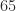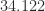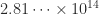Fp16 has the drawback for scientific computing of having a limited range, its largest positive number being  . This has led to the development of an alternative 16-bit format that trades precision for range. The bfloat16 format is used by Google in its tensor processing units. Intel, which plans to support bfloat16 in its forthcoming Nervana Neural Network Processor, has recently (November 2018) published a white paper that gives a precise definition of the format.
. This has led to the development of an alternative 16-bit format that trades precision for range. The bfloat16 format is used by Google in its tensor processing units. Intel, which plans to support bfloat16 in its forthcoming Nervana Neural Network Processor, has recently (November 2018) published a white paper that gives a precise definition of the format.
The allocation of bits to the exponent and significand for bfloat16, fp16, and fp32 is shown in this table, where the implicit leading bit of a normalized number is counted in the significand.
| Format |
Significand |
Exponent |
| bfloat16 |
8 bits |
8 bits |
| fp16 |
11 bits |
5 bits |
| fp32 |
24 bits |
8 bits |
Bfloat16 has three fewer bits in the significand than fp16, but three more in the exponent. And it has the same exponent size as fp32. Consequently, converting from fp32 to bfloat16 is easy: the exponent is kept the same and the significand is rounded or truncated from 24 bits to 8; hence overflow and underflow are not possible in the conversion.
On the other hand, when we convert from fp32 to the much narrower fp16 format overflow and underflow can readily happen, necessitating the development of techniques for rescaling before conversion—see the recent EPrint Squeezing a Matrix Into Half Precision, with an Application to Solving Linear Systems by me and Sri Pranesh.
The drawback of bfloat16 is its lesser precision: essentially 3 significant decimal digits versus 4 for fp16. The next table shows the unit roundoff  , smallest positive (subnormal) number xmins, smallest normalized positive number xmin, and largest finite number xmax for the three formats.
, smallest positive (subnormal) number xmins, smallest normalized positive number xmin, and largest finite number xmax for the three formats.
| |
|
xmins |
xmin |
xmax |
| bfloat16 |
3.91e-03 |
(*) |
1.18e-38 |
3.39e+38 |
| fp16 |
4.88e-04 |
5.96e-08 |
6.10e-05 |
6.55e+04 |
| fp32 |
5.96e-08 |
1.40e-45 |
1.18e-38 |
3.40e+38 |
(*) Unlike the fp16 format, Intel’s bfloat16 does not support subnormal numbers. If subnormal numbers were supported in the same way as in IEEE arithmetic, xmins would be 9.18e-41.
The values in this table (and those for fp64 and fp128) are generated by the MATLAB function float_params that I have made available on GitHub and at MathWorks File Exchange.


 . The series diverges, but when summed in the natural order in floating-point arithmetic it converges, because the partial sums grow while the addends decrease and eventually the addend is small enough that it does not change the partial sum. Here is a table showing the computed sum of the harmonic series for different precisions, along with how many terms are added before the sum becomes constant.
. The series diverges, but when summed in the natural order in floating-point arithmetic it converges, because the partial sums grow while the addends decrease and eventually the addend is small enough that it does not change the partial sum. Here is a table showing the computed sum of the harmonic series for different precisions, along with how many terms are added before the sum becomes constant.