For a given 

Theorem 1 (Gershgorin’s theorem).
The eigenvalues of
lie in the union of the
Proof. Let
be an eigenvalue of
and
a corresponding eigenvector and let
. From the
th equation in
we have
Hence
and since
it follows that
.
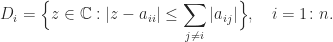


The Gershgorin discs 
A consequence of the theorem is that if 
Another consequence of the theorem is that if
The Gershgorin discs for the 
![\notag \left[\begin{array}{ccccc} 5/4 & 1 & 3/4 & 1/2 & 1/4 \\ 1 & 0 & 0 & 0 & 0\\ -1 & 1 & 0 & 0 & 0\\ 0 & 0 & 1 & 3 & 0\\ 0 & 0 & 0 & 1/2 & 5 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cnotag+%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccc%7D+5%2F4+++++++++%26+1+%26+3%2F4+++++++++%26+1%2F2+++++++++%26+1%2F4++++++++%5C%5C+1+%26+0+%26+0+%26+0+%26+0%5C%5C+-1+%26+1+%26+0+%26+0+%26+0%5C%5C+0+%26+0+%26+1+%26+3+%26+0%5C%5C+0+%26+0+%26+0+%26+1%2F2+++++++++%26+5+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=222222&s=0&c=20201002)
are shown here:
 The eigenvalues—three real and one complex conjugate pair—are the black dots. It happens that each disc contains an eigenvalue, but this is not always the case. For the matrix
The eigenvalues—three real and one complex conjugate pair—are the black dots. It happens that each disc contains an eigenvalue, but this is not always the case. For the matrix
![\notag \left[\begin{array}{cc} 2 & -1\\ 2 & 0 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cnotag+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7D+2+%26+-1%5C%5C+2+%26+0+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=222222&s=0&c=20201002)
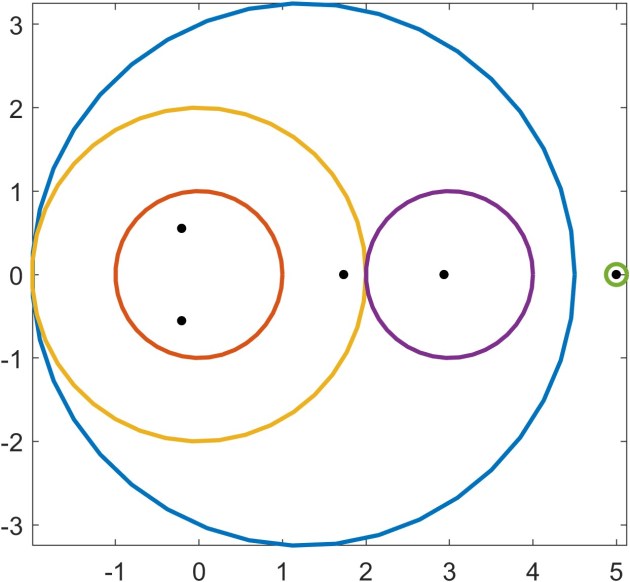
the discs are
 and the blue disc does not contain an eigenvalue. The next result, which is proved by a continuity argument, provides additional information that increases the utility of Gershgorin’s theorem. In particular it says that if a disc is disjoint from the other discs then it contains an eigenvalue.
and the blue disc does not contain an eigenvalue. The next result, which is proved by a continuity argument, provides additional information that increases the utility of Gershgorin’s theorem. In particular it says that if a disc is disjoint from the other discs then it contains an eigenvalue.
Theorem 2.
If
Theorem 2 tells us that the rightmost disc in our 
Gershgorin’s theorem is most useful for matrices that are close to being diagonal. A technique that can produce improved eigenvalue estimates is to apply the theorem to 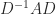


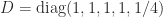
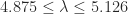
Notes
Most books on matrix analysis or numerical linear algebra include Gershgorin’s theorem.
Eigenvalue inclusion regions have been developed with discs replaced by more complicated shapes, such as Brauer’s ovals of Cassini.
Varga’s 2004 book is devoted to Gershgorin’s theorem and related results. It reproduces Gershgorin’s 1931 paper in an appendix.
References
- S. Gerschgorin. Uber die Abgrenzung der Eigenwerte einer Matrix. Izv. Akad. Nauk. SSSR, 1:749–754, 1931.
- Richard S. Varga. Geršgorin and His Circles. Springer-Verlag, Berlin, Germany, 2004.
Related Blog Posts
- What Is a Diagonally Dominant Matrix? (2021)
- What Is an Eigenvalue? (2022)
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
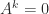 for some positive integer
for some positive integer 
 is the
is the  instance of the upper bidiagonal
instance of the upper bidiagonal  matrix
matrix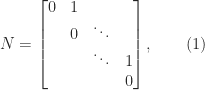

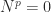 . The superdiagonal of ones moves up to the right with each increase in the index of the power until it disappears off the top right corner of the matrix.
