The Hilbert matrix 


![H_4 = \left[\begin{array}{@{\mskip 5mu}c*{3}{@{\mskip 15mu} c}@{\mskip 5mu}} 1 & \frac{1}{2} & \frac{1}{3} & \frac{1}{4} \\[6pt] \frac{1}{2} & \frac{1}{3} & \frac{1}{4} & \frac{1}{5}\\[6pt] \frac{1}{3} & \frac{1}{4} & \frac{1}{5} & \frac{1}{6}\\[6pt] \frac{1}{4} & \frac{1}{5} & \frac{1}{6} & \frac{1}{7}\\[6pt] \end{array}\right].](https://s0.wp.com/latex.php?latex=H_4+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip+5mu%7Dc%2A%7B3%7D%7B%40%7B%5Cmskip+15mu%7D+c%7D%40%7B%5Cmskip+5mu%7D%7D+++++++++++++1+%26+%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B1%7D%7B3%7D++%26+%5Cfrac%7B1%7D%7B4%7D++%5C%5C%5B6pt%5D++++++++++++%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B1%7D%7B3%7D+++%26+%5Cfrac%7B1%7D%7B4%7D+++%26+%5Cfrac%7B1%7D%7B5%7D%5C%5C%5B6pt%5D++++++++++++%5Cfrac%7B1%7D%7B3%7D+%26+%5Cfrac%7B1%7D%7B4%7D+++%26++++++%5Cfrac%7B1%7D%7B5%7D+++%26+%5Cfrac%7B1%7D%7B6%7D%5C%5C%5B6pt%5D++++++++++++%5Cfrac%7B1%7D%7B4%7D+%26+%5Cfrac%7B1%7D%7B5%7D+++%26++++++%5Cfrac%7B1%7D%7B6%7D+++%26+%5Cfrac%7B1%7D%7B7%7D%5C%5C%5B6pt%5D++++++++++++%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
It is probably the most famous test matrix and its conditioning and other properties were extensively studied in the early days of digital computing, especially by John Todd.
The Hilbert matrix is symmetric and it is a Hankel matrix (constant along the anti-diagonals). Less obviously, it is symmetric positive definite (all its eigenvalues are positive) and totally positive (every submatrix has positive determinant). Its condition number grows rapidly with 

The inverse of 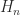


For example,
![H_4^{-1} = \left[\begin{array}{rrrr} 16 & -120 & 240 & -140 \\ -120 & 1200 & -2700 & 1680 \\ 240 & -2700 & 6480 & -4200 \\ -140 & 1680 & -4200 & 2800 \\ \end{array}\right].](https://s0.wp.com/latex.php?latex=H_4%5E%7B-1%7D+%3D+++++%5Cleft%5B%5Cbegin%7Barray%7D%7Brrrr%7D++++++16+%26+-120+%26+240+%26+-140+%5C%5C++++++-120+%26+1200+%26+-2700+%26+1680+%5C%5C++++++240+%26+-2700+%26+6480+%26+-4200+%5C%5C++++++-140+%26+1680+%26+-4200+%26+2800+%5C%5C++++++%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
The alternating sign pattern is a consequence of total positivity.
The determinant is also known explicitly:

The Hilbert matrix is infinitely divisible, which means that the matrix with 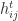

Other interesting matrices can be formed from the Hilbert matrix. The Lotkin matrix, A = gallery('lotkin',n) in MATLAB, is the Hilbert matrix with the first row replaced by 


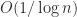
The Hilbert matrix is not a good test matrix, for several reasons. First, it is too ill conditioned, being numerically singular in IEEE double precision arithmetic for 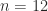


