My first programming languages were Fortran, learned in my mathematics degree, and Basic, which was the language built into the ROM (read only memory) of the Commodore PET. The PET—one of the early microcomputers, first produced in 1977—stored programs on cassette tapes, using its integral cassette deck. In those days you could buy programs on tape, at what today would seem very high prices, but people mostly wrote their own programs or typed them in from a magazine.
Many computer magazines existed that published (and paid for) programs written by hobbyists. Readers would happily type in a page or two of code in order to try the programs out. The two most popular categories of programs were games and utilities. I recently came across a file in which I’d kept a page from the January 1982 issue of Your Computer magazine containing one of my first published programs. The whole page is here in PDF form.

The purpose of the Screenprint program is to print the contents of the PET’s screen to an attached Commodore printer—something there was no built-in way to do. The pictures underneath the listing are screen dumps of the output from another program I wrote called Whirly Art.
Some explanation of the code is needed.
- In Commodore Basic (a variant of Microsoft Basic) , line numbers are essential and are the target for a goto statement, which jumps to the specified line. Notice that the line numbers here are spaced about 10 apart: this is to allow for insertion of intermediate lines as the code is developed. There was no standard way to renumber the lines of a program, but I think I later acquired an add-on ROM that could do this.
- There are no spaces within any non-comment line of code. Today this would be terrible coding practice, but each space took one byte of storage and in those days storage was at a premium. This bit of code was intended to be appended to another program, so it was important that it occupy as little memory as possible. The Basic interpreter was able to recognize keywords IF, THEN, FOR, etc., even when they were not surrounded by spaces.
- The PEEK command reads a byte from RAM (random access memory) and the POKE commands writes a byte to RAM. CHR$(A) is a string character with ASCII value A.
I was surprised to find that scans of many issues of Your Computer are available on the Internet Archive. Indeed that archive contains a huge range of material on all topics, including a selection of books about the Commodore PET, some of which are in my loft but which I have not looked at for years.
 Collisions at
Collisions at  and 8 TeV with the ATLAS and CMS experiments
and 8 TeV with the ATLAS and CMS experiments

 -by-
-by- has a square root: a matrix
has a square root: a matrix  such that
such that 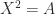 . In fact, it has at least two square roots,
. In fact, it has at least two square roots,  , and possibly infinitely many. These two extremes occur when
, and possibly infinitely many. These two extremes occur when  , the cost of the recurrence for computing
, the cost of the recurrence for computing  is the same as the cost of computing
is the same as the cost of computing 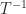 , namely
, namely 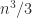 flops. But while the inverse of a triangular matrix is a level 3 BLAS operation, and so has been very efficiently implemented in libraries, the square root computation is not in the level 3 BLAS standard. As a result, my sqrtm implemented the Björck–Hammarling recurrence in M-code as a triply nested loop and was rather slow.
flops. But while the inverse of a triangular matrix is a level 3 BLAS operation, and so has been very efficiently implemented in libraries, the square root computation is not in the level 3 BLAS standard. As a result, my sqrtm implemented the Björck–Hammarling recurrence in M-code as a triply nested loop and was rather slow.  , the new code is slower. But for
, the new code is slower. But for  we already have a factor 8 speedup, rising to a factor 69 for
we already have a factor 8 speedup, rising to a factor 69 for 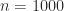 . The slowdown for
. The slowdown for 
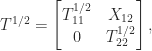
 . In this way the task of computing the square root of
. In this way the task of computing the square root of 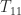 and
and 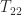 and then solving the Sylvester equation for
and then solving the Sylvester equation for  . The Sylvester equation is solved using an LAPACK routine, for efficiency. If you’d like to take a look at the code, type
. The Sylvester equation is solved using an LAPACK routine, for efficiency. If you’d like to take a look at the code, type 