridge Laboratory and The University of Manchester), “Still Having Fun After 50 Years”,
The two-part minisymposium Bohemian Matrices and Applications, organized by Rob Corless and I, took place at the SIAM Annual Meeting, July 22 and 23, 2021. This page makes available slides from some of the talks.
The minisymposium followed a two-part minisymposium on Bohemian matrices at the 2019 ICIAM meeting in Valencia and a 3-day workshop on Bohemian matrices in Manchester in 2018.
Minisymposium description: Bohemian matrices are matrices with entries drawn from a fixed discrete set of small integers (or some other discrete set). The term is a contraction of BOunded HEight Matrix of Integers. Such matrices arise in many applications, and include graph incidence matrices and Bernoulli matrices. The questions of interest range from identifying structures in the spectra of particular classes of Bohemian matrix to searching for most ill conditioned matrices within a class, and applications include stress-testing algorithms and software. This minisymposium will report recent theoretical and computational progress as well as open questions.
Putting Skew-Symmetric Tridiagonal Bohemians on the Calendar. Robert M. Corless, Western University, Canada. Abstract. Rob did not use slides but gave his talk using this paper and this Maple worksheet.
Determinants of Normalized Bohemian Upper Hessenberg Matrices. Massimiliano Fasi, Örebro University, Sweden; Jishe Feng, Longdong University, China; Gian Maria Negri Porzio, University of Manchester, United Kingdom. Abstract. Slides.
Experiments on Upper Hessenberg and Toeplitz Bohemians. Eunice Chan, Western University, Canada. Abstract. Slides.
Eigenvalues of Magic Squares and Related Bohemian Matrices. Hariprasad Manjunath Hegde, Indian Institute of Science, Bengaluru, India. Abstract. Slides.
Calculating the 3D Kings Multiplicity Constant. Nicholas Cohen and Neil Calkin, Clemson University, U.S. Abstract. Slides.
Bohemian Inners Inverses: A First Step Toward Bohemian Generalized Inverses. Laureano Gonzalez-Vega, Universidad de Cantabria, Spain; Juan Rafael Sendra, Universidad Alcalá de Henares, Spain; Juana Sendra Pons, Universidad Politécnica de Madrid, Spain. Abstract. Slides.
Recent Progress in the Rational Factorisation of Integer Matrices. Matthew Lettington, Cardiff University, United Kingdom. Abstract. Slides.
Which Columns are Independent? Why does Row Rank = Column Rank? Gilbert Strang, Massachusetts Institute of Technology, U.S. Abstract. Slides.
Bohemian Matrices: the Symbolic Computation Approach. Juana Sendra, Universidad Autónoma de Madrid, Spain; Laureano González-Vega, Universidad de Estudios Financieros en Madrid, Spain; Juan Rafael Sendra, Universidad Alcalá de Henares, Spain. Abstract. Slides.
Minisymposium description: Reduced precision floating-point arithmetic, such as IEEE half precision and bfloat16, is increasingly available in hardware. Low precision computations promise major increases in speed and reductions in data communication costs, but they also bring an increased risk of overflow, underflow, and loss of accuracy. One way to improve the results of low precision computations is to use stochastic rounding instead of round to nearest, and this is proving popular in machine learning. This minisymposium will discuss recent advances in exploitation and analysis of reduced precision arithmetic and stochastic rounding.
Algorithms for Stochastically Rounded Elementary Arithmetic Operations in IEEE 754 Floating-Point Arithmetic Massimiliano Fasi, Örebro University, Sweden; Mantas Mikaitis, University of Manchester, United Kingdom. Abstract. Slides.
Reduced Precision Elementary FunctionsJean-Michel Muller, ENS Lyon, France. Abstract. Slides.
Effect of Reduced Precision and Stochastic Rounding in the Numerical Solution of Parabolic EquationsMatteo Croci and Michael B. Giles, University of Oxford, United Kingdom. Abstract. Slides.
Stochastic Rounding and its Probabilistic Backward Error AnalysisMichael P. Connolly and Nicholas J. Higham, University of Manchester, United Kingdom; Theo Mary, Sorbonne Universités and CNRS, France. Abstract. Slides.
Stochastic Rounding in Weather and Climate ModelsMilan Kloewer, Edmund Paxton, and Matthew Chantry, University of Oxford, United Kingdom Abstract. Slides.
In September 1984 a two-day Symposium on Computational Mathematics–State of the Art was held at Argonne National Laboratory in honour of James Hardy Wilkinson on his 65th birthday.
