In numerical linear algebra we are concerned with solving linear algebra problems accurately and efficiently and understanding the sensitivity of the problems to perturbations. We describe seven sins, whereby accuracy or efficiency is lost or misleading information about sensitivity is obtained.
1. Inverting a Matrix
In linear algebra courses we learn that the solution to a linear system 






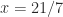


Rare cases where
2. Forming the Cross-Product Matrix A^TA
The solution to the linear least squares problem 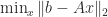
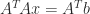
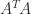
What is wrong with the cross-product matrix
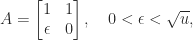
where 

is positive definite but, since 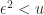


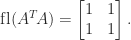
which is singular, and the information in 
Another problem with the cross product matrix is that the 
3. Evaluating Matrix Products in an Inefficient Order
The cost of evaluating a matrix product depends on the order in which the product is evaluated (assuming the matrices are not all 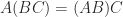




: a vector outer product followed by a matrix–vector product, costing
operations, or
: a vector scalar product followed by a vector scaling, costing just
operations.
In general. finding where to put the parentheses in a matrix product 
4. Assuming that a Matrix is Positive Definite
Symmetric positive definite matrices (symmetric matrices with positive eigenvalues) are ubiquitous, not least because they arise in the solution of many minimization problems. However, a matrix that is supposed to be positive definite may fail to be so for a variety of reasons. Missing or inconsistent data in forming a covariance matrix or a correlation matrix can cause a loss of definiteness, and rounding errors can cause a tiny positive eigenvalue to go negative.
Definiteness implies that
- the diagonal entries are positive,
,
for all
,
but none of these conditions, or even all taken together, guarantees that the matrix has positive eigenvalues.
The best way to check definiteness is to compute a Cholesky factorization, which is often needed anyway. The MATLAB function chol returns an error message if the factorization fails, and a second output argument can be requested, which is set to the number of the stage on which the factorization failed, or to zero if the factorization succeeded. In the case of failure, the partially computed 
This sin takes the top spot in Schmelzer and Hauser’s Seven Sins in Portfolio Optimization, because in portfolio optimization a negative eigenvalue in the covariance matrix can identify a portfolio with negative variance, promising an arbitrarily large investment with no risk!
5. Not Exploiting Structure in the Matrix
One of the fundamental tenets of numerical linear algebra is that one should try to exploit any matrix structure that might be present. Sparsity (a matrix having a large number of zeros) is particularly important to exploit, since algorithms intended for dense matrices may be impractical for sparse matrices because of extensive fill-in (zeros becoming nonzero). Here are two examples of structures that can be exploited.
Matrices from saddle point problems are symmetric indefinite and of the form

with 


Circulant matrices have the important property that they are diagonalized by a unitary matrix called the discrete Fourier transform matrix. Using this property one can solve 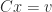


Ideally, linear algebra software would detect structure in a matrix and call an algorithm that exploits that structure. A notable example of such a meta-algorithm is the MATLAB backslash function x = A\b for solving
6. Using the Determinant to Detect Near Singularity
An 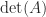
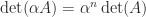

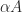

Another limitation of the determinant is shown by the two matrices
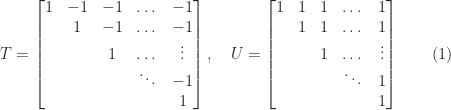
Both matrices have unit diagonal and off-diagonal elements bounded in modulus by 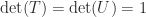
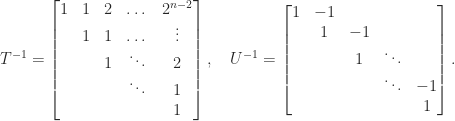
So 
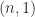


7. Using Eigenvalues to Estimate Conditioning
For any 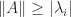





But as the matrix
It is singular values not eigenvalues that characterize the condition number for the 2-norm. Specifically,

where 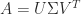

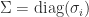
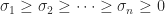
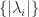
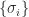
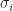

Computing eigenvalues by evaluating the roots of the characteristic polynomial ?