Rounding is the transformation of a number expressed in a particular base to a number with fewer digits. For example, in base 10 we might round the number 

The three main uses of rounding are
- to simplify a number in base 10 for human consumption,
- to represent a constant such as
,
, or
in floating-point arithmetic,
- to convert the result of an elementary operation (an addition, multiplication, or division) on floating-point numbers back into a floating-point number.
The floating-point numbers may be those used on a computer (base 2) or a pocket calculator (base 10).
Rounding can be done in several ways.
Round to Nearest
The most common form of rounding is to round to the nearest number with the specified number of significant digits or decimal places. In the example above, the two nearest numbers to 

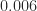
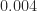
What happens if the two candidate numbers are equally close? We need a rule for breaking the tie. The most common choices are
- round to even: choose the number with an even last digit,
- round to odd: choose the number with an odd last digit.
If we round 


There are several reasons for preferring to break ties with round to even.
- In bases 2 and 10 a subsequent rounding to one less place does not involve a tie. Thus we have the rounding sequence
,
,
,
with round to even, but
,
,
with round to odd.
- For base 2, round to even results in integers more often, as a consequence of producing a zero least significant bit.
- In base 10, after round to even a rounded number can be halved without error.
IEEE Standard 745 for floating-point arithmetic supports three tie-breaking methods: round to even (the default), round to the number with larger magnitude, and round towards zero (introduced in the 2019 revision for use with the standard’s new augmented operations).
The tie-breaking rule taught in UK schools, for decimal arithmetic, is to round up on ties. The rounding rule then becomes: round down if the first digit to be dropped is 
Round Towards Plus or Minus Infinity
Another possibility is to round to the next larger number with the specified number of digits, which is known as round towards plus infinity (or round up). Then 

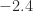
This form of rounding is used in interval arithmetic, where an interval guaranteed to contain the exact result is computed in floating-point arithmetic.
Round Towards Zero
In this form of rounding we round towards zero, that is, we round 

Stochastic Rounding
Stochastic rounding was proposed in the 1950s and is attracting renewed interest, especially in machine learning. It rounds up or down randomly. It come in two forms. The first form rounds up or down with equal probability 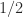

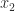

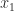


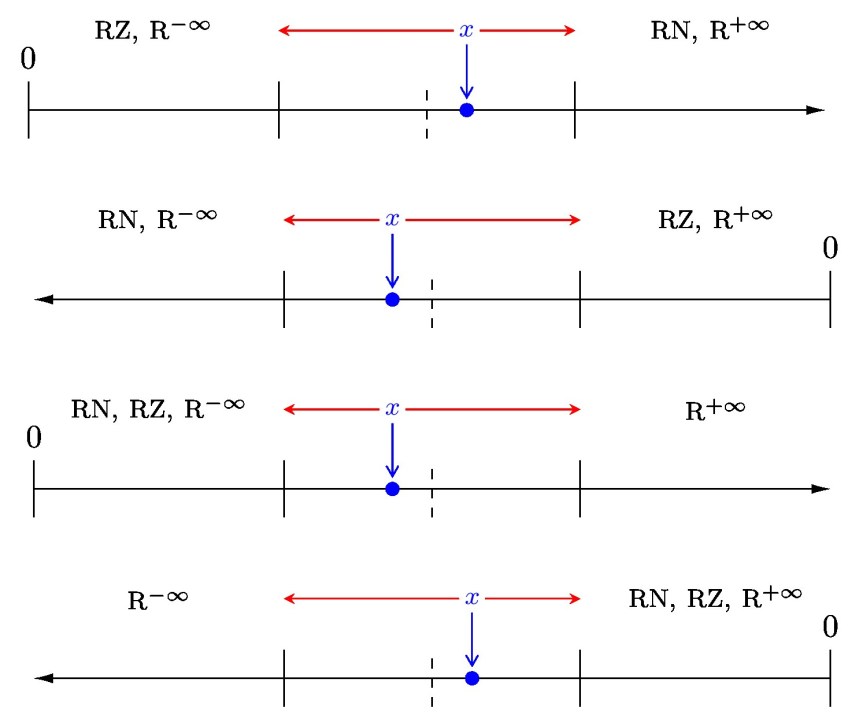
The diagrams below illustrate round to nearest (RN), round towards zero (RZ), round towards plus infinity (

