When Cayley introduced matrix algebra in 1858, he did much more than merely arrange numbers in a rectangular array. His definitions of addition, multiplication, and inversion produced an algebraic structure that has proved to be immensely useful, and which still holds many mysteries today.
An  matrix has
matrix has 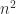 parameters, so the vector space
parameters, so the vector space 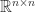 of real matrices has dimension , with a basis given by the matrices
of real matrices has dimension , with a basis given by the matrices 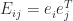 , where
, where 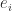 is the vector that is zero except for a
is the vector that is zero except for a  in the
in the  th entry. In his original paper, Cayley noticed the important property that the powers of a particular matrix
th entry. In his original paper, Cayley noticed the important property that the powers of a particular matrix  can never span . The Cayley–Hamilton theorem says that satisfies its own characteristic equation, that is,
can never span . The Cayley–Hamilton theorem says that satisfies its own characteristic equation, that is, 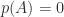 where
where 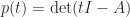 is the characteristic polynomial of . This means that
is the characteristic polynomial of . This means that 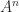 can be expressed as a linear combination of
can be expressed as a linear combination of  , , …,
, , …, 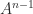 , so the powers of span a vector space of dimension at most
, so the powers of span a vector space of dimension at most  .
.
Gerstenhaber proved a generalization of this property in 1961: if and  are two commuting matrices then the matrices
are two commuting matrices then the matrices 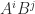 , for all nonnegative and
, for all nonnegative and  , generate a vector space of dimension at most . This result is much more difficult to prove than the Cayley–Hamilton theorem. Gerstenhaber’s proof was based on algebraic geometry, but purely matrix-theoretic proofs have been given.
, generate a vector space of dimension at most . This result is much more difficult to prove than the Cayley–Hamilton theorem. Gerstenhaber’s proof was based on algebraic geometry, but purely matrix-theoretic proofs have been given.
A natural question, called the Gerstenhaber problem, is: does this result extend to three matrices, that is, does the vector space

have dimension at most for any matrices , , and  that commute with each other? (We can limit the powers to
that commute with each other? (We can limit the powers to  by the Cayley–Hamilton theorem.) The problem is defined over any field, but here I focus on the reals.
by the Cayley–Hamilton theorem.) The problem is defined over any field, but here I focus on the reals.
Before considering the three matrix case let us note that the answer is known to be “no” for four commuting  matrices , , , and
matrices , , , and  . Indeed let
. Indeed let