Wilkinson was one of the leading figures in 20th century numerical analysis. He developed the theory and practice of backward error analysis for floating-point computation, and developed, analyzed, and implemented in software many algorithms in numerical linear algebra. Among his many honours, Wilkinson was a Fellow of the Royal Society (elected 1969) and a winner of both the Turing Prize (1970) and the SIAM John von Neumman Lecture award (1970). His legacy endures and in 2019 we celebrated the centenary of his birth with the conference Advances in Numerical Linear Algebra.
The 1984 symposium provided “an overview of the state of the art in several of the major areas of computational mathematics” and “was particularly appropriate for this occasion in view of the many fundamental contributions in computational mathematics made by Professor Wilkinson throughout his distinguished career”.
The symposium attracted more than 260 attendees and comprised ten invited talks by distinguished researchers:
Some Problems in the Scaling of Matrices, G. W. Stewart
Matrix Calculations in Optimization Algorithms, M. J. D. Powell
Numerical Solution of Differential-Algebraic Equations, C. W. Gear
The Requirements of Interactive Data Analysis Systems, Peter J. Huber
Linear Algebra Problems in Multivariate Approximation Theory, C. de Boor
Computational linear Algebra in Continuation and Two Point Boundary Value Problems, H. B. Keller
Second Thoughts on the Mathematical Software Effort: A Perspective, W. J. Cody
Enhanced Resolution in Shock Wave Calculations, James Glimm
Jack Dongarra has provided me with contact prints of photos taken at the workshop. I have scanned some of these and they are shown below.
One of the photos shows Jim Wilkinson with an Apple Mac that was presented to him. He used it to type up several of his later papers. Sadly, Jim died just over two years after the symposium.
The Royal Society discussion meeting Numerical Algorithms for High-Performance Computational Science, which I organized with Jack Dongarra and Laura Grigori, was held in London, April 8-9, 2019. The meeting had 16 invited speakers and 23 contributed posters, with a poster blitz preceding the lively poster session.
The meeting brought together around 150 people who develop and implement numerical algorithms and software libraries—numerical analysts, computer scientists, and high-performance computing researchers—with those who use them in some of today’s most challenging applications. The aim was to discuss the challenges brought about by evolving computer architectures and the characteristics and requirements of applications, both to produce greater awareness of algorithms that are currently available or under development and to steer research on future algorithms.
Several key themes emerged across multiple talks, all in the context of today’s high performance computing landscape in which processor clock speeds have stagnated (with the end of Moore’s law) and exascale machine are just two or three years away.
An important way of accelerating computations is through the use of low precision floating-point arithmetic—in particular by exploiting a hierarchy of precisions.
We must exploit low rank matrix structure where it exists, for example in hierarchical (H-matrix) form, combining it with randomized approximations.
Minimizing data movement (communication) is crucial, because of its increasing costs relative to the costs of floating-point arithmetic.
Co-design (the collaborative and concurrent development of hardware, software, and numerical algorithms, with knowledge of applications) is increasingly important for numerical computing.
Applications treated included deep learning, climate modeling, computational biology, and the Square Kilometre Array (SKA) radio telescope project. We learned that the latter project needs faster FFTs in order to deal with the petabytes of data it will generate each year.
Papers from the meeting will be published in a future issue of Philosophical Transactions of the Royal Society A.
Here are the talks (in order of presentation), with links to the slides.
This year marks the 100th anniversary of the birth of James Hardy Wilkinson, FRS. Wilkinson developed the theory and practice of backward error analysis for floating-point computation, and developed, analyzed, and implemented in software many algorithms in numerical linear algebra. While much has changed since his untimely passing in 1986, we still rely on the analytic and algorithmic foundations laid by Wilkinson.
This micro website about Wilkinson, set up by Sven Hammarling and me, contains links to all kinds of information about Wilkinson, including audio and video recordings of him.
With Sven Hammarling and Françoise Tisseur, I am organizing a conference Advances in Numerical Linear Algebra: Celebrating the Centenary of the Birth of James H. Wilkinson at the University of Manchester, May 29-30, 2019. Among the 13 invited speakers are several who knew or worked with Wilkinson. As well as focusing on recent developments and future challenges for numerical linear algebra, the talks will include reminiscences about Wilkinson and discuss his legacy.
Contributed talks and posters are welcome (deadline April 1, 2019) and some funding is available to support the attendance of early career researchers and PhD students.