Real World Rounding
The European Commission’s rules for converting currencies of Member States into Euros (from the time of the creation of the Euro) specify that “half-way results are rounded up” (rounded to plus infinity). (PDF link)
The International Association of Athletics Federations (IAAF) specifies in Rule 165 of its Competition Rules 2018–2019 that all times of track races up to 10,000m should be recorded to a precision of 0.01 second, with rounding to plus infinity. In 2006, the athlete Justin Gatlin was wrongly credited with breaking the 100m world record when his official time of 9.766 seconds was rounded down to 9.76 seconds. Under the IAAF rules it should have been rounded up to 9.77 seconds, matching the world record set by Asafa Powell the year before. The error was discovered several days after the race.
In meteorology, rounding to nearest with ties broken by rounding to odd is favoured. Hunt suggests that the reason is to avoid falsely indicating that it is freezing. Thus 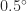




Useful Tool
The 
References
This is a minimal set of references, which contain further useful references within.
- Michael P. Connolly, Nicholas J. Higham, and Theo Mary, Stochastic Rounding and Its Probabilistic Backward Error Analysis, MIMS EPrint 2020.12, Manchester Institute for Mathematical Sciences, The University of Manchester, UK, April 2020.
- Nicholas J. Higham, Accuracy and Stability of Numerical Algorithms, second edition, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2002.
- Julian Hunt, Rounding and Other Approximations for Measurements, Records and Targets, Mathematics Today 33, 73–77, 1997.
- IEEE Standard for Floating-Point Arithmetic, IEEE Std 754-2019 (Revision of IEEE 754-2008), IEEE Computer Society, New York, 2019.
Related Blog Posts
- What Is Floating-Point Arithmetic? (2020)—forthcoming
- What Is IEEE Standard Arithmetic? (2020)—forthcoming
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
 is orthogonal and symmetric and we can choose the nonzero vector
is orthogonal and symmetric and we can choose the nonzero vector  randomly. Such an example is rather special, though, as it is a rank-
randomly. Such an example is rather special, though, as it is a rank- is from the Haar distribution then so is
is from the Haar distribution then so is  for any orthogonal (possibly non-random)
for any orthogonal (possibly non-random)  and
and  . A random Householder matrix is not Haar distributed.
. A random Householder matrix is not Haar distributed. , variance
, variance  has nonnegative diagonal elements. This construction requires
has nonnegative diagonal elements. This construction requires  flops.
flops. be an
be an 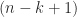 -vector of elements from the standard normal distribution and let
-vector of elements from the standard normal distribution and let  be the Householder matrix that reduces
be the Householder matrix that reduces 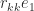 , where
, where 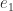 is the first unit vector. Then
is the first unit vector. Then 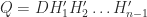 is Haar distributed, where
is Haar distributed, where  ,
, 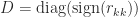 , and
, and 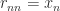 . This construction expresses
. This construction expresses  Householder matrices of growing effective dimension, and the product can be formed from right to left in
Householder matrices of growing effective dimension, and the product can be formed from right to left in 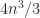 flops. The MATLAB statement
flops. The MATLAB statement 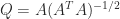 , where the elements of
, where the elements of  are from the standard normal distribution. This
