A real  matrix
matrix  is symmetric positive definite if it is symmetric ( is equal to its transpose,
is symmetric positive definite if it is symmetric ( is equal to its transpose, 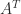 ) and
) and
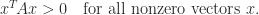
By making particular choices of  in this definition we can derive the inequalities
in this definition we can derive the inequalities

Satisfying these inequalities is not sufficient for positive definiteness. For example, the matrix
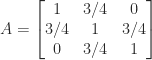
satisfies all the inequalities but 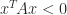 for
for ![x = [1,{}-\!\sqrt{2},~1]^T](https://s0.wp.com/latex.php?latex=x+%3D+%5B1%2C%7B%7D-%5C%21%5Csqrt%7B2%7D%2C%7E1%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002) .
.
A sufficient condition for a symmetric matrix to be positive definite is that it has positive diagonal elements and is diagonally dominant, that is, 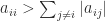 for all
for all  .
.
The definition requires the positivity of the quadratic form  . Sometimes this condition can be confirmed from the definition of . For example, if
. Sometimes this condition can be confirmed from the definition of . For example, if 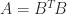 and
and  has linearly independent columns then
has linearly independent columns then  for
for 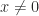 . Generally, though, this condition is not easy to check.
. Generally, though, this condition is not easy to check.
Two equivalent conditions to being symmetric positive definite are
- every leading principal minor
 , where the submatrix
, where the submatrix  comprises the intersection of rows and columns
comprises the intersection of rows and columns  to
to  , is positive,
, is positive,
- the eigenvalues of are all positive.
The first condition implies, in particular, that 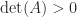 , which also follows from the second condition since the determinant is the product of the eigenvalues.
, which also follows from the second condition since the determinant is the product of the eigenvalues.
Here are some other important properties of symmetric positive definite matrices.
 is positive definite.
is positive definite.- has a unique symmetric positive definite square root
 , where a square root is a matrix such that
, where a square root is a matrix such that 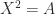 .
.
- has a unique Cholesky factorization
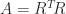 , where
, where  is upper triangular with positive diagonal elements.
is upper triangular with positive diagonal elements.
Sources of positive definite matrices include statistics, since nonsingular correlation matrices and covariance matrices are symmetric positive definite, and finite element and finite difference discretizations of differential equations.
Examples of symmetric positive definite matrices, of which we display only the  instances, are the Hilbert matrix
instances, are the Hilbert matrix
![H_4 = \left[\begin{array}{@{\mskip 5mu}c*{3}{@{\mskip 15mu} c}@{\mskip 5mu}} 1 & \frac{1}{2} & \frac{1}{3} & \frac{1}{4} \\[6pt] \frac{1}{2} & \frac{1}{3} & \frac{1}{4} & \frac{1}{5}\\[6pt] \frac{1}{3} & \frac{1}{4} & \frac{1}{5} & \frac{1}{6}\\[6pt] \frac{1}{4} & \frac{1}{5} & \frac{1}{6} & \frac{1}{7}\\[6pt] \end{array}\right],](https://s0.wp.com/latex.php?latex=H_4+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip+5mu%7Dc%2A%7B3%7D%7B%40%7B%5Cmskip+15mu%7D+c%7D%40%7B%5Cmskip+5mu%7D%7D+++++++++++++1+%26+%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B1%7D%7B3%7D++%26+%5Cfrac%7B1%7D%7B4%7D++%5C%5C%5B6pt%5D++++++++++++%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B1%7D%7B3%7D+++%26+%5Cfrac%7B1%7D%7B4%7D+++%26+%5Cfrac%7B1%7D%7B5%7D%5C%5C%5B6pt%5D++++++++++++%5Cfrac%7B1%7D%7B3%7D+%26+%5Cfrac%7B1%7D%7B4%7D+++%26++++++%5Cfrac%7B1%7D%7B5%7D+++%26+%5Cfrac%7B1%7D%7B6%7D%5C%5C%5B6pt%5D++++++++++++%5Cfrac%7B1%7D%7B4%7D+%26+%5Cfrac%7B1%7D%7B5%7D+++%26++++++%5Cfrac%7B1%7D%7B6%7D+++%26+%5Cfrac%7B1%7D%7B7%7D%5C%5C%5B6pt%5D++++++++++++%5Cend%7Barray%7D%5Cright%5D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
the Pascal matrix
![P_4 = \left[\begin{array}{@{\mskip 5mu}c*{3}{@{\mskip 15mu} r}@{\mskip 5mu}} 1 & 1 & 1 & 1\\ 1 & 2 & 3 & 4\\ 1 & 3 & 6 & 10\\ 1 & 4 & 10 & 20 \end{array}\right],](https://s0.wp.com/latex.php?latex=P_4+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip+5mu%7Dc%2A%7B3%7D%7B%40%7B%5Cmskip+15mu%7D+r%7D%40%7B%5Cmskip+5mu%7D%7D++++++1+%26++++1++%26+++1++%26+++1%5C%5C++++++1+%26++++2++%26+++3++%26+++4%5C%5C++++++1+%26++++3++%26+++6++%26++10%5C%5C++++++1+%26++++4++%26++10++%26++20++++++++++++%5Cend%7Barray%7D%5Cright%5D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
and minus the second difference matrix, which is the tridiagonal matrix
![S_4 = \left[\begin{array}{@{\mskip 5mu}c*{3}{@{\mskip 15mu} r}@{\mskip 5mu}} 2 & -1 & & \\ -1 & 2 & -1 & \\ & -1 & 2 & -1 \\ & & -1 & 2 \end{array}\right].](https://s0.wp.com/latex.php?latex=S_4+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip+5mu%7Dc%2A%7B3%7D%7B%40%7B%5Cmskip+15mu%7D+r%7D%40%7B%5Cmskip+5mu%7D%7D++++++2+%26+++-1++%26++++++%26++++%5C%5C+++++-1+%26++++2++%26++-1++%26++++%5C%5C++++++++%26++++-1+%26+++2++%26++-1+%5C%5C++++++++%26+++++++%26++-1++%26++2++++++++++++%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
All three of these matrices have the property that 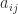 is non-decreasing along the diagonals. However, if is positive definite then so is
is non-decreasing along the diagonals. However, if is positive definite then so is 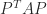 for any permutation matrix
for any permutation matrix  , so any symmetric reordering of the row or columns is possible without changing the definiteness.
, so any symmetric reordering of the row or columns is possible without changing the definiteness.
A symmetric positive definite matrix that was often used as a test matrix in the early days of digital computing is the Wilson matrix