and note that all possible products of two of these matrices are zero, so the matrices commute pairwise. Yet 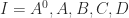 are clearly five linearly independent matrices. Hence Gerstenhaber’s result does not extend to four matrices. It also does not extend to five or more matrices because it is known that the failure of the result for one value of implies failure for all larger . The question, then, is whether the three matrix case is like the two matrix case or the case for four or more matrices.
are clearly five linearly independent matrices. Hence Gerstenhaber’s result does not extend to four matrices. It also does not extend to five or more matrices because it is known that the failure of the result for one value of implies failure for all larger . The question, then, is whether the three matrix case is like the two matrix case or the case for four or more matrices.
A great deal of effort has been put into proving or disproving the Gerstenhaber problem, so far without success. Here are two known facts.
- The result holds for all
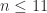 .
.
- By a 1905 result of Schur, the dimension of
 is at most
is at most  , which is less than but still much bigger than . (Here,
, which is less than but still much bigger than . (Here,  is the floor function.)
is the floor function.)
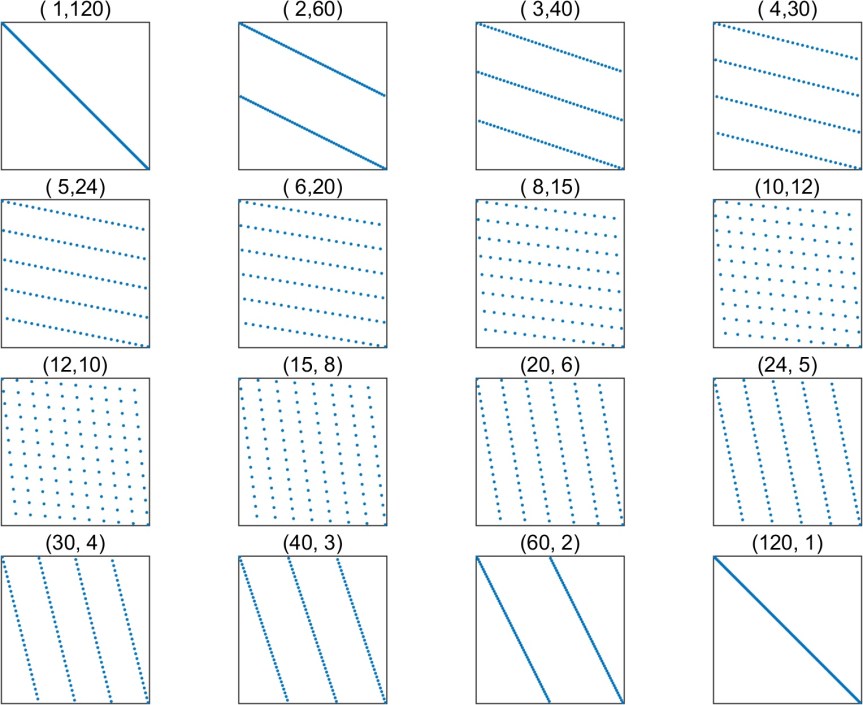
One approach to investigating this problem is to look for a counterexample computationally. For some 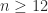 , choose three commuting matrices , , and , select
, choose three commuting matrices , , and , select 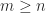 monomials
monomials
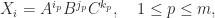
form the matrix
![Y = [\mathrm{vec}(X_1), \mathrm{vec}(X_2), \dots, \mathrm{vec}(X_m)],](https://s0.wp.com/latex.php?latex=Y+%3D+%5B%5Cmathrm%7Bvec%7D%28X_1%29%2C+++++++++++++%5Cmathrm%7Bvec%7D%28X_2%29%2C+%5Cdots%2C+++++++++++++%5Cmathrm%7Bvec%7D%28X_m%29%5D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
where 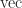 converts a matrix into a vector by stacking the columns on top of each other, then compute
converts a matrix into a vector by stacking the columns on top of each other, then compute  , which is a lower bound on
, which is a lower bound on 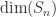 , and check whether it is greater than .
, and check whether it is greater than .
This simple-minded approach has some obvious difficulties. How do we choose , , and ? How do we choose the powers? How do we avoid overflow and underflow and compute a reliable rank, given that we might be dealing with large powers of large matrices?
Holbrook and O’Meara (2020), who have written several papers on the Gerstenhaber problem, which they call the GP problem, state that they “firmly believe the GP will turn out to have a negative answer” and they have developed a sophisticated approach to searching for a case with 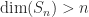 , which they call a “Eureka”. They first note that , and can be assumed to be nilpotent. This means that all three matrices must be defective, because a nondefective nilpotent matrix is zero. Next they note that since commuting matrices are simultaneously unitarily triangularizable, , , and can be assumed to be strictly upper triangular. Then they note that can be assumed to be in Weyr canonical form.
, which they call a “Eureka”. They first note that , and can be assumed to be nilpotent. This means that all three matrices must be defective, because a nondefective nilpotent matrix is zero. Next they note that since commuting matrices are simultaneously unitarily triangularizable, , , and can be assumed to be strictly upper triangular. Then they note that can be assumed to be in Weyr canonical form.
The Weyr canonical form is a dual of the Jordan canonical form in which the Jordan matrix is replaced by a Weyr matrix, which is a direct sum of basic Weyr matrices. A basic Weyr matrix has one distinct eigenvalue and is upper block bidiagonal with diagonal blocks that are multiples of the identity matrix and superdiagonal blocks that are rectangular identity matrices. The difference between Jordan and Weyr matrices is illustrated by the example