MATLAB has functions hilb and invhilb for the Hilbert matrix and its inverse. How to efficiently form the Hilbert matrix in MATLAB is an interesting question. The hilb function essentially uses the code
j = 1:n; H = 1./(j'+j-1)
This code is more concise and efficient than two nested loops would be. The second line may appear to be syntactically incorrect, because j'+j adds a column vector to a row vector. However, the MATLAB implicit expansion feature expands j' into an j', expands j into an j, then adds the two matrices. It is not hard to see that the Hilbert matrix is the result of these two lines of code.
References
This is a minimal set of references, which contain further useful references within.
- Rajendra Bhatia, Infinitely divisible matrices, Amer. Math. Monthly 113(3), 221–235, 2006.
- Man-Duen Choi, Tricks or treats with the Hilbert matrix, Amer. Math. Monthly 90(5), 301–312, 1983
- Nicholas J. Higham, Accuracy and Stability of Numerical Algorithms, second edition, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2002. Section 28.1.
- M. Lotkin, A set of test matrices, M.T.A.C. 9(52), 153–161, 1955.
Related Blog Posts
- Hilbert Matrices by Cleve Moler (2013)
- Hilbert Matrices by Cleve Moler (2017)
- Implicit Expansion: A Powerful New Feature of MATLAB R2016b (2016)
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
 and
and  be Banach spaces (complete normed vector spaces). The Fréchet derivative of a function
be Banach spaces (complete normed vector spaces). The Fréchet derivative of a function 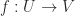 at
at  is a linear mapping
is a linear mapping  such that
such that
 . The notation
. The notation  should be read as “the Fréchet derivative of
should be read as “the Fréchet derivative of 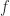 at
at  in the direction
in the direction 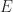 ”. The Fréchet derivative may not exist, but if it does exist then it is unique. When
”. The Fréchet derivative may not exist, but if it does exist then it is unique. When  , the Fréchet derivative is just the usual derivative of a scalar function:
, the Fréchet derivative is just the usual derivative of a scalar function:  .
. and
and  . From the expansion
. From the expansion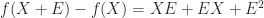
 , the first order part of the expansion. If
, the first order part of the expansion. If 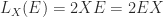 .
. with radius of convergence
with radius of convergence  then for
then for  with
with  , the Fréchet derivative is
, the Fréchet derivative is
 , is
, is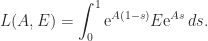
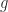 and
and  are Fréchet differentiable at
are Fréchet differentiable at  then
then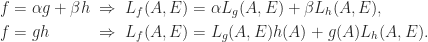
 given by
given by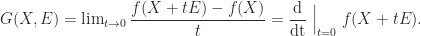

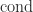 is given in terms of the Fréchet derivative by
is given in terms of the Fréchet derivative by

 are the divided differences
are the divided differences![\notag f[\lambda_i,\lambda_j] = \begin{cases} \dfrac{ f(\lambda_i)-f(\lambda_j) }{\lambda_i - \lambda_j}, & \lambda_i\ne\lambda_j, \\ f'(\lambda_i), & \lambda_i=\lambda_j, \end{cases}](https://s0.wp.com/latex.php?latex=%5Cnotag++++f%5B%5Clambda_i%2C%5Clambda_j%5D+%3D+%5Cbegin%7Bcases%7D++++%5Cdfrac%7B+f%28%5Clambda_i%29-f%28%5Clambda_j%29+%7D%7B%5Clambda_i+-+%5Clambda_j%7D%2C++++%26+%5Clambda_i%5Cne%5Clambda_j%2C+%5C%5C++++f%27%28%5Clambda_i%29%2C+%26+%5Clambda_i%3D%5Clambda_j%2C++++%5Cend%7Bcases%7D+&bg=ffffff&fg=222222&s=0&c=20201002)
 , where the
, where the  are the eigenvalues of
are the eigenvalues of  . Let
. Let 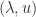 be an eigenpair of
be an eigenpair of 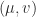 an eigenpair of
an eigenpair of  , so that
, so that  and
and 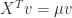 , and let
, and let  . Then
. Then
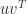 is an eigenvector of
is an eigenvector of 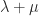 . But
. But ![f[\lambda,\mu] = (\lambda^2-\mu^2)/(\lambda - \mu) = \lambda + \mu](https://s0.wp.com/latex.php?latex=f%5B%5Clambda%2C%5Cmu%5D+%3D+%28%5Clambda%5E2-%5Cmu%5E2%29%2F%28%5Clambda+-+%5Cmu%29+%3D+%5Clambda+%2B+%5Cmu&bg=ffffff&fg=222222&s=0&c=20201002) (whether or not
(whether or not 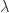 and
and  are distinct).
are distinct). packages that, while they are perhaps not among the best known, I have found to be very useful. All of them are probably available in your
packages that, while they are perhaps not among the best known, I have found to be very useful. All of them are probably available in your 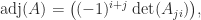
 denotes the submatrix of
denotes the submatrix of  and column
and column  . It is the transposed matrix of cofactors. The adjugate is sometimes called the (classical) adjoint and is sometimes written as
. It is the transposed matrix of cofactors. The adjugate is sometimes called the (classical) adjoint and is sometimes written as 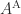 .
.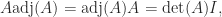
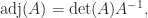
 in terms of determinants.
in terms of determinants.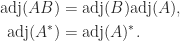
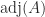 and the fact that every matrix is the limit of a sequence of nonsingular matrices. Another property that can be proved in a similar way is
and the fact that every matrix is the limit of a sequence of nonsingular matrices. Another property that can be proved in a similar way is
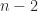 or less then
or less then  submatrix of
submatrix of 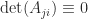 in the definition of
in the definition of  and
and  for any rank-1 matrix
for any rank-1 matrix 
 then
then 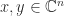 , then for nonsingular
, then for nonsingular 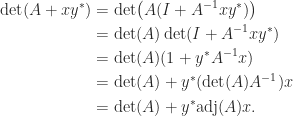