What is the best way to test numerically whether a symmetric matrix is positive definite? Computing the eigenvalues and checking their positivity is reliable, but slow. The fastest method is to attempt to compute a Cholesky factorization and declare the matrix positivite definite if the factorization succeeds. This is a reliable test even in floating-point arithmetic. If the matrix is not positive definite the factorization typically breaks down in the early stages so and gives a quick negative answer.
Symmetric block matrices

often appear in applications. If is nonsingular then we can write
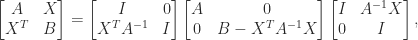
which shows that  is congruent to a block diagonal matrix, which is positive definite when its diagonal blocks are. It follows that is positive definite if and only if both and
is congruent to a block diagonal matrix, which is positive definite when its diagonal blocks are. It follows that is positive definite if and only if both and 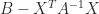 are positive definite. The matrix is called the Schur complement of in .
are positive definite. The matrix is called the Schur complement of in .
We mention two determinantal inequalities. If the block matrix above is positive definite then  (Fischer’s inequality). Applying this inequality recursively gives Hadamard’s inequality for a symmetric positive definite :
(Fischer’s inequality). Applying this inequality recursively gives Hadamard’s inequality for a symmetric positive definite :
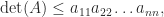
with equality if and only if is diagonal.
Finally, we note that if 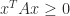 for all
for all 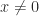 , so that the quadratic form is allowed to be zero, then the symmetric matrix is called symmetric positive semidefinite. Some, but not all, of the properties above generalize in a natural way. An important difference is that semidefinitness is equivalent to all principal minors, of which there are
, so that the quadratic form is allowed to be zero, then the symmetric matrix is called symmetric positive semidefinite. Some, but not all, of the properties above generalize in a natural way. An important difference is that semidefinitness is equivalent to all principal minors, of which there are  , being nonnegative; it is not enough to check the
, being nonnegative; it is not enough to check the  leading principal minors. Consider, as an example, the matrix
leading principal minors. Consider, as an example, the matrix