![J(\lambda) = \left[\begin{array}{ccc|cc} \lambda & 1 & 0 &&\\ 0 & \lambda & 1 &&\\ 0 & 0 & \lambda &&\\\hline & & &\lambda & 1\\ & & & 0 &\lambda \end{array}\right], \quad W(\lambda) = \left[\begin{array}{cc|cc|c} \lambda & 0 & 1 & 0&\\ 0 & \lambda & 0 & 1&\\\hline & & \lambda & 0 &1\\ & & 0 &\lambda & 0\\\hline & & & 0 &\lambda \end{array}\right],](https://s0.wp.com/latex.php?latex=J%28%5Clambda%29+%3D+++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bccc%7Ccc%7D+++++%5Clambda+%26++1++++++%26+0+%26%26%5C%5C+++++0+++++++%26+%5Clambda+%26+1+%26%26%5C%5C+++++0+++++++%26+0+++++++%26+%5Clambda+%26%26%5C%5C%5Chline+++++++++++++%26+++++++++%26+++%26%5Clambda+%26+1%5C%5C+++++++++++++%26+++++++++%26+++%26+0+%26%5Clambda++++++%5Cend%7Barray%7D%5Cright%5D%2C+%5Cquad+++++W%28%5Clambda%29+%3D+++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7Ccc%7Cc%7D+++++%5Clambda+%26++0++++++%26+1+%26+0%26%5C%5C+++++0+++++++%26+%5Clambda+%26+0+%26+1%26%5C%5C%5Chline+++++++++++++%26+++++++++%26+%5Clambda+%26+0+%261%5C%5C+++++++++++++%26+++++++++%26+0++%26%5Clambda+%26+0%5C%5C%5Chline+++++++++++++%26+++++++++%26+++%26+0+%26%5Clambda++++++%5Cend%7Barray%7D%5Cright%5D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
where the Jordan matrix 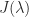 and Weyr matrix
and Weyr matrix 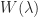 are related by
are related by 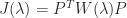 for some permutation matrix
for some permutation matrix  . There is an elegant way of relating the block sizes in the Jordan and Weyr matrices via a Young diagram. Form an array whose
. There is an elegant way of relating the block sizes in the Jordan and Weyr matrices via a Young diagram. Form an array whose  th column contains
th column contains  dots, where is the size of the th diagonal block of
dots, where is the size of the th diagonal block of 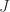 :
:
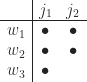
Then the number of dots in the th row is the size of the th diagonal block in the Weyr form.
The reason for using the Weyr form is that whereas any matrix that commutes with a Jordan matrix has Toeplitz blocks, any matrix that commutes with a Weyr matrix is block upper triangular and is uniquely determined by the first block row. By choosing a Weyr form for , commuting matrices and can be built up in a systematic way.
Thanks to a result of O’Meara (2020) it suffices to compute modulo a prime  , so the computations can be done in exact arithmetic, removing the need to worry about rounding errors or overflow.
, so the computations can be done in exact arithmetic, removing the need to worry about rounding errors or overflow.
Holbrook and O’Meara have mostly tried matrices up to dimension 50, but they feel that “the Loch Ness monster probably lives in deeper water, closer to  ”. Their MATLAB codes (40 nicely commented but not optimized M-files) are available on request from the address given in their preprint. If you have the time to spare you might want to experiment with the codes and try to find a Eureka.
”. Their MATLAB codes (40 nicely commented but not optimized M-files) are available on request from the address given in their preprint. If you have the time to spare you might want to experiment with the codes and try to find a Eureka.
References
This is a minimal set of references, which contain further useful references within.
- Robert M. Corless and Steven E. Thornton, The Weyr Canonical Form, 2016 (PDF poster).
- John Holbrook and Kevin O’Meara, A Computing Strategy and Programs to Resolve the Gerstenhaber Problem for Commuting Triples of Matrices, ArXiv:2006.085882020, 2020.
- John Holbrook and Kevin O’Meara, Commuting Triples of Matrices Vs the Computer, IMAGE (The Bulletin of the International Linear Algebra Society), to appear.
- Kevin O’Meara, The Gerstenhaber Problem for Commuting Triples of Matrices is “Decidable”, Comm. Algebra 48, 453–466, 2020.
- Kevin O’Meara, John Clark, and Charles Vinsonhaler, Advanced Topics in Linear Algebra. Weaving Matrix Problems Through the Weyr Form, Oxford University Press, Oxford, UK. 2011. Chapter 5.
- B. A. Sethuraman, the Algebra Generated by Three Commuting Matrices, Math. Newsl. 21, 62–67, 2011.
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
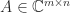