are from the standard normal distribution. This 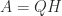 (where
(where  is symmetric positive semidefinite).
is symmetric positive semidefinite).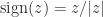 .
. are column vectors with
are column vectors with 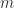 elements, each vector containing samples of a random variable, then the corresponding
elements, each vector containing samples of a random variable, then the corresponding  covariance matrix
covariance matrix  element
element
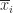 is the mean of the elements in
is the mean of the elements in  . If
. If  has nonzero diagonal elements then we can scale the diagonal to 1 to obtain the corresponding correlation matrix
has nonzero diagonal elements then we can scale the diagonal to 1 to obtain the corresponding correlation matrix
 . The
. The 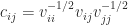 is the correlation between the variables
is the correlation between the variables 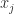 .
.![[-1, 1]](https://s0.wp.com/latex.php?latex=%5B-1%2C+1%5D&bg=ffffff&fg=222222&s=0&c=20201002) .
.![[0,n]](https://s0.wp.com/latex.php?latex=%5B0%2Cn%5D&bg=ffffff&fg=222222&s=0&c=20201002) .
. (since the eigenvalues of a matrix sum to its trace).
(since the eigenvalues of a matrix sum to its trace).
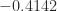 ,
,  ,
, 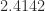 . The only value of
. The only value of 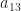 and
and  that makes
that makes 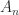 with every off-diagonal element equal to
with every off-diagonal element equal to  , illustrated for
, illustrated for 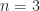 by
by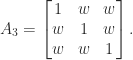
 .
. , so we solve the problem
, so we solve the problem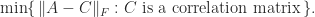
 remain fixed. And we may want to weight some elements more than others, by using a weighted Frobenius norm. These are convex optimization problems and have a unique solution that can be computed using the alternating projections method (Higham, 2002) or a Newton algorithm (Qi and Sun, 2006; Borsdorf and Higham, 2010).
remain fixed. And we may want to weight some elements more than others, by using a weighted Frobenius norm. These are convex optimization problems and have a unique solution that can be computed using the alternating projections method (Higham, 2002) or a Newton algorithm (Qi and Sun, 2006; Borsdorf and Higham, 2010). matrix for some given
matrix for some given  , where
, where  is a target correlation matrix (Higham, Strabić, and Šego, 2016). Shrinking can readily incorporate fixed blocks and weighting.
is a target correlation matrix (Higham, Strabić, and Šego, 2016). Shrinking can readily incorporate fixed blocks and weighting. and mutually orthogonal columns. For example,
and mutually orthogonal columns. For example,![\left[\begin{array}{rrrr} 1 & 1 & 1 & 1\\ 1 & -1 & 1 & -1\\ 1 & 1 & -1 & -1\\ 1 & -1 & -1 & 1 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrrr%7D+++++++1+%26+1+%26+1+%26+1%5C%5C+++++++1+%26+-1+%26+1+%26+-1%5C%5C+++++++1+%26+1+%26+-1+%26+-1%5C%5C+++++++1+%26+-1+%26+-1+%26+1+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=222222&s=0&c=20201002)
 is that
is that 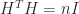 , so
, so  . It also follows that
. It also follows that  . Hadamard’s inequality states that for an
. Hadamard’s inequality states that for an  , where
, where  is the
is the ![\left[\begin{array}{rr} H & H\\ H & -H \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brr%7D++++++++++H+%26+H%5C%5C++++++++++H+%26+-H+++%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