which has leading principal minors ,  , and and a negative eigenvalue.
, and and a negative eigenvalue.
A complex matrix is Hermitian positive definite if it is Hermitian ( is equal to its conjugate transpose, 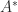 ) and
) and 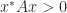 for all nonzero vectors . Everything we have said above generalizes to the complex case.
for all nonzero vectors . Everything we have said above generalizes to the complex case.
References
This is a minimal set of references, which contain further useful references within.
- Rajendra Bhatia, Positive Definite Matrices, Princeton University Press, Princeton, NJ, USA, 2007.
- Nicholas J. Higham, Computing a nearest symmetric positive semidefinite matrix, Linear Algebra Appl. 103, 103–118, 1988. Section 5.
- Roger A. Horn and Charles R. Johnson, Matrix Analysis, second edition, Cambridge University Press, 2013. My review of the second edition.

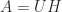
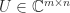

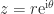

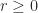

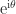
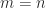
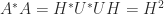
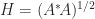
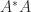
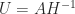
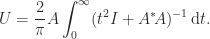
![A = \left[\begin{array}{@{}rr} 4 & 0\\ -5 & -3\\ 2 & 6 \end{array}\right] = \sqrt{2}\left[\begin{array}{@{}rr} \frac{1}{2} & -\frac{1}{6}\\[\smallskipamount] -\frac{1}{2} & -\frac{1}{6}\\[\smallskipamount] 0 & \frac{2}{3} \end{array}\right] \cdot \sqrt{2}\left[\begin{array}{@{\,}rr@{}} \frac{9}{2} & \frac{3}{2}\\[\smallskipamount] \frac{3}{2} & \frac{9}{2} \end{array}\right] \equiv UH.](https://s0.wp.com/latex.php?latex=A+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%7Drr%7D+4+%26+0%5C%5C+-5+%26+-3%5C%5C+2+%26+6+%5Cend%7Barray%7D%5Cright%5D+++%3D+++%5Csqrt%7B2%7D%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%7Drr%7D+%5Cfrac%7B1%7D%7B2%7D+%26+-%5Cfrac%7B1%7D%7B6%7D%5C%5C%5B%5Csmallskipamount%5D+-%5Cfrac%7B1%7D%7B2%7D+%26+-%5Cfrac%7B1%7D%7B6%7D%5C%5C%5B%5Csmallskipamount%5D+0+%26+%5Cfrac%7B2%7D%7B3%7D+%5Cend%7Barray%7D%5Cright%5D+++%5Ccdot+++%5Csqrt%7B2%7D%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5C%2C%7Drr%40%7B%7D%7D+%5Cfrac%7B9%7D%7B2%7D+%26+%5Cfrac%7B3%7D%7B2%7D%5C%5C%5B%5Csmallskipamount%5D+%5Cfrac%7B3%7D%7B2%7D+%26+%5Cfrac%7B9%7D%7B2%7D+%5Cend%7Barray%7D%5Cright%5D+++%5Cequiv+UH.+&bg=ffffff&fg=222222&s=0&c=20201002)
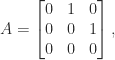

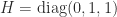


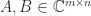
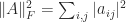
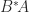
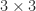

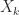
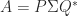
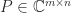
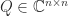
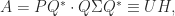