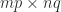

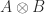
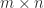

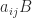
![\begin{bmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \end{bmatrix} \otimes \begin{bmatrix} b_{11} & b_{12} & b_{13} \\ b_{21} & b_{22} & b_{23} \end{bmatrix} = \left[\begin{array}{ccc|ccc} a_{11}b_{11} & a_{11}b_{12} & a_{11}b_{13} & a_{12}b_{11} & a_{12}b_{12} & a_{12}b_{13} \\ a_{11}b_{21} & a_{11}b_{22} & a_{11}b_{23} & a_{12}b_{21} & a_{12}b_{22} & a_{12}b_{23} \\\hline a_{21}b_{11} & a_{21}b_{12} & a_{21}b_{13} & a_{22}b_{11} & a_{22}b_{12} & a_{22}b_{13} \\ a_{21}b_{21} & a_{21}b_{22} & a_{21}b_{23} & a_{22}b_{21} & a_{22}b_{22} & a_{22}b_{23} \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cbegin%7Bbmatrix%7D+a_%7B11%7D+%26+a_%7B12%7D+%5C%5C+a_%7B21%7D+%26+a_%7B22%7D+%5Cend%7Bbmatrix%7D+%5Cotimes+%5Cbegin%7Bbmatrix%7D+b_%7B11%7D+%26+b_%7B12%7D+%26+b_%7B13%7D+%5C%5C+b_%7B21%7D+%26+b_%7B22%7D+%26+b_%7B23%7D+%5Cend%7Bbmatrix%7D+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bccc%7Cccc%7D+a_%7B11%7Db_%7B11%7D+%26+a_%7B11%7Db_%7B12%7D+%26+a_%7B11%7Db_%7B13%7D+%26+a_%7B12%7Db_%7B11%7D+%26+a_%7B12%7Db_%7B12%7D+%26+a_%7B12%7Db_%7B13%7D+%5C%5C+a_%7B11%7Db_%7B21%7D+%26+a_%7B11%7Db_%7B22%7D+%26+a_%7B11%7Db_%7B23%7D+%26+a_%7B12%7Db_%7B21%7D+%26+a_%7B12%7Db_%7B22%7D+%26+a_%7B12%7Db_%7B23%7D+%5C%5C%5Chline+a_%7B21%7Db_%7B11%7D+%26+a_%7B21%7Db_%7B12%7D+%26+a_%7B21%7Db_%7B13%7D+%26+a_%7B22%7Db_%7B11%7D+%26+a_%7B22%7Db_%7B12%7D+%26+a_%7B22%7Db_%7B13%7D+%5C%5C+a_%7B21%7Db_%7B21%7D+%26+a_%7B21%7Db_%7B22%7D+%26+a_%7B21%7Db_%7B23%7D+%26+a_%7B22%7Db_%7B21%7D+%26+a_%7B22%7Db_%7B22%7D+%26+a_%7B22%7Db_%7B23%7D+%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)

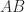
of the products
and contains all
products


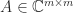

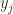
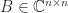

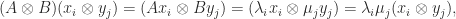





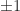
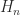


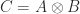
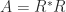