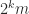 for
for 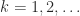 . The MATLAB
. The MATLAB ![\left[\begin{array}{rrrrrrrrrrrr} {}+ & + & + & + & + & 1 & + & + & + & + & + & +\\ {}+ & - & + & - & + & + & + & - & - & - & + & -\\ {}+ & - & - & + & - & + & + & + & - & - & - & +\\ {}+ & + & - & - & + & - & + & + & + & - & - & -\\ {}+ & - & + & - & - & + & - & + & + & + & - & -\\ {}+ & - & - & + & - & - & + & - & + & + & + & -\\ {}+ & - & - & - & + & - & - & + & - & + & + & +\\ {}+ & + & - & - & - & + & - & - & + & - & + & +\\ {}+ & + & + & - & - & - & + & - & - & + & - & +\\ {}+ & + & + & + & - & - & - & + & - & - & + & -\\ {}+ & - & + & + & + & - & - & - & + & - & - & +\\ {}+ & + & - & + & + & + & - & - & - & + & - & - \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Brrrrrrrrrrrr%7D+%7B%7D%2B+%26+%2B+%26+%2B+%26+%2B+%26+%2B+%26+1+%26+%2B+%26+%2B+%26+%2B+%26+%2B+%26+%2B+%26+%2B%5C%5C+%7B%7D%2B+%26+-+%26+%2B+%26+-+%26+%2B+%26+%2B+%26+%2B+%26+-+%26+-+%26+-+%26+%2B+%26+-%5C%5C+%7B%7D%2B+%26+-+%26+-+%26+%2B+%26+-+%26+%2B+%26+%2B+%26+%2B+%26+-+%26+-+%26+-+%26+%2B%5C%5C+%7B%7D%2B+%26+%2B+%26+-+%26+-+%26+%2B+%26+-+%26+%2B+%26+%2B+%26+%2B+%26+-+%26+-+%26+-%5C%5C+%7B%7D%2B+%26+-+%26+%2B+%26+-+%26+-+%26+%2B+%26+-+%26+%2B+%26+%2B+%26+%2B+%26+-+%26+-%5C%5C+%7B%7D%2B+%26+-+%26+-+%26+%2B+%26+-+%26+-+%26+%2B+%26+-+%26+%2B+%26+%2B+%26+%2B+%26+-%5C%5C+%7B%7D%2B+%26+-+%26+-+%26+-+%26+%2B+%26+-+%26+-+%26+%2B+%26+-+%26+%2B+%26+%2B+%26+%2B%5C%5C+%7B%7D%2B+%26+%2B+%26+-+%26+-+%26+-+%26+%2B+%26+-+%26+-+%26+%2B+%26+-+%26+%2B+%26+%2B%5C%5C+%7B%7D%2B+%26+%2B+%26+%2B+%26+-+%26+-+%26+-+%26+%2B+%26+-+%26+-+%26+%2B+%26+-+%26+%2B%5C%5C+%7B%7D%2B+%26+%2B+%26+%2B+%26+%2B+%26+-+%26+-+%26+-+%26+%2B+%26+-+%26+-+%26+%2B+%26+-%5C%5C+%7B%7D%2B+%26+-+%26+%2B+%26+%2B+%26+%2B+%26+-+%26+-+%26+-+%26+%2B+%26+-+%26+-+%26+%2B%5C%5C+%7B%7D%2B+%26+%2B+%26+-+%26+%2B+%26+%2B+%26+%2B+%26+-+%26+-+%26+-+%26+%2B+%26+-+%26+-+%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
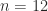 and
and 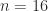 .
. -norm (the matrix norm subordinate to the vector
-norm (the matrix norm subordinate to the vector 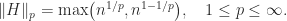
 is
is 
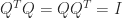 (the identity matrix). Equivalently,
(the identity matrix). Equivalently, 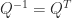 . The columns of an orthogonal matrix are orthonormal, that is, they have 2-norm (Euclidean length)
. The columns of an orthogonal matrix are orthonormal, that is, they have 2-norm (Euclidean length)  rotation matrix has the form
rotation matrix has the form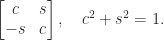
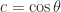 and
and 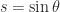 for some
for some 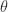 , and the multiplication
, and the multiplication  for a
for a 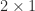 vector
vector  , such a matrix has the form
, such a matrix has the form
 Householder reflector corresponding to
Householder reflector corresponding to ![v = [1,1,1,1]^T/2](https://s0.wp.com/latex.php?latex=v+%3D+%5B1%2C1%2C1%2C1%5D%5ET%2F2&bg=ffffff&fg=222222&s=0&c=20201002) :
:![\frac{1}{2} \left[\begin{array}{@{\mskip2mu}rrrr@{\mskip2mu}} 1 & -1 & -1 & -1\\ -1 & 1 & -1 & -1\\ -1 & -1 & 1 & -1\\ -1 & -1 & -1 & 1\\ \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D+++++++++%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip2mu%7Drrrr%40%7B%5Cmskip2mu%7D%7D++++++++++++++++++++++++1+%26+++-1+%26+++-1+%26+++-1%5C%5C+++++++++++++++++++++++-1+%26++++1+%26+++-1+%26+++-1%5C%5C+++++++++++++++++++++++-1+%26+++-1+%26++++1+%26+++-1%5C%5C+++++++++++++++++++++++-1+%26+++-1+%26+++-1+%26++++1%5C%5C++++++++%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)