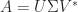 be an SVD, where
be an SVD, where 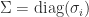 , with
, with 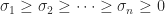 . Then
. Then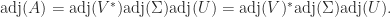
 is diagonal, with
is diagonal, with

 and so
and so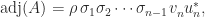
 has modulus
has modulus  and
and  are the last columns of
are the last columns of 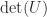 and
and  , so we must compute them. This function is numerically stable, as shown by Stewart (1998).
, so we must compute them. This function is numerically stable, as shown by Stewart (1998).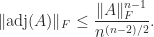
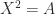 . Any square root
. Any square root 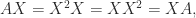
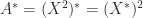 , so
, so  is a square root of
is a square root of 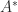 (here, the superscript
(here, the superscript  denotes the conjugate transpose).
denotes the conjugate transpose). we have
we have
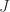 then we have
then we have  , so that
, so that 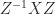 is a square root of
is a square root of 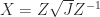 .
. of a square matrix
of a square matrix 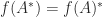 ,
, , where
, where  .
. satisfies all three conditions.)
satisfies all three conditions.) denotes the spectral radius. This definition is natural for functions that have a power series expansion, but it is rather limited in its applicability.
denotes the spectral radius. This definition is natural for functions that have a power series expansion, but it is rather limited in its applicability.
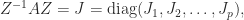
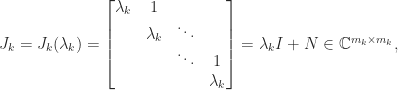
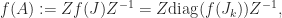

