Try the following quiz. Let 

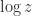
![(-\pi,\pi]](https://s0.wp.com/latex.php?latex=%28-%5Cpi%2C%5Cpi%5D&bg=ffffff&fg=222222&s=0&c=20201002)
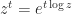



True or false:
for all
for all
whenever
commute.
The answers are
- False. Yet
is always true.
- True. Yet the similar identity
is false.
- False.
At first sight these results may seem rather strange. How can we understand them? If you take the viewpoint that each occurrence of 

An excellent tool for understanding these identities is a new matrix function called the matrix unwinding function. This function is defined for any square matrix 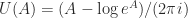

From the definition we have 
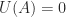
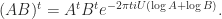
Mary Aprahamian and I have recently published the paper The Matrix Unwinding Function, with an Application to Computing the Matrix Exponential, (SIAM J. Matrix. Anal. Appl., 35, 88-109, 2014), in which we introduce the matrix unwinding function and develop its many interesting properties. We analyze the identities discussed above, along with various others. Thanks to the University of Manchester’s Open Access funds, that paper is available for anyone to download from the SIAM website, using the given link.
The matrix unwinding function has another use. Note that 

How can we compute 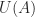
function U = unwindm(A,flag)
%UNWINDM Matrix unwinding function.
% UNWINDM(A) is the matrix unwinding function of the square matrix A.
% Reference: M. Aprahamian and N. J. Higham.
% The matrix unwinding function, with an application to computing the
% matrix exponential. SIAM J. Matrix Anal. Appl., 35(1):88-109, 2014.
% Mary Aprahamian and Nicholas J. Higham, 2013.
if nargin < 2, flag = 1; end
[Q,T] = schur(A,'complex');
ord = blocking(T);
[ord, ind] = swapping(ord); % Gives the blocking.
ord = max(ord)-ord+1; % Since ORDSCHUR puts highest index top left.
[Q,T] = ordschur(Q,T,ord);
U = Q * unwindm_tri(T) * Q';
%%%%%%%%%%%%%%%%%%%%%%%%%%%
function F = unwindm_tri(T)
%UNWINDM_tri Unwinding matrix of upper triangular matrix.
n = length(T);
F = diag( unwind( diag(T) ) );
% Compute off-diagonal of F by scalar Parlett recurrence.
for j=2:n
for i = j-1:-1:1
if F(i,i) == F(j,j)
F(i,j) = 0; % We're within a diagonal block.
else
s = T(i,j)*(F(i,i)-F(j,j));
if j-i >= 2
k = i+1:j-1;
s = s + F(i,k)*T(k,j) - T(i,k)*F(k,j);
end
F(i,j) = s/(T(i,i)-T(j,j));
end
end
end
%%%%%%%%%%%%%%%%%%%%%%
function u = unwind(z)
%UNWIND Unwinding number.
% UNWIND(A) is the (scalar) unwinding number.
u = ceil( (imag(z) - pi)/(2*pi) );
... Other subfunctions omitted
Here is an example. As it illustrates, the unwinding matrix of a real matrix is usually pure imaginary.
>> A = [1 4; -1 1]*4, U = unwindm(A)
A =
4 16
-4 4
U =
0.0000 + 0.0000i 0.0000 - 2.0000i
0.0000 + 0.5000i -0.0000 + 0.0000i
>> residual = A - logm(expm(A))
residual =
-0.0000 12.5664
-3.1416 -0.0000
>> residual - 2*pi*i*U
ans =
1.0e-15 *
-0.8882 + 0.0000i 0.0000 + 0.0000i
-0.8882 + 0.0000i -0.8882 + 0.3488i


 , like the first edition, but now using the Computer Modern fonts, which I feel give better readability than the font used previously.
, like the first edition, but now using the Computer Modern fonts, which I feel give better readability than the font used previously.