The softmax function takes as input an 

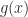

The elements of 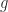


Softmax is the gradient vector of the log-sum-exp function

This function is an approximation to the largest element, 


A problem with numerical evaluation of log-sum-exp and softmax is that overflow is likely even for quite modest values of 
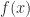
A standard solution it to incorporate a shift, 

and

where
Another formula for softmax is obtained by moving the denominator into the numerator:
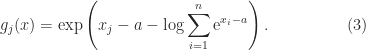
This formulas is used in various codes, including in the SciPy 1.4.1 function softmax.
How accurate are these formulas when evaluated in floating-point arithmetic? To my knowledge, this question has not been addressed in the literature, but it is particularly important given the growing use of low precision arithmetic in machine learning. Two questions arise. First, is there any difference between the accuracy of the formulas (2) and (3) for 

In a recent EPrint with Pierre Blanchard and Des Higham I have investigated these questions using rounding error analysis and analysis of the conditioning of the log-sum-exp and softmax problems. In a nutshell, our findings are that while cancellation can happen, it is not a problem: the shifted formulas (1) and (2) can be safely used.
However, the alternative softmax formula (3) is not recommended, as its rounding error bounds are larger than for (2) and we have found it to produce larger errors in practice.
Here is an example from training an artificial neural network using the MATLAB Deep Learning Toolbox. The network is trained to classify handwritten digits from the widely used MNIST data set. The following figure shows the sum of the computed elements of the softmax vector