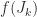 has the derivatives of
has the derivatives of  , where
, where  is zero apart from a superdiagonal of 1s. The formula for
is zero apart from a superdiagonal of 1s. The formula for 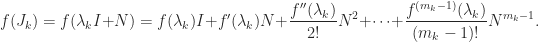
 : as
: as  we need the existence of the derivatives at
we need the existence of the derivatives at  with
with 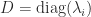 then
then 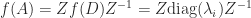 .
. that encloses the spectrum of
that encloses the spectrum of 
 , where
, where 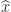 satisfies
satisfies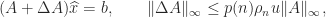
 is the unit roundoff and
is the unit roundoff and 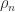 is the growth factor, defined by
is the growth factor, defined by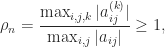
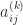 are the elements at the
are the elements at the  th stage of Gaussian elimination. The growth factor measures how much elements grow during the elimination. We would like the product
th stage of Gaussian elimination. The growth factor measures how much elements grow during the elimination. We would like the product  to be of order 1, so that
to be of order 1, so that 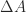 is a small relative perturbation of
is a small relative perturbation of 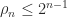 and that equality is possible. Such exponential growth implies a large
and that equality is possible. Such exponential growth implies a large 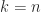 in the numerator in the definition), but it is entirely adequate for our purposes here. Let’s compute the growth factor for a random matrix of order 10,000 with elements from the standard normal distribution (mean 0, variance 1):
in the numerator in the definition), but it is entirely adequate for our purposes here. Let’s compute the growth factor for a random matrix of order 10,000 with elements from the standard normal distribution (mean 0, variance 1): times and 1e-6. Growth of 975 is exceptional! These matrices have been in MATLAB since the 1990s, but this large growth property has apparently not been noticed before.
times and 1e-6. Growth of 975 is exceptional! These matrices have been in MATLAB since the 1990s, but this large growth property has apparently not been noticed before. for any condition number and for any pivoting strategy, not just partial pivoting. One way to check this is to randomly permute the columns of
for any condition number and for any pivoting strategy, not just partial pivoting. One way to check this is to randomly permute the columns of 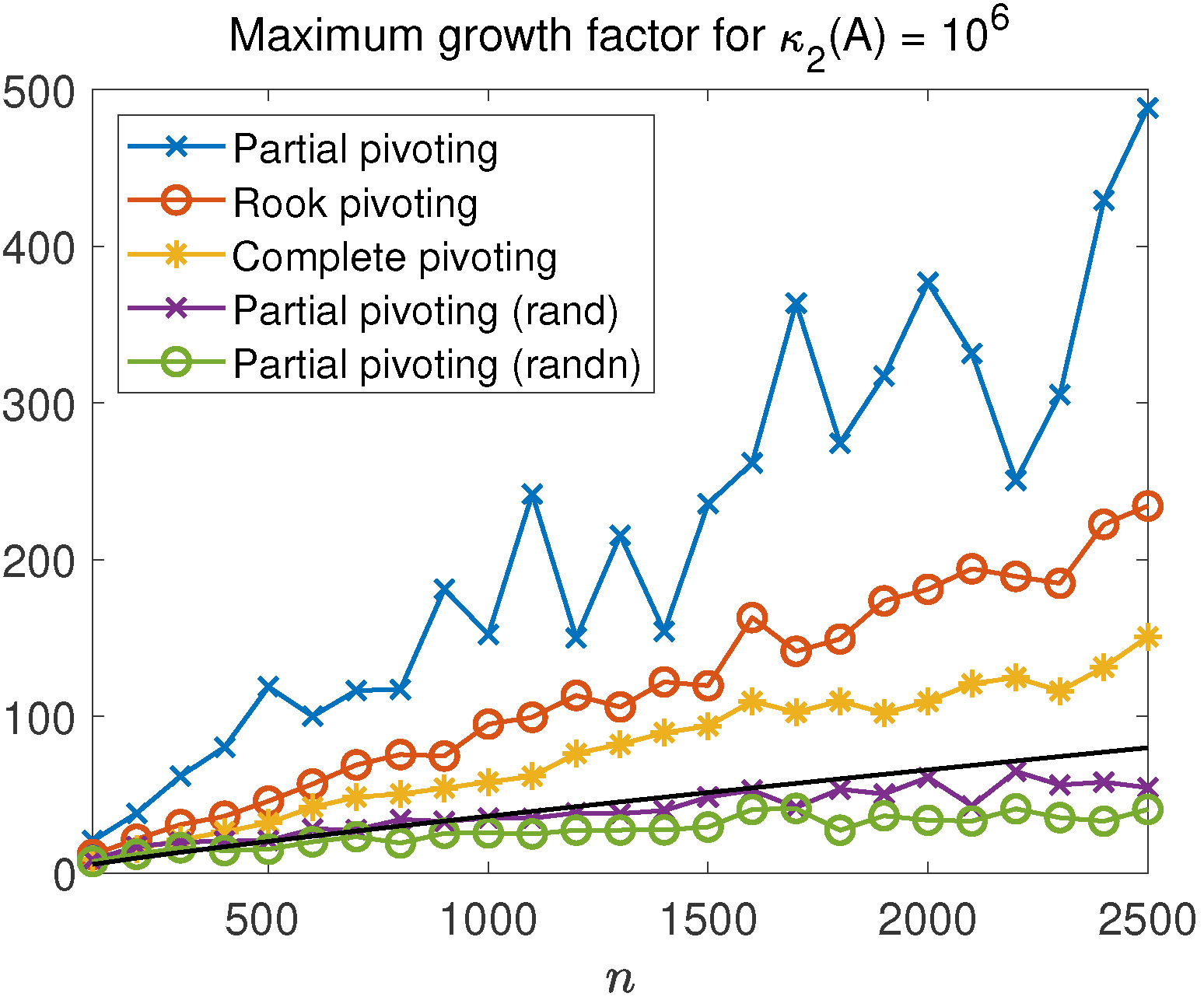
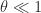 , then
, then 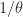 for any pivoting strategy. This was proved by Des Higham and I in the paper
for any pivoting strategy. This was proved by Des Higham and I in the paper  is an orthogonal matrix generating large growth then a rank-1 perturbation of 2-norm at most 1 tends to preserve the large growth.
is an orthogonal matrix generating large growth then a rank-1 perturbation of 2-norm at most 1 tends to preserve the large growth. . If we work in single precision then
. If we work in single precision then  and so LU factorization can potentially be completely unstable if there is growth of order
and so LU factorization can potentially be completely unstable if there is growth of order  . It was overflow in half precision LU factorization on randsvd matrices that alerted us to the large growth.
. It was overflow in half precision LU factorization on randsvd matrices that alerted us to the large growth.
 , where
, where 

 with 8-by-8
with 8-by-8  .
. and
and  and an fp32 number
and an fp32 number  and computes
and computes  at fp32 precision, returning an fp32 number.
at fp32 precision, returning an fp32 number.