
The third edition of Handbook of Writing for the Mathematical Sciences was published by SIAM in January 2020. It is SIAM’s fourth best selling book of all time if sales for the first edition (1993) and second edition (1998) are combined, and it is in my top ten most cited outputs. As well as being used by individuals from students to faculty, it is a course text on transferable skills modules in many mathematics departments. A number of publishers cite the book as a reference for recommended style—see, for example, the AMS Author Handbook, the SIAM Style Manual and, outside mathematics and computing, the Chicago Manual of Style.
Parts of the second edition were becoming out of date, as they didn’t reflect recent developments in publishing (open access publishing, DOIs, ORCID, etc.) or workflow (including modern LaTeX packages, version control, and markup languages). I’ve also learned a lot more about writing over the last twenty years.
I made a variety of improvements for the third edition. I reorganized the material in a way that is more logical and makes the book easier to use for reference. I also improved the design and formatting and checked and updated all the references.
I removed content that was outdated or is now unnecessary. For example, nowadays there is no need to talk about submitting a hard copy manuscript, or one not written in LaTeX, to a publisher. I removed the 20-page appendix Winners of Prizes for Expository Writing, since the contents can now be found on the web, and likewise for the appendix listing addresses of mathematical organizations.
I also added a substantial amount of new material. Here are some of the more notable changes.

- A new chapter Workflow discusses how to organize and automate the many tasks involved in writing. With the increased role of computers in writing and the volume of digital material we produce it is important that we make efficient use of text editors, markup languages, tools for manipulating plain text, spellcheckers, version control, and much more.
- The chapter on
has been greatly expanded, reflecting both the many new and useful packages and my improved knowledge of typesetting.
- I used the enumitem
- I wrote a new chapter on indexing at the same time as I was reading the literature on indexing and making an improved index for the book. Indexing is an interesting task, but most of us do it only occasionally so it is hard to become proficient. This is my best index yet, and the indexing chapter explains pretty much everything I’ve learned abut the topic.
- Since the second edition I have changed my mind about how to typeset tables. I am now a convert to minimizing the use of rules and to using the booktabs
- The chapter Writing a Talk now illustrates the use of the Beamer
- The book uses color for syntax highlighted
- Sidebars in gray boxes give brief diversions on topics related to the text, including several on “Publication Peculiarities”.
- An expanded chapter English Usage includes new sections on Zombie Nouns; Double Negatives; Serial, or Oxford, Comma; and Split Infinitives.
- There are new chapters on Writing a Blog Post; Refereeing and Reviewing; Writing a Book; and, as discussed above, Preparing an Index and Workflow.
- The bibliography now uses the backref
- As well as updating the bibliography I have added DOIs and URL links, which can be found in the online version of the bibliography in bbl and PDF form, which is available from the book’s website.
At 353 pages, and allowing for the appendices removed and the more efficient formatting, the third edition is over 30 percent longer than the second edition.
As always, working with the SIAM staff on the book was a pleasure. A special thanks goes to Sam Clark of T&T Productions, who copy edited the book. Sam, with whom I have worked on two previous book projects, not only edited for SIAM style but found a large number of improvements to the text and showed me some things I did not know about
SIAM News has published an interview with me about the book and mathematical writing and publishing.
Here is a word cloud for the book, generated in MATLAB using the wordcloud function, based on words of 6 or more characters. 
 -vector
-vector  and returns a vector
and returns a vector 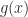 with elements
with elements
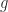 are all between
are all between  and
and  and they sum to 1, so
and they sum to 1, so 
 of the vector
of the vector  and
and  .
. because of the exponentials, even though
because of the exponentials, even though 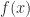 is very unlikely to do so.
is very unlikely to do so. , and use the formulas
, and use the formulas

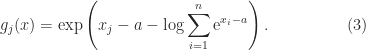
 ? Second, in (1) and (3),
? Second, in (1) and (3),  is negative can there be damaging subtractive cancellation?
is negative can there be damaging subtractive cancellation?
