According to the WordPress statistics, this blog received over 39,000 visitors and 65,000 views in 2019. These are the five most-viewed posts published during the year.

According to the WordPress statistics, this blog received over 39,000 visitors and 65,000 views in 2019. These are the five most-viewed posts published during the year.

As well as allowing all the customizations I could possibly need, enumitem has two very useful built-in options. By default, nosep option, used as in
\begin{itemize}[nosep]
...
\end{itemize}
(and similarly for enumerate) removes vertical spaces in the list. The wide option, used as in
\begin{itemize}[wide]
...
\end{itemize}
produces lists whose entries have zero indentation on the second and subsequent lines. Both options save space and look better to my eye, especially for a book. They can be combined by specifying [wide,nosep].
An example of a customization possible with enumitem is
\begin{enumerate}[label=X\arabic*.,ref=X\arabic*]
\item\label{item1}
...
\end{enumerate}
This enumerated list has labels X1, X2, etc., and a reference such as “see \ref{item1}" reproduces the label: “see X1”.
Description environments can also be customized (I use these very little).

For examples of the above customizations see the LaTeX file and PDF output (shown to the right) in my enumitem_demo repository on GitHub.
These examples barely scratch the surface of the customizations that enumitem makes possible. Consult the manual for full details.
For guidance on how to punctuate lists see Handbook of Writing for the Mathematical Sciences (section 3.26) or my blog post Punctuating Lists.

I have several dictionaries on my shelf, among which is a well-thumbed Collins English Dictionary (third edition, 1991). Earlier this year I acquired the thirteenth edition (2018). At 26.5cm high, 20cm wide, and 6.5cm deep, and weighing approximately 2.5kg, it’s an imposing tome. It’s printed on thin paper with minimal show-through and in a specially designed font (Collins Fedra) that is very legible.
The thirteenth edition, which I will abbreviate to CED13, is a wonderful acquisition for any dictionary lover. It has a wide coverage, including
It has no appendices on English usage, mathematical symbols, chemical elements, etc., as are found in many dictionaries—which is fine with me as I rarely use them.
I decided to take a close look at some of the mathematical words in the CED.
“determinant n maths: a square array of elements that represents the sum of certain products of these elements, used to solve simultaneous equations, in vector studies, etc.”
This definition has two problems. First, a determinant is the sum, not something that represents the sum. Of, course, one will find in some textbooks statements such as “swapping two rows of a determinant changes its sign”, but it’s odd that this informal usage of determinant as array is the only one mentioned. A second problem is that the determinant is not a sum of products: it is a signed sum of products and it is the permanent (not in this dictionary) that is obtained by taking all positive signs.
“matrix n maths a rectangular array of elements set out in rows and columns, used to facilitate the solution of problems, such as transformation of coordinates.”
A matrix is more than just an array: its key characteristic is that it has algebraic operations defined on it.
“rounding: n computing a process in which a number is approximated as the closest number that can be expressed using the number of bits or digits available.”
Rounding is not specifically a computing term—it’s more fundamentally a mathematical operation and predates computing. Bits are special cases of digits. And rounding does not have to be to the closest number: in some situations once needs to round to the next larger or smaller number.
“index n maths c a subscript or superscript to the right of a variable to express a set of variables, as in using 
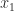
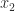

An index does not (except maybe in informal usage) express a set, but rather identifies a member of a set.
“supercomputer n a powerful computer that can process large quantities of data of a similar type very quickly.”
Supercomputers do mathematical calculations (and are ranked on their speed in doing so), which is not apparent from this definition. I’m also not sure why “of a similar type” is necessary. The PC on which I am typing is a supercomputer according to this definition!
“integral n maths the limit of an increasingly large number of increasingly smaller quantities, related to the function that is being integrated (the integrand). The independent variables may be confined within certain limits (definite integral) or in the absence of limits (indefinite integral).”
This seems to be an attempt to state informally the Riemann sum definition of definite integration. Sadly, it’s technically incomplete and sure to baffle anyone who doesn’t already know about Riemann sums. It would have been much better to simply say that integration is the inverse of differentiation. The second sentence is grammatically incorrect.
“fractal maths n a figure or surface generated by successive subdivisions of a simpler polygon or polyhedron, according to some iterative process.”
Surely any definition should mention fractional dimension and self-similarity? This definition excludes the fractal that is the boundary of the Mandelbrot set.
I’m not too surprised by these weaknesses, because in 1994 I wrote an article Which Dictionary for the Mathematical Scientist? (PDF file here) in which I evaluated several dictionaries (including CED3) from the point of view of their mathematical words and found problems such as those above in several of them.
Despite these criticisms, I very much like this dictionary and I use it as much as the other dictionaries on my desk. It is especially good on the computing side. I was pleased to see that my favourite editor, emacs, is included (though I’m not sure why it is not capitalized). Vi users will be sad to hear that Vi is not included. A good number of programming languages are present, including awk (uncapitalized), Java, and Javascript, but not, C++ (how would that be alphabetized?), Python, or R.
A particularly notable definition is
“flops or FLOPS n acronym for floating-point operations per second: used as a measure of computer processing power (in combination with a prefix): megaflops; gigaflops.”
This is much better than the Oxford English Dictionary’s definition of the singular flop as “a floating-point operation per second”. There are also entries for petaflop, “