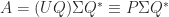
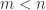
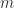
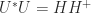
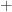
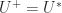
matrix, Numer. Algorithms 73, 349–369, 2016.
 matrix to upper triangular form by elementary row operations. It consists of
matrix to upper triangular form by elementary row operations. It consists of 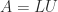 , where
, where  is unit lower triangular (lower triangular with ones on the diagonal) and
is unit lower triangular (lower triangular with ones on the diagonal) and  to the solution of two triangular systems.
to the solution of two triangular systems.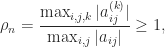
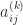 are the elements at the start of the
are the elements at the start of the 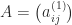 . Specifically, he obtained a bound for the backward error of the computed solution that is proportional to
. Specifically, he obtained a bound for the backward error of the computed solution that is proportional to  , where
, where  is the unit roundoff of the floating-point arithmetic. Wilkinson’s analysis focused attention on the size of the growth factor.
is the unit roundoff of the floating-point arithmetic. Wilkinson’s analysis focused attention on the size of the growth factor.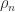 can be arbitrarily large, as is easily seen for
can be arbitrarily large, as is easily seen for  . For some specific types of matrix more can be said.
. For some specific types of matrix more can be said. . In this case one would normally use Cholesky factorization instead of LU factorization.
. In this case one would normally use Cholesky factorization instead of LU factorization. .
. .
. position at the start of stage
position at the start of stage 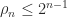 and that equality is attained for matrices of the form illustrated for
and that equality is attained for matrices of the form illustrated for  by
by![\left[\begin{array}{@{\mskip3mu}rrrr} 1 & 0 & 0 & 1 \\ -1 & 1 & 0 & 1 \\ -1 & -1 & 1 & 1 \\ -1 & -1 & -1 & 1 \\ \end{array} \right].](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip3mu%7Drrrr%7D+++++++++++++++++++++++1++%26+0++%26+0++%26+1++%5C%5C+++++++++++++++++++++++-1+%26+1++%26+0++%26+1++%5C%5C+++++++++++++++++++++++-1+%26+-1+%26+1++%26+1++%5C%5C+++++++++++++++++++++++-1+%26+-1+%26+-1+%26+1++%5C%5C++++++++%5Cend%7Barray%7D++++++++%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)

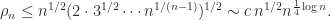
 . Much interest has focused on the question of whether growth of
. Much interest has focused on the question of whether growth of  , but such matrices do not exist for all
, but such matrices do not exist for all 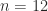 and
and 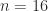 .
. matrix with growth
matrix with growth 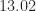 .
.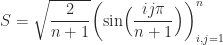
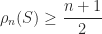
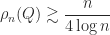
 is
is 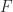 , so it must be mapped back into
, so it must be mapped back into 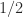 .
.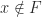 be the given number and let
be the given number and let 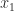 and
and 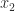 with
with  be the adjacent numbers in
be the adjacent numbers in 
 and down to
and down to  ; note that these probabilities sum to
; note that these probabilities sum to 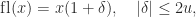
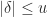 . In addition, certain results that hold for round to nearest, such as
. In addition, certain results that hold for round to nearest, such as 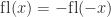 and
and 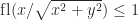 , can fail for stochastic rounding. What, then, is the benefit of stochastic rounding?
, can fail for stochastic rounding. What, then, is the benefit of stochastic rounding?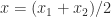 , for example), so the expected error is zero. Hence stochastic rounding maintains, in a statistical sense, some of the information that is discarded by a deterministic rounding scheme. This property leads to some important benefits, as we now explain.
, for example), so the expected error is zero. Hence stochastic rounding maintains, in a statistical sense, some of the information that is discarded by a deterministic rounding scheme. This property leads to some important benefits, as we now explain. of nonnegative elements. If the elements all lie on
of nonnegative elements. If the elements all lie on ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=222222&s=0&c=20201002) then clearly the partial sum can grow monotonically as more and more terms are accumulated until at some point all the remaining terms “drop off the end” of the computed sum and do not change it—the sum stagnates. This phenomenon was observed and analyzed by Huskey and Hartree as long ago as 1949 in solving differential equations on the ENIAC. Stochastic rounding avoids stagnation by rounding up rather than down some of the time. The next figure gives an example. Here,
then clearly the partial sum can grow monotonically as more and more terms are accumulated until at some point all the remaining terms “drop off the end” of the computed sum and do not change it—the sum stagnates. This phenomenon was observed and analyzed by Huskey and Hartree as long ago as 1949 in solving differential equations on the ENIAC. Stochastic rounding avoids stagnation by rounding up rather than down some of the time. The next figure gives an example. Here, 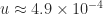 ), and the backward errors are plotted for increasing
), and the backward errors are plotted for increasing 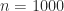 , the errors for stochastic rounding (SR, in orange) are smaller than those for round to nearest (RTN, in blue), the latter quickly reaching 1.
, the errors for stochastic rounding (SR, in orange) are smaller than those for round to nearest (RTN, in blue), the latter quickly reaching 1.
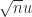 can be shown to hold with high probability. With round to nearest we have only the usual worst-case error bound, which is proportional to
can be shown to hold with high probability. With round to nearest we have only the usual worst-case error bound, which is proportional to 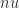 . In the figure above, the solid black line is the standard backward error bound
. In the figure above, the solid black line is the standard backward error bound 