![A = [a_1,a_2,\dots,a_m]](https://s0.wp.com/latex.php?latex=A+%3D+%5Ba_1%2Ca_2%2C%5Cdots%2Ca_m%5D&bg=ffffff&fg=222222&s=0&c=20201002)
![\mathrm{vec}(A) = [a_1^T a_2^T \dots a_m^T]^T](https://s0.wp.com/latex.php?latex=%5Cmathrm%7Bvec%7D%28A%29+%3D+%5Ba_1%5ET+a_2%5ET+%5Cdots+a_m%5ET%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002)




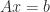
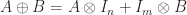


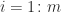
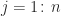







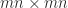




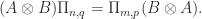




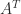

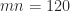




 , where
, where  (
(![G_4 = \left[\begin{array}{cccc} 1 & 1 & 1 & 1\\ 1 & 2 & 1 & 2\\ 1 & 1 & 3 & 1\\ 1 & 2 & 1 & 4 \end{array}\right] = \left[\begin{array}{cccc} 1 & 0 & 0 & 0\\ 1 & 1 & 0 & 0\\ 1 & 0 & \sqrt{2} & 0\\ 1 & 1 & 0 & \sqrt{2} \end{array}\right] \left[\begin{array}{cccc} 1 & 1 & 1 & 1\\ 0 & 1 & 0 & 1\\ 0 & 0 & \sqrt{2} & 0\\ 0 & 0 & 0 & \sqrt{2} \end{array}\right].](https://s0.wp.com/latex.php?latex=G_4+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccc%7D+1+%26+1+%26+1+%26+1%5C%5C+1+%26+2+%26+1+%26+2%5C%5C+1+%26+1+%26+3+%26+1%5C%5C+1+%26+2+%26+1+%26+4+%5Cend%7Barray%7D%5Cright%5D+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccc%7D+1+%26+0+%26+0+%26+0%5C%5C+1+%26+1+%26+0+%26+0%5C%5C+1+%26+0+%26+%5Csqrt%7B2%7D+%26+0%5C%5C+1+%26+1+%26+0+%26+%5Csqrt%7B2%7D+%5Cend%7Barray%7D%5Cright%5D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccc%7D+1+%26+1+%26+1+%26+1%5C%5C+0+%26+1+%26+0+%26+1%5C%5C+0+%26+0+%26+%5Csqrt%7B2%7D+%26+0%5C%5C+0+%26+0+%26+0+%26+%5Csqrt%7B2%7D+%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
 ,
,  , where
, where  is the leading principal submatrix of order
is the leading principal submatrix of order 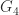 with
with  ,
, ![\bigl[\begin{smallmatrix}1 & 1\\ 1& 2\end{smallmatrix}\bigr]= \bigl[\begin{smallmatrix}1 & 0\\ 1& 1\end{smallmatrix}\bigr] \bigl[\begin{smallmatrix}1 & 1\\ 0& 1\end{smallmatrix}\bigr]](https://s0.wp.com/latex.php?latex=%5Cbigl%5B%5Cbegin%7Bsmallmatrix%7D1+%26+1%5C%5C+1%26+2%5Cend%7Bsmallmatrix%7D%5Cbigr%5D%3D++%5Cbigl%5B%5Cbegin%7Bsmallmatrix%7D1+%26+0%5C%5C+1%26+1%5Cend%7Bsmallmatrix%7D%5Cbigr%5D++%5Cbigl%5B%5Cbegin%7Bsmallmatrix%7D1+%26+1%5C%5C+0%26+1%5Cend%7Bsmallmatrix%7D%5Cbigr%5D&bg=ffffff&fg=222222&s=0&c=20201002) .
.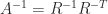 , which implies the interesting relation that the
, which implies the interesting relation that the  element of
element of  is
is  . So
. So 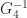 has
has 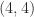 element
element 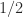 . We also have
. We also have  , so
, so 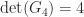 for this matrix.
for this matrix. as
as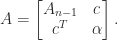
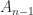 is positive definite (any principal submatrix of a positive definite matrix is easily shown to be positive definite). Assume that
is positive definite (any principal submatrix of a positive definite matrix is easily shown to be positive definite). Assume that  and define the upper triangular matrix
and define the upper triangular matrix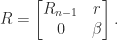
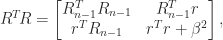