Bohemian matrices are families of matrices in which the entries are drawn from a fixed discrete set of small integers (or some other discrete set). The term is a contraction of BOunded HEight Matrix of Integers and was coined by Rob Corless and Steven Thornton of the University of Western Ontario. Such matrices arise in many situations:
adjacency matrices of graphs have entries from ;
Bernoulli matrices, which occur in compressed sensing, have entries from ;
Hadamard matrices have entries from and orthogonal columns; and
matrices with elements from provide worst case growth factors for Gaussian elimination with partial pivoting and yield the most ill conditioned triangular matrices with elements bounded by .
Rob’s group have done extensive computations of eigenvalues and characteristic polynomials of Bohemian matrices, which have led to interesting observations and conjectures. Many beautiful visualizations are collected on the website http://www.bohemianmatrices.com as well as on the Bohemian Matrices Twitter feed.
A density plot in the complex plane of the eigenvalues of a sample of 10 million 19×19 doubly companion matrices. Image credit: Steven Thornton].
In June 2018, Rob and I organized a 3-day workshop Bohemian Matrices and Applications, bringing together 16 people with an interest in the subject from a variety of backgrounds. The introductory talks by Rob, Steven, and I were videod (and are embedded below), and the slides from most of the talks are available on the conference website.
We scheduled plenty of time for discussion and working together. New collaborations were started, several open problems were solved and numerous new questions were posed.
The workshop has led to various strands of ongoing work. Steven has created the Characteristic Polynomial Database, which contains more than polynomials from more than Bohemian matrices and has led to a number of conjectures concerning matches of properties to sequences at the On-Line Encyclopedia of Integer Sequences. Three recent outputs are
E. Y. S. Chan, R. M. Corless, L. Gonzalez-Vega, J. R. Sendra, J. Sendra and S. E. Thornton, Bohemian Upper Hessenberg Matrices, ArXiv preprint arXiv:1809.10653, September 2018.
E. Y. S. Chan, R. M. Corless, L. Gonzalez-Vega, J. R. Sendra, J. Sendra and S. E. Thornton, Bohemian Upper Hessenberg Toeplitz Matrices, ArXiv preprint arXiv:1809.10664, September 2018.
Sponsorship of the workshop by the Heilbronn Institute for Mathematical Research, the Royal Society and the School of Mathematics at the University of Manchester, as well as support from Canada for some of the Canadian participants, is gratefully acknowledged.
At JuliaCon 2018 in London, one of the keynote presentations was a conversation with Gil Strang led by Alan Edelman and Pontus Stenetorp. Gil is well known for his many books on linear algebra, applied mathematics and numerical analysis, as well as his research contributions.
Gil talked about his famous 18.06 linear algebra course at MIT, which in its YouTube form has had almost 3 million views. A number of people in the audience commented that they had learned linear algebra from Gil.
Gil also talked about his book Linear Algebra and Learning from Data, due to be published at the end of 2018, which includes chapters on deep neural networks and back propagation. Many people will want to read Gil’s insightful slant on these topics (see also my SIAM News article The World’s Most Fundamental Matrix Equation).
As well as the video of Gil’s interview embedded below, two written interviews will be of interest to Gil’s fans:

 (
(







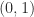 graph incidence matrices and
graph incidence matrices and 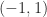 Bernoulli matrices. The questions of interest range from identifying structures in the spectra of particular classes of Bohemian matrix to searching for most ill conditioned matrices within a class, and applications include stress-testing algorithms and software. This minisymposium will report recent theoretical and computational progress as well as open questions.
Bernoulli matrices. The questions of interest range from identifying structures in the spectra of particular classes of Bohemian matrix to searching for most ill conditioned matrices within a class, and applications include stress-testing algorithms and software. This minisymposium will report recent theoretical and computational progress as well as open questions.










































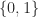 ;
;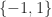 ;
; provide worst case growth factors for Gaussian elimination with partial pivoting and yield the most ill conditioned triangular matrices with elements bounded by
provide worst case growth factors for Gaussian elimination with partial pivoting and yield the most ill conditioned triangular matrices with elements bounded by  .
.
 polynomials from more than
polynomials from more than  Bohemian matrices and has led to a number of
Bohemian matrices and has led to a number of 




{kind=link}
{kind=link}
{kind=link}