
An Open Researcher and Contributor ID, or ORCID, is a unique identifier for a researcher that allows research outputs to be associated with that researcher. If you have a common name, or have moved institutions during your career, then it can be very difficult for people to determine which papers returned in a Google Scholar search (say) are by you rather than by someone else with the same name. If at some point in your career you change your name, or how you list it on papers, the difficulty of attribution may be even greater. Having your ORCID associated with your publications solves this problem.
Such an identifier scheme has existed for some time in the form of ResearcherID from Thomson Reuters, but this is commercial and linked to the Web of Science. The ORCID organization is open and not-for-profit, and its software is open source. The ORCID web site says that as well as the registry of identifiers, ORCID provides “APIs that support system-to-system communication and authentication”. This is what makes ORCID particularly interesting, as it makes it possible to have one’s list of publications generated in an automatic way, either by entering each on the ORCID site and then the list propagating elsewhere, or by ORCID automatically pulling in publication metadata and associating it with you.
The starting point for exploiting ORCIDs is for publishers to collect them at the time of submission. The Royal Society has been collecting ORCIDs with submissions since 2014, and since the turn of the year it has required authors submitting to its journals to provide an ORCID. As the Royal Society points out, “Once you have created an ORCID identifier and connected it with your publications, grants, and affiliations, your details will automatically be entered when using any compatible system”. Other publishers are following suit, as this open letter indicates.
I recently received an email saying “You have 1 new notification in your ORCID inbox”. When I went to the inbox I found a message saying that “Crossref [another not-for-profit organization] would like your permission to interact with your ORCID Record as a trusted party”. I gave permission and now when publishers send information about my new publications to Crossref they will be added to my ORCID record. For more on this important Crossref-ORCID link, see this article.
For academics used to having to repeatedly enter the same information into different systems this automatic updating of an ORCID record is great news.
The University of Manchester recently made it compulsory for an academic to have an ORCID in order to be part of its internal research assessment exercise (the university has a good page about ORCID that answers some FAQs). Research Councils UK recently joined ORCID and will soon start capturing ORCIDs on its grant systems. With these organizations actively supporting the scheme, and many other organizations members of the scheme (including the American Mathematical Society, but not yet SIAM), it seems that ORCID has a bright future. However, my impression is that many academics are unaware of ORCID. There is plenty of information about it on the web, but probably not in the places academics tend to look.
I expect interest will increase rapidly as ORCID becomes better known. I notice that Springer has started to provide links from an author name on a paper to the ORCID page for that author. This is just the sort of added value feature that will make academics want to register for an ORCID.


 , as they are today.
, as they are today. 
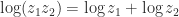
 denotes a particular branch of the logarithm—possibly different in each case. In other words, the equation is true for the multivalued function that includes all branches.
denotes a particular branch of the logarithm—possibly different in each case. In other words, the equation is true for the multivalued function that includes all branches.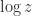 lies in the interval
lies in the interval ![(-\pi,\pi]](https://s0.wp.com/latex.php?latex=%28-%5Cpi%2C%5Cpi%5D&bg=ffffff&fg=222222&s=0&c=20201002) (or possibly some other specific branch). Now the equation is not always true. A correction term that makes the equation valid can be expressed in terms of the unwinding number introduced by Corless, Hare, and Jeffrey in 1996, which is discussed in my earlier post
(or possibly some other specific branch). Now the equation is not always true. A correction term that makes the equation valid can be expressed in terms of the unwinding number introduced by Corless, Hare, and Jeffrey in 1996, which is discussed in my earlier post  is not equivalent to
is not equivalent to 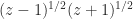 for complex
for complex  ). This is a good way to proceed, but working out the ranges of the principal functions from these definitions is not trivial.
). This is a good way to proceed, but working out the ranges of the principal functions from these definitions is not trivial. equal to
equal to  ?”—see our recent EPrint
?”—see our recent EPrint 



