The definition of matrix multiplication says that for  matrices
matrices  and
and  , the product
, the product  is given by
is given by  . Each element of
. Each element of  is an inner product of a row of and a column of , so if this formula is used then the cost of forming is
is an inner product of a row of and a column of , so if this formula is used then the cost of forming is  additions and multiplications, that is,
additions and multiplications, that is,  operations. For over a century after the development of matrix algebra in the 1850s by Cayley, Sylvester and others, all methods for matrix multiplication were based on this formula and required operations.
operations. For over a century after the development of matrix algebra in the 1850s by Cayley, Sylvester and others, all methods for matrix multiplication were based on this formula and required operations.
In 1969 Volker Strassen showed that when 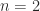 the product can be computed from the formulas
the product can be computed from the formulas

The evaluation requires 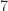 multiplications and
multiplications and 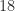 additions instead of
additions instead of  multiplications and
multiplications and  additions for the usual formulas.
additions for the usual formulas.
At first sight, Strassen’s formulas may appear simply to be a curiosity. However, the formulas do not rely on commutativity so are valid when the 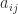 and
and  are matrices, in which case for large dimensions the saving of one multiplication greatly outweighs the extra
are matrices, in which case for large dimensions the saving of one multiplication greatly outweighs the extra 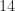 additions. Assuming
additions. Assuming  is a power of
is a power of  , we can partition and into four blocks of size
, we can partition and into four blocks of size 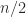 , apply Strassen’s formulas for the multiplication, and then apply the same formulas recursively on the half-sized matrix products.
, apply Strassen’s formulas for the multiplication, and then apply the same formulas recursively on the half-sized matrix products.
Let us examine the number of multiplications for the recursive Strassen algorithm. Denote by  the number of scalar multiplications required to multiply two
the number of scalar multiplications required to multiply two 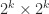 matrices. We have
matrices. We have 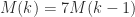 , so
, so

But 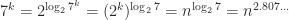 . The number of additions can be shown to be of the same order of magnitude, so the algorithm requires
. The number of additions can be shown to be of the same order of magnitude, so the algorithm requires 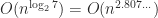 operations.
operations.
Strassen’s work sparked interest in finding matrix multiplication algorithms of even lower complexity. Since there are  elements of data, which must each participate in at least one operation, the exponent of in the operation count must be at least .
elements of data, which must each participate in at least one operation, the exponent of in the operation count must be at least .
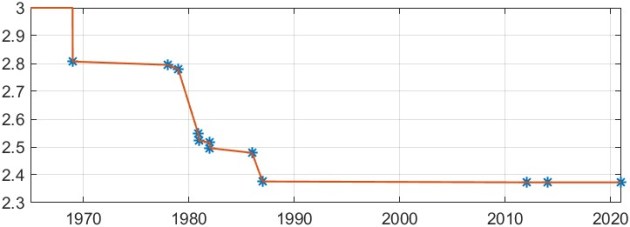
The current record upper bound on the exponent is 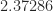 , proved by Alman and Vassilevska Williams (2021) which improved on the previous record of
, proved by Alman and Vassilevska Williams (2021) which improved on the previous record of 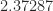 , proved by Le Gall (2014) The following figure plots the best upper bound for the exponent for matrix multiplication over time.
, proved by Le Gall (2014) The following figure plots the best upper bound for the exponent for matrix multiplication over time.
In the methods that achieve exponents lower than 2.775, various intricate techniques are used, based on representing matrix multiplication in terms of bilinear or trilinear forms and their representation as tensors having low rank. Laderman, Pan, and Sha (1993) explain that for these methods “very large overhead constants are hidden in the `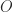 ‘ notation”, and that the methods “improve on Strassen’s (and even the classical) algorithm only for immense numbers
‘ notation”, and that the methods “improve on Strassen’s (and even the classical) algorithm only for immense numbers 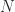 .”
.”
Strassen’s method, when carefully implemented, can be faster than conventional matrix multiplication for reasonable dimensions. In practice, one does not recur down to 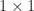 matrices, but rather uses conventional multiplication once
matrices, but rather uses conventional multiplication once  matrices are reached, where the parameter
matrices are reached, where the parameter 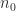 is tuned for the best performance.
is tuned for the best performance.
Strassen’s method has the drawback that it satisfies a weaker form of rounding error bound that conventional multiplication. For conventional multiplication of 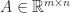 and
and  we have the componentwise bound
we have the componentwise bound

