In this post I discuss some of the new features in MATLAB R2022a, focusing on ones that relate to my particular interests. See the release notes for a detailed list of the many changes in MATLAB and its toolboxes. For my articles about new features in earlier releases, see here.
Themes
MATLAB Online now has themes, including a dark theme (which is my preference). We will have to wait for a future release for themes to be supported on desktop MATLAB.
I recall that @nhigham was asking for this. Currently @MATLAB Online only at the moment though. Desktop MATLAB isn’t there yet
— Mike Croucher (@walkingrandomly) March 11, 2022
Economy Factorizations
One can now write qr(A,'econ') instead of qr(A,0) and gsvd(A,B,'econ') instead of gsvd(A,B) for the “economy size” decompositions. This is useful as the 'econ' form is more descriptive. The svd function already supported the 'econ' argument. The economy-size QR factorization is sometimes called the thin QR factorization.
Tie Breaking in the round Function
The round function, which rounds to the nearest integer, now breaks ties by rounding away from zero by default and has several other tie-breaking options (albeit not stochastic rounding). See a sequence of four blog posts on this topic by Cleve Moler starting with this one from February 2021.
Tolerances for null and orth
The null (nullspace) and orth (orthonormal basis for the range) functions now accept a tolerance as a second argument, and any singular values less than that tolerance are treated as zero. The default tolerance is max(size(A)) * eps(norm(A)). This change brings the two functions into line with rank, which already accepted the tolerance. If you are working in double precision (the MATLAB default) and your matrix has inherent errors of order 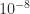
Unit Testing Reports
The unit testing framework can now generate docx, html, and pdf reports after test execution, by using the function generatePDFReport in the latter case. This is useful for keeping a record of test results and for printing them. We use unit testing in Anymatrix and have now added an option to return the results in a variable so that the user can call one of these new functions.
Checking Arrays for Special Values
Previously, if you wanted to check whether a matrix had all finite values you would need to use a construction such as all(all(isfinite(A))) or all(isfinite(A),'all'). The new allfinite function does this in one go: allfinite(A) returns true or false according as all the elements of A are finite or not, and it works for arrays of any dimension.
Similarly, anynan and anymissing check for NaNs or missing values. A missing value is a NaN for numerical arrays, but is indicated in other ways for other data types.
Linear Algebra on Multidimensional Arrays
The new pagemldivide, pagemrdivide, and pageinv functions solve linear equations and calculate matrix inverses using pages of 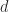
tensorprod calculates tensor products (inner products, outer products, or a combination of the two) between two
Animated GIFs
The append option of the exportgraphics function now supports the GIF format, enabling one to create animated GIFs (previously only multipage PDF files were supported). The key command is exportgraphics(gca,file_name,"Append",true). There are other ways of creating animated GIFs in MATLAB, but this one is particularly easy. Here is an example M-file (based on cheb3plot in MATLAB Guide) with its output below.
%CHEB_GIF Animated GIF of Chebyshev polynomials.
% Based on cheb3plot in MATLAB Guide.
x = linspace(-1,1,1500)';
p = 49
Y = ones(length(x),p);
Y(:,2) = x;
for k = 3:p
Y(:,k) = 2*x.*Y(:,k-1) - Y(:,k-2);
end
delete cheby_animated.gif
a = get(groot,'defaultAxesColorOrder'); m = length(a);
for j = 1:p-1 % length(k)
plot(x,Y(:,j),'LineWidth',1.5,'color',a(1+mod(j-1,m),:));
xlim([-1 1]), ylim([-1 1]) % Must freeze axes.
title(sprintf('%2.0f', j),'FontWeight','normal')
exportgraphics(gca,"cheby_animated.gif","Append",true)
end

 ?
?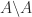 returns. I will summarize what backslash does in general, for
returns. I will summarize what backslash does in general, for 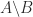 and then consider the case
and then consider the case 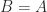 .
.
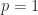 , because backslash treats the columns independently, and we write this as
, because backslash treats the columns independently, and we write this as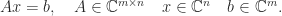
 and whether it is rank deficient.
and whether it is rank deficient.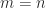
 , computed by LU factorization with partial pivoting (and of course without forming
, computed by LU factorization with partial pivoting (and of course without forming  ). There is no special treatment for singular matrices, so for them division by zero may occur and the output may contain NaNs (in practice, what happens will usually depend on the rounding errors). For example:
). There is no special treatment for singular matrices, so for them division by zero may occur and the output may contain NaNs (in practice, what happens will usually depend on the rounding errors). For example: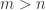
 nonzeros. Such a solution is not, in general, unique.
nonzeros. Such a solution is not, in general, unique.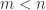
 produces a basic solution and in the former case a basic LS solution. Example:
produces a basic solution and in the former case a basic LS solution. Example:![[0~2~1]^T](https://s0.wp.com/latex.php?latex=%5B0%7E2%7E1%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002) , and the minimum
, and the minimum  -norm solution is
-norm solution is ![[1~1~1]^T](https://s0.wp.com/latex.php?latex=%5B1%7E1%7E1%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002) .
