Last week I had the pleasure of attending and speaking at the Conference on Scientific Computing and Approximation (March 30-31, 2018) at Purdue University, held in honour of Walter Gautschi (Professor Emeritus of Computer Science and Mathematics at Purdue University) on the occasion of his 90th birthday.

The conference was expertly organized by Alex Pothen and Jie Shen. The attendees, numbering around 70, included many of Walter’s friends and colleagues.
The speakers made many references to Walter’s research contributions, particularly in the area of orthogonal polynomials. In my talk, Matrix Functions and their Sensitivity, I emphasized Walter’s work on conditioning of Vandermonde matrices.
A Vandermonde matrix 



![[1, x_j, \ldots, x_j^{n-1}]^T](https://s0.wp.com/latex.php?latex=%5B1%2C+x_j%2C+%5Cldots%2C+x_j%5E%7Bn-1%7D%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002)

Walter has written numerous papers on Vandermonde matrices that give much insight into their conditioning. Here is a very a brief selection of Walter’s results. For more, see my chapter Numerical Conditioning in Walter’s collected works.
In a 1962 paper he showed that

In 1978 he obtained
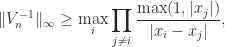
which differs from the upper bound by at most a factor 
![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=222222&s=0&c=20201002)
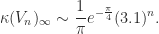
A 1988 paper returns to lower bounds, showing that for 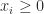
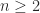

When some of the
These results quantify the extreme ill conditioning. I should note, though, that appropriate algorithms that exploit structure can nevertheless obtain accurate solutions to Vandermonde problems, as described in Chapter 22 of Accuracy and Stability of Numerical Algorithms.