where 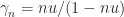 and
and  is the unit roundoff. For Strassen’s method we have only a normwise error bound. The following result uses the norm
is the unit roundoff. For Strassen’s method we have only a normwise error bound. The following result uses the norm 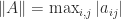 , which is not a consistent norm.
, which is not a consistent norm.
Theorem 1 (Brent). Let 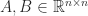 , where
, where 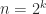 . Suppose that
. Suppose that 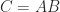 is computed by Strassen’s method and that
is computed by Strassen’s method and that 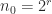 is the threshold at which conventional multiplication is used. The computed product
is the threshold at which conventional multiplication is used. The computed product 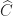 satisfies
satisfies
![\notag \|C - \widehat{C}\| \le \left[ \Bigl( \displaystyle\frac{n}{n_0} \Bigr)^{\log_2{12}} (n_0^2+5n_0) - 5n \right] u \|A\|\, \|B\| + O(u^2). \qquad(2)](https://s0.wp.com/latex.php?latex=%5Cnotag++++%5C%7CC+-+%5Cwidehat%7BC%7D%5C%7C+%5Cle+%5Cleft%5B+%5CBigl%28+%5Cdisplaystyle%5Cfrac%7Bn%7D%7Bn_0%7D+%5CBigr%29%5E%7B%5Clog_2%7B12%7D%7D+++++++++++++++++++++++%28n_0%5E2%2B5n_0%29+-+5n+%5Cright%5D+u+%5C%7CA%5C%7C%5C%2C+%5C%7CB%5C%7C+++++++++++++++++++++++%2B+O%28u%5E2%29.+%5Cqquad%282%29+&bg=ffffff&fg=222222&s=0&c=20201002)
With full recursion (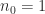 ) the constant in (2) is
) the constant in (2) is 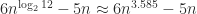 , whereas with just one level of recursion (
, whereas with just one level of recursion (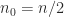 ) it is
) it is  . These compare with
. These compare with 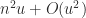 for conventional multiplication (obtained by taking norms in (1)). So the constant for Strassen’s method grows at a faster rate than that for conventional multiplication no matter what the choice of .
for conventional multiplication (obtained by taking norms in (1)). So the constant for Strassen’s method grows at a faster rate than that for conventional multiplication no matter what the choice of .
The fact that Strassen’s method does not satisfy a componentwise error bound is a significant weakness of the method. Indeed Strassen’s method cannot even accurately multiply by the identity matrix. The product
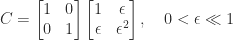
is evaluated exactly in floating-point arithmetic by conventional multiplication, but Strassen’s method computes

Because 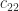 involves subterms of order unity, the error
involves subterms of order unity, the error 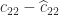 will be of order . Thus the relative error
will be of order . Thus the relative error  ,
,
Another weakness of Strassen’s method is that while the scaling  , where
, where  is diagonal, leaves (1) unchanged, it can alter (2) by an arbitrary amount. Dumitrescu (1998) suggests computing
is diagonal, leaves (1) unchanged, it can alter (2) by an arbitrary amount. Dumitrescu (1998) suggests computing 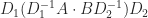 , where the diagonal matrices
, where the diagonal matrices 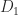 and
and  are chosen to equilibrate the rows of and the columns of in the
are chosen to equilibrate the rows of and the columns of in the  -norm; he shows that this scaling can improve the accuracy of the result. Further investigations along these lines are made by Ballard et al. (2016).
-norm; he shows that this scaling can improve the accuracy of the result. Further investigations along these lines are made by Ballard et al. (2016).
Should one use Strassen’s method in practice, assuming that an implementation is available that is faster than conventional multiplication? Not if one needs a componentwise error bound, which ensures accurate products of matrices with nonnegative entries and ensures that the column scaling of and row scaling of has no effect on the error. But if a normwise error bound with a faster growing constant than for conventional multiplication is acceptable then the method is worth considering.
Notes
For recent work on high-performance implementation of Strassen’s method see Huang et al. (2016, 2020).
Theorem 1 is from an unpublished technical report of Brent (1970). A proof can be found in Higham (2002, §23.2.2).
For more on fast matrix multiplication see Bini (2014) and Higham (2002, Chapter 23).
References
This is a minimal set of references, which contain further useful references within.
- Josh Alman and Virginia Vassilevska Williams. A refined laser method and faster matrix multiplication. In Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms (SODA), Society for Industrial and Applied Mathematics, January 2021, pages 522–539.
- Grey Ballard, Austin R. Benson, Alex Druinsky, Benjamin Lipshitz, and Oded Schwartz. Improving the numerical stability of fast matrix multiplication. SIAM J. Matrix Anal. Appl, 37(4):1382–1418, 2016.
- Benson, Alex Druinsky, Benjamin Lipshitz, and Oded Schwartz. Improving the numerical stability of fast matrix multiplication. SIAM J. Matrix Anal. Appl., 37(4):1382–1418, 2016.
- Dario A. Bini. Fast matrix multiplication. In Handbook of Linear Algebra, Leslie Hogben, editor, second edition, Chapman and Hall/CRC, Boca Raton, FL, USA, 2014, pages 61.1–61.17.
- Bogdan Dumitrescu. Improving and estimating the accuracy of Strassen’s algorithm. Numer. Math., 79:485–499, 1998.
- Nicholas J. Higham, Accuracy and Stability of Numerical Algorithms, second edition, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2002.
- Jianyu Huang, Tyler M. Smith, Greg M. Henry, and Robert A. van de Geijn. Strassen’s algorithm reloaded. In SC16: International Conference for High Performance Computing, Networking, Storage and Analysis, IEEE, November 2016.
- Jianyu Huang, Chenhan D. Yu, and Robert A. van de Geijn. Strassen’s algorithm reloaded on GPUs, ACM Trans. Math. Software, 46(1):1:1–1:22, 2020.
- Julian Laderman, Victor Pan, and Xuan-He Sha. On practical algorithms for accelerated matrix multiplication. Linear Algebra Appl., 162–164:557–588, 1992.
- François Le Gall. Powers of tensors and fast matrix multiplication. In Proceedings of the 39th International Symposium on Symbolic and Algebraic Computation, 2014, pages 296–303.
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.

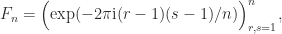
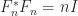
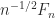
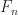
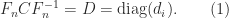
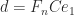
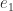
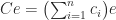

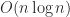
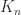

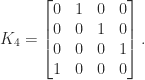
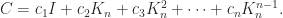


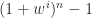



 (
(



{kind=link}
{kind=link}
{kind=link}