. . If
. If 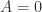 then
then  is not a basic solution, so
is not a basic solution, so  ; in fact,
; in fact, 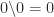 if
if 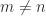 and it is matrix of NaNs if
and it is matrix of NaNs if  in the most efficient way, using LU factorization (
in the most efficient way, using LU factorization (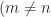 ). Often, one wants the solution of minimum
). Often, one wants the solution of minimum 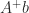 , where
, where 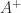 is the pseudoinverse of
is the pseudoinverse of  ,
, 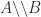 . Then
. Then  , which is the orthogonal projector onto
, which is the orthogonal projector onto  , and it is equal to the identity matrix when
, and it is equal to the identity matrix when 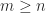 and
and 
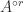 is positive semidefinite for all
is positive semidefinite for all 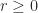 , where
, where  is the Hadamard power. We verify this property for
is the Hadamard power. We verify this property for 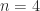 and
and 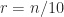 by checking that the eigenvalues are nonnegative:
by checking that the eigenvalues are nonnegative: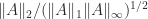 over all the matrices, with default input arguments and size
over all the matrices, with default input arguments and size  if the dimension is variable. This ratio is known to lie between
if the dimension is variable. This ratio is known to lie between  and
and  . We note several features of the code.
. We note several features of the code. matrix designed by
matrix designed by  of a low rank approximation to a matrix (
of a low rank approximation to a matrix ( and
and  orthogonal,
orthogonal,  diagonal with nonnegative diagonal entries). It is mainly intended for use with matrices that are close to having low rank, as is the case in various applications.
diagonal with nonnegative diagonal entries). It is mainly intended for use with matrices that are close to having low rank, as is the case in various applications.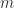 -by-
-by- matrix
matrix 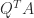 , where
, where  is an orthonormal basis for the product
is an orthonormal basis for the product  , where
, where 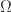 is a random
is a random  matrix. The value of
matrix. The value of  , where
, where 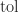 is a tolerance that defaults to
is a tolerance that defaults to 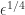 and must not be less than
and must not be less than 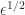 , where
, where  is the machine epsilon (
is the machine epsilon (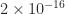 for double precision). The algorithm includes a power method iteration that refines the sketch before computing the SVD.
for double precision). The algorithm includes a power method iteration that refines the sketch before computing the SVD. , which is more than the
, which is more than the 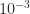 requested. This is a difficult matrix for
requested. This is a difficult matrix for 




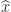 satisfies
satisfies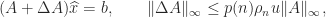
 is the unit roundoff and
is the unit roundoff and  is a low degree polynomial. The term
is a low degree polynomial. The term 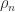 is the growth factor, defined by
is the growth factor, defined by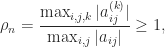
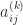 are the elements at the
are the elements at the  to be of order 1, so that
to be of order 1, so that 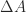 is a small relative perturbation of
is a small relative perturbation of  and that equality is possible. Such exponential growth implies a large
and that equality is possible. Such exponential growth implies a large 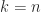 in the numerator in the definition), but it is entirely adequate for our purposes here. Let’s compute the growth factor for a random matrix of order 10,000 with elements from the standard normal distribution (mean 0, variance 1):
in the numerator in the definition), but it is entirely adequate for our purposes here. Let’s compute the growth factor for a random matrix of order 10,000 with elements from the standard normal distribution (mean 0, variance 1): times and 1e-6. Growth of 975 is exceptional! These matrices have been in MATLAB since the 1990s, but this large growth property has apparently not been noticed before.
times and 1e-6. Growth of 975 is exceptional! These matrices have been in MATLAB since the 1990s, but this large growth property has apparently not been noticed before. for any condition number and for any pivoting strategy, not just partial pivoting. One way to check this is to randomly permute the columns of
for any condition number and for any pivoting strategy, not just partial pivoting. One way to check this is to randomly permute the columns of 
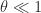 , then
, then 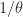 for any pivoting strategy. This was proved by Des Higham and I in the paper
for any pivoting strategy. This was proved by Des Higham and I in the paper 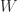 is an orthogonal matrix generating large growth then a rank-1 perturbation of 2-norm at most 1 tends to preserve the large growth.
is an orthogonal matrix generating large growth then a rank-1 perturbation of 2-norm at most 1 tends to preserve the large growth. . If we work in single precision then
. If we work in single precision then  and so LU factorization can potentially be completely unstable if there is growth of order
and so LU factorization can potentially be completely unstable if there is growth of order  . It was overflow in half precision LU factorization on randsvd matrices that alerted us to the large growth.
. It was overflow in half precision LU factorization on randsvd matrices that alerted us to the large growth.
 .
. floating-point operations, each of which needs to be chopped. The following code uses only
floating-point operations, each of which needs to be chopped. The following code uses only  calls to
calls to 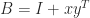 , for unit norm
, for unit norm  and
and  . The matrix
. The matrix 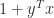 . The matrix is singular—and hence has a zero singular value—precisely when
. The matrix is singular—and hence has a zero singular value—precisely when 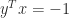 , which is the smallest value that the inner product
, which is the smallest value that the inner product 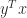 can take.
can take.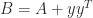 , where
, where 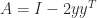 and
and 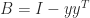 is singular with null vector
is singular with null vector 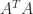 , which is the identity plus a rank-
, which is the identity plus a rank-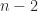 singular values remain at 1.
singular values remain at 1. and
and 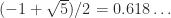 respectively! As our example shows,
respectively! As our example shows,  to be unit-norm random vectors with independent entries from the same distribution.
to be unit-norm random vectors with independent entries from the same distribution.
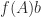 and for arbitrary precision evaluation of the exponential and logarithm.
and for arbitrary precision evaluation of the exponential and logarithm.