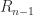 is nonsingular. Then the second equation gives
is nonsingular. Then the second equation gives 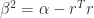 . It remains to check that there is a unique real, positive
. It remains to check that there is a unique real, positive 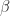 satisfying this equation. From the inequality
satisfying this equation. From the inequality
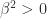 , hence there is a unique
, hence there is a unique  . This completes the inductive step.
. This completes the inductive step. is the Schur complement of
is the Schur complement of 
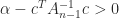 .
.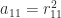 , then the following algorithm is obtained:
, then the following algorithm is obtained:
 and on the next iteration of the loop we will have a division by zero. In floating-point arithmetic it is possible for the algorithm to fail for a positive definite matrix, but only if it is numerically singular: the algorithm is guaranteed to run to completion if the condition number
and on the next iteration of the loop we will have a division by zero. In floating-point arithmetic it is possible for the algorithm to fail for a positive definite matrix, but only if it is numerically singular: the algorithm is guaranteed to run to completion if the condition number 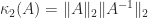 is safely less than
is safely less than 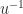 , where
, where  is the unit roundoff.
is the unit roundoff. such that
such that  . Here is an example. The code
. Here is an example. The code satisfies
satisfies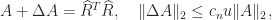
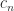 is a constant. Unlike for LU factorization there is no possibility of element growth; indeed for
is a constant. Unlike for LU factorization there is no possibility of element growth; indeed for 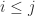 ,
,
 , by solving the lower triangular system
, by solving the lower triangular system  and then the upper triangular system
and then the upper triangular system 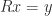 . The computed solution
. The computed solution 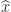 can be shown to satisfy
can be shown to satisfy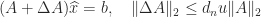
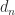 is another constant. Thus
is another constant. Thus  for all
for all  , so that
, so that ![A = \left[\begin{array}{cccc} 1 & 1 & 1 & 1\\ 1 & 1 & 1 & 1\\ 1 & 1 & 2 & 2\\ 1 & 1 & 2 & 4\\ \end{array}\right] = \left[\begin{array}{cccc} 1 & 0 & 0 & 0\\ 1 & 0 & 0 & 0\\ 1 & 1 & 0 & 0\\ 1 & 1 & x & y\\ \end{array}\right] \left[\begin{array}{cccc} 1 & 1 & 1 & 1\\ 0 & 0 & 1 & 1\\ 0 & 0 & 0 & x\\ 0 & 0 & 0 & y\\ \end{array}\right] = R^T\!R](https://s0.wp.com/latex.php?latex=A+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccc%7D++1+%26+1+%26+1+%26+1%5C%5C++1+%26+1+%26+1+%26+1%5C%5C++1+%26+1+%26+2+%26+2%5C%5C++1+%26+1+%26+2+%26+4%5C%5C+%5Cend%7Barray%7D%5Cright%5D+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccc%7D+1+%26+0+%26+0+%26+0%5C%5C+1+%26+0+%26+0+%26+0%5C%5C+1+%26+1+%26+0+%26+0%5C%5C+1+%26+1+%26+x+%26+y%5C%5C+%5Cend%7Barray%7D%5Cright%5D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccc%7D+1+%26+1+%26+1+%26+1%5C%5C+0+%26+0+%26+1+%26+1%5C%5C+0+%26+0+%26+0+%26+x%5C%5C+0+%26+0+%26+0+%26+y%5C%5C+%5Cend%7Barray%7D%5Cright%5D++%3D+R%5ET%5C%21R+&bg=ffffff&fg=222222&s=0&c=20201002)
 such that
such that 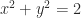 . Note that
. Note that  what is usually wanted is a Cholesky factorization in which