. The superdiagonal of ones moves up to the right with each increase in the index of the power until it disappears off the top right corner of the matrix.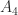 has rank
has rank  and was constructed using a general formula: if
and was constructed using a general formula: if  with
with  then
then  . We simply took orthogonal vectors
. We simply took orthogonal vectors ![x =[2, -4, 1]^T](https://s0.wp.com/latex.php?latex=x+%3D%5B2%2C+-4%2C+1%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002) and
and ![y = [1, 1, 2]^T](https://s0.wp.com/latex.php?latex=y+%3D+%5B1%2C+1%2C+2%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002) .
.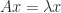 with
with 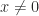 implies
implies 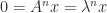 or
or 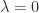 . Consequently, the trace and determinant of a nilpotent matrix are both zero.
. Consequently, the trace and determinant of a nilpotent matrix are both zero.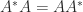 ), then
), then 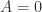 , since such a matrix has a spectral decomposition
, since such a matrix has a spectral decomposition  and the matrix
and the matrix 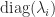 is zero. It is only for nonnormal matrices that nilpotency is a nontrivial property, and the best way to understand it is with the Jordan canonical form (JCF). The JCF of a matrix with only zero eigenvalues has the form
is zero. It is only for nonnormal matrices that nilpotency is a nontrivial property, and the best way to understand it is with the Jordan canonical form (JCF). The JCF of a matrix with only zero eigenvalues has the form 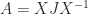 , where
, where  , where
, where  is of the form (1) and hence
is of the form (1) and hence 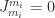 . It follows that the index of nilpotency is
. It follows that the index of nilpotency is  .
. , attained when the JCF of
, attained when the JCF of  is attained when there is a Jordan block of size
is attained when there is a Jordan block of size 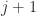 and all other blocks are
and all other blocks are 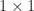 .
.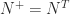 for
for 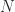 in (1).
in (1).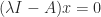 , which means that
, which means that 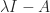 is singular, since
is singular, since  . But
. But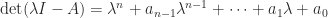
 , the eigenvalues of
, the eigenvalues of 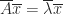 , so if
, so if  .
.
 are upper triangular, that is,
are upper triangular, that is, 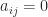 for
for 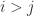 . For such a matrix the eigenvalues are the diagonal elements.
. For such a matrix the eigenvalues are the diagonal elements. ) or Hermitian matrix (
) or Hermitian matrix (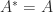 , where
, where 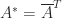 ) has real eigenvalues. A proof is
) has real eigenvalues. A proof is 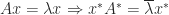 so premultiplying the first equation by
so premultiplying the first equation by  and postmultiplying the second by
and postmultiplying the second by 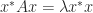 and
and 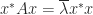 , which means that
, which means that 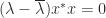 , or
, or 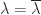 since
since  . The matrix
. The matrix  ) or skew-Hermitian complex matrix (
) or skew-Hermitian complex matrix (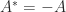 ) has pure imaginary eigenvalues. A proof is similar to the Hermitian case:
) has pure imaginary eigenvalues. A proof is similar to the Hermitian case:  and so
and so  is equal to both
is equal to both 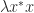 and
and 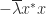 , so
, so 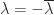 . The matrix
. The matrix 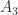 above is skew-symmetric.
above is skew-symmetric.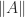 , because for any matrix norm
, because for any matrix norm  it can be shown that every eigenvalue satisfies
it can be shown that every eigenvalue satisfies 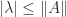 .