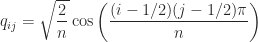
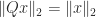 for any vector
for any vector  .
. is skew-symmetric (
is skew-symmetric ( ) then
) then  (the matrix exponential) is orthogonal and the Cayley transform
(the matrix exponential) is orthogonal and the Cayley transform 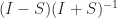 is orthogonal as long as
is orthogonal as long as 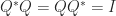 , where
, where 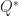 is the conjugate transpose of
is the conjugate transpose of  matrix
matrix  is
is 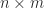 :
: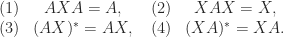
 denotes the conjugate transpose. A 1-inverse is any
denotes the conjugate transpose. A 1-inverse is any  then
then  , so
, so 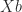 solves the equation, meaning that any 1-inverse is an equation-solving inverse. Condition (2) implies that
solves the equation, meaning that any 1-inverse is an equation-solving inverse. Condition (2) implies that 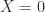 if
if 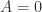 .
.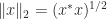 ).
).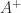 or
or 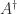 . For any system of linear equations
. For any system of linear equations 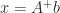 minimizes
minimizes 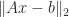 and has the minimum 2–norm over all minimizers.
and has the minimum 2–norm over all minimizers.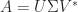 is an SVD, where the
is an SVD, where the 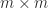 matrix
matrix  with
with  (so that
(so that  ), then
), then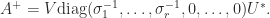
 then the concise formula
then the concise formula  holds.
holds.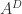 such that
such that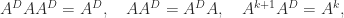
 . The first condition is the same as the second of the Moore–Penrose conditions, but the second and third have a different flavour. The index of a matrix of
. The first condition is the same as the second of the Moore–Penrose conditions, but the second and third have a different flavour. The index of a matrix of  ; it is characterized as the dimension of the largest Jordan block of
; it is characterized as the dimension of the largest Jordan block of  then
then 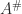 . The Drazin inverse is an equation-solving inverse precisely when
. The Drazin inverse is an equation-solving inverse precisely when 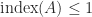 , for then
, for then 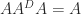 , which is the first of the Moore–Penrose conditions.
, which is the first of the Moore–Penrose conditions.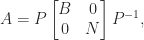
 and
and  are nonsingular and
are nonsingular and 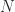 has only zero eigenvalues, then
has only zero eigenvalues, then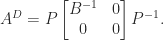
![A = \left[\begin{array}{rrr} 1 & -1 & -1\\[3pt] 0 & 0 & -1\\[3pt] 0 & 0 & 0 \end{array}\right], \quad A^+ = \left[\begin{array}{rrr} \frac{1}{2} & -\frac{1}{2} & 0\\[3pt] -\frac{1}{2} & \frac{1}{2} & 0\\[3pt] 0 & -1 & 0 \end{array}\right], \quad A^D = \left[\begin{array}{rrr} 1 & -1 & 0\\[3pt] 0 & 0 & 0\\[3pt] 0 & 0 & 0 \end{array}\right].](https://s0.wp.com/latex.php?latex=A+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7D+1+%26+-1+%26+-1%5C%5C%5B3pt%5D+0+%26+0+%26+-1%5C%5C%5B3pt%5D+0+%26+0+%26+0+%5Cend%7Barray%7D%5Cright%5D%2C+%5Cquad+A%5E%2B+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7D+%5Cfrac%7B1%7D%7B2%7D+%26+-%5Cfrac%7B1%7D%7B2%7D+%26+0%5C%5C%5B3pt%5D+-%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B1%7D%7B2%7D+%26+0%5C%5C%5B3pt%5D+0+%26+-1+%26+0+%5Cend%7Barray%7D%5Cright%5D%2C+%5Cquad+A%5ED+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7D+1+%26+-1+%26+0%5C%5C%5B3pt%5D+0+%26+0+%26+0%5C%5C%5B3pt%5D+0+%26+0+%26+0+%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