what is usually wanted is a Cholesky factorization in which  rows. Such a factorization can be obtained by using complete pivoting, which at each stage permutes the largest remaining diagonal element into the pivot position, which gives a factorization
rows. Such a factorization can be obtained by using complete pivoting, which at each stage permutes the largest remaining diagonal element into the pivot position, which gives a factorization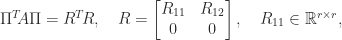
 is a permutation matrix. For example, with
is a permutation matrix. For example, with ![\Pi^T\mskip-5mu A\Pi = \left[\begin{array}{cccc} 4 & 2 & 1 & 1\\ 2 & 2 & 1 & 1\\ 1 & 1 & 1 & 1\\ 1 & 1 & 1 & 1 \end{array}\right] = \left[\begin{array}{cccc} 2 & 0 & 0 & 0\\ 1 & 1 & 0 & 0\\ \frac{1}{2} & \frac{1}{2} & \frac{\sqrt{2}}{2} & 0\\[2pt] \frac{1}{2} & \frac{1}{2} & \frac{\sqrt{2}}{2} & 0 \end{array}\right] \left[\begin{array}{cccc} 2 & 1 & \frac{1}{2} & \frac{1}{2}\\[2pt] 0 & 1 & \frac{1}{2} & \frac{1}{2}\\[2pt] 0 & 0 & \frac{\sqrt{2}}{2} & \frac{\sqrt{2}}{2}\\ 0 & 0 & 0 & 0 \end{array}\right],](https://s0.wp.com/latex.php?latex=%5CPi%5ET%5Cmskip-5mu+A%5CPi++%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccc%7D+4+%26+2+%26+1+%26+1%5C%5C+2+%26+2+%26+1+%26+1%5C%5C+1+%26+1+%26+1+%26+1%5C%5C+1+%26+1+%26+1+%26+1+%5Cend%7Barray%7D%5Cright%5D++++%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccc%7D+2+%26+0+%26+0+%26+0%5C%5C+1+%26+1+%26+0+%26+0%5C%5C+%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B%5Csqrt%7B2%7D%7D%7B2%7D+%26+0%5C%5C%5B2pt%5D+%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B%5Csqrt%7B2%7D%7D%7B2%7D+%26+0+%5Cend%7Barray%7D%5Cright%5D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccc%7D+2+%26+1+%26+%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B1%7D%7B2%7D%5C%5C%5B2pt%5D+0+%26+1+%26+%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B1%7D%7B2%7D%5C%5C%5B2pt%5D+0+%26+0+%26+%5Cfrac%7B%5Csqrt%7B2%7D%7D%7B2%7D+%26+%5Cfrac%7B%5Csqrt%7B2%7D%7D%7B2%7D%5C%5C+0+%26+0+%26+0+%26+0+%5Cend%7Barray%7D%5Cright%5D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
 of a scalar
of a scalar  to
to 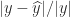 . The backward error of
. The backward error of 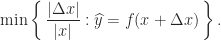
 for a modest constant
for a modest constant  , where
, where 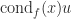 , where
, where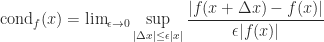
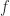 at
at 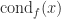 implies that a backward stable algorithm is automatically forward stable. The converse is not true. An example of an algorithm that is forward stable but not backward stable is Gauss–Jordan elimination for solving a linear system.
implies that a backward stable algorithm is automatically forward stable. The converse is not true. An example of an algorithm that is forward stable but not backward stable is Gauss–Jordan elimination for solving a linear system.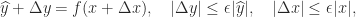
 small in the sense described above, then the algorithm for computing
small in the sense described above, then the algorithm for computing 
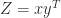 , where
, where  to satisfy
to satisfy  for some small
for some small 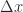 and
and 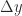 , meaning that
, meaning that  , or both. For a nonlinear function we need to consider whether problem parameters are data; for example, for
, or both. For a nonlinear function we need to consider whether problem parameters are data; for example, for 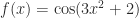 are the
are the 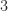 and the
and the  constants or are they data, like
constants or are they data, like 