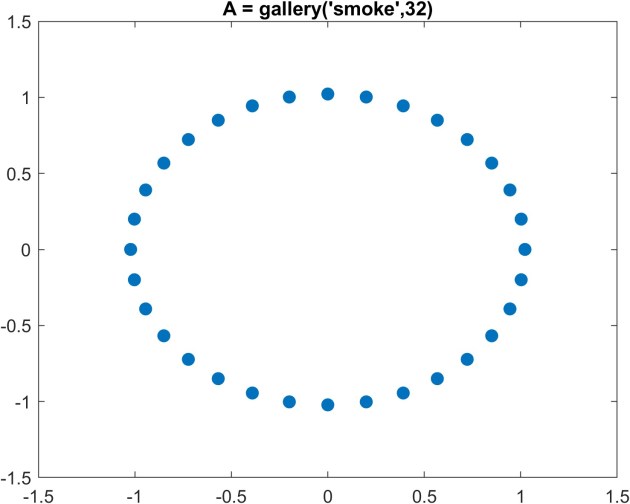
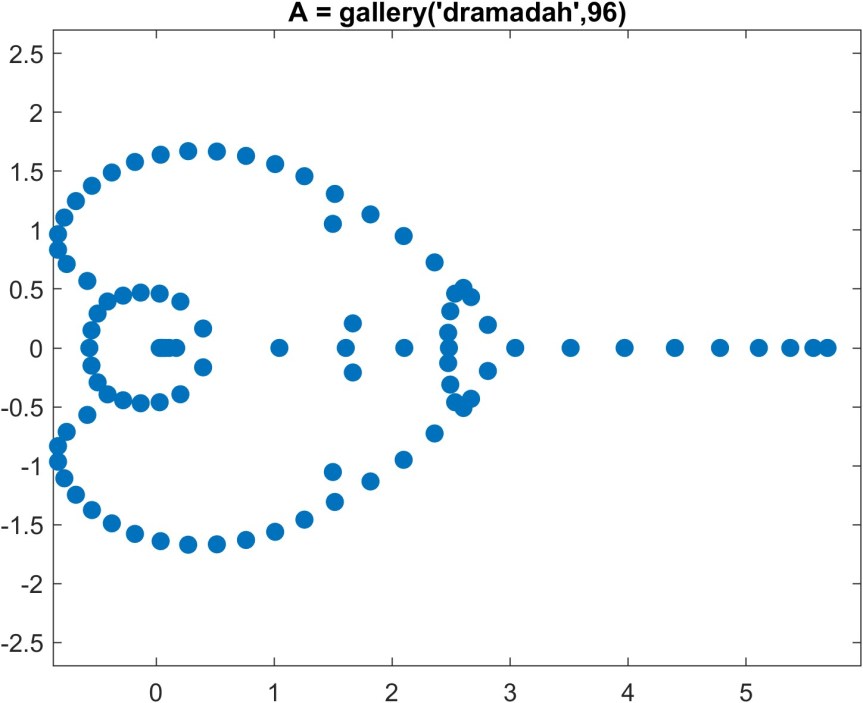
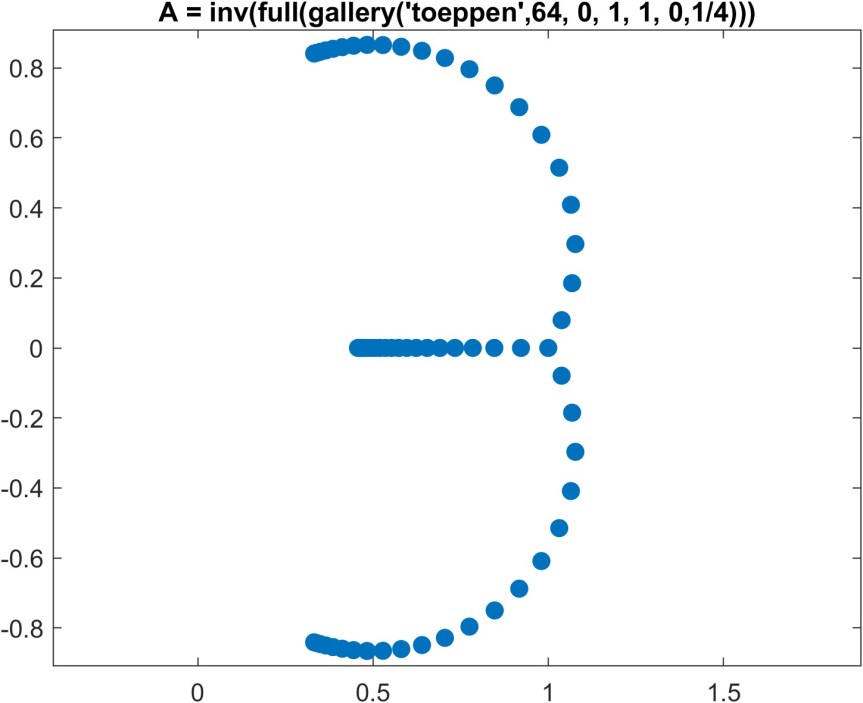
.
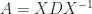 for some nonsingular matrix
for some nonsingular matrix  with
with 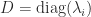 the matrix of eigenvalues. If we write
the matrix of eigenvalues. If we write ![X = [x_1,x_2,\dots,x_n]](https://s0.wp.com/latex.php?latex=X+%3D+%5Bx_1%2Cx_2%2C%5Cdots%2Cx_n%5D&bg=ffffff&fg=222222&s=0&c=20201002) then
then 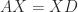 is equivalent to
is equivalent to  ,
,  , so the
, so the  are eigenvectors of
are eigenvectors of ![\left[\begin{smallmatrix}1 \\ 0 \end{smallmatrix}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Bsmallmatrix%7D1+%5C%5C+0+%5Cend%7Bsmallmatrix%7D%5Cright%5D&bg=ffffff&fg=222222&s=0&c=20201002) (or any nonzero scalar multiple of it). This matrix is a Jordan block. The matrix
(or any nonzero scalar multiple of it). This matrix is a Jordan block. The matrix 