For a vector 


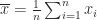
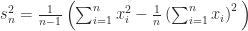
How do spreadsheets apps available in web browsers and hosted in the cloud fare on computations such as this? I used Google Sheets to compute the standard deviation of vectors of the form ![x = [m, m+1, m+2]](https://s0.wp.com/latex.php?latex=x+%3D+%5Bm%2C+m%2B1%2C+m%2B2%5D&bg=ffffff&fg=222222&s=0&c=20201002)
 |
Exact standard deviation | Google’s result |
|---|---|---|
 |
1 | 1 |
 |
1 | 0 |
The incorrect result 0 for 


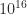
It seems that Google Sheets is using IEEE double precision arithmetic internally, because the expression 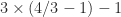
This use of the unstable formula is deeply unsatisfactory, but it is just the tip of the iceberg. In a recent paper Spreadsheets in the Cloud—Not Ready Yet, Bruce McCullough and Talha Yalta show that Google Sheets, Excel Web App and Zoho Sheet all fail on various members of a set of “sanity tests”. This might not be too surprising if you are aware of McCullough’s earlier work in which he found errors in several versions of Microsoft Excel.
However, spreadsheets in the cloud bring further complications, as noted by McCullough and Yalta:
- These spreadsheets apps do not carry version information and the software can be changed by the provider at any time without announcement. It is therefore impossible to reproduce results computed previously.
- The hardware and software environment on which the software is running is not specified, which adds another level of irreproducibility.
- McCullough and Yalta found that the Excel Web App could produce different output from Excel 2010. Anyone moving a spreadsheet between the two applications could be in for a surprise.
The conclusion: use spreadsheets in the cloud at your peril! In fact, I avoid spreadsheets altogether. Anything I want to do can be done better in MATLAB, LaTeX or Emacs ORG mode.
 The conference venue. Note the residual snow, which fortunately did not fall in any serious amounts during the conference.
The conference venue. Note the residual snow, which fortunately did not fall in any serious amounts during the conference.  The poster session of about 65 posters was preceded by a poster blitz (1 minute presentations) and was accompanied by an excellent dessert. This photo shows Edvin Deadman (University of Manchester and NAG Ltd.) discussing his poster on Matrix Functions and the NAG Library with Cleve Moler and Charlie Van Loan (authors of the classic
The poster session of about 65 posters was preceded by a poster blitz (1 minute presentations) and was accompanied by an excellent dessert. This photo shows Edvin Deadman (University of Manchester and NAG Ltd.) discussing his poster on Matrix Functions and the NAG Library with Cleve Moler and Charlie Van Loan (authors of the classic  Josh Bloom’s (UC Berkeley) invited presentation
Josh Bloom’s (UC Berkeley) invited presentation  It was interesting to see MapReduce being used to implement numerical algorithms, notably in the minisymposium
It was interesting to see MapReduce being used to implement numerical algorithms, notably in the minisymposium  Here is the lunchtime panel
Here is the lunchtime panel  and
and  be distinct floating point numbers. How small can the relative difference between
be distinct floating point numbers. How small can the relative difference between 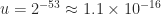 , which is called the unit roundoff.
, which is called the unit roundoff.  , where the infinity norm is
, where the infinity norm is  ? It does not seem to be well known that
? It does not seem to be well known that  can be much less than
can be much less than  . I have observed this phenomenon numerous times over the years but had not previously stopped to wonder how it could happen. An example is
. I have observed this phenomenon numerous times over the years but had not previously stopped to wonder how it could happen. An example is 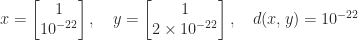 .
.  is possible.
is possible. 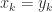 for all
for all  such that
such that  .
.
