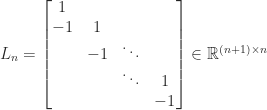
The second difference matrix is the tridiagonal matrix 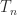


![\notag T_n = \left[ \begin{array}{@{}*{4}{r@{\mskip10mu}}r} 2 & -1 & & & \\ -1 & 2 & -1 & & \\[-5pt] & -1 & 2 & \ddots & \\ & & \ddots & \ddots & -1 \\ & & & -1 & 2 \end{array}\right] \in\mathbb{R}^{n\times n}.](https://s0.wp.com/latex.php?latex=%5Cnotag++++T_n+%3D+%5Cleft%5B++++%5Cbegin%7Barray%7D%7B%40%7B%7D%2A%7B4%7D%7Br%40%7B%5Cmskip10mu%7D%7Dr%7D+++++++++++++++++2++%26+-1+%26++++++++%26++++++++%26++++%5C%5C+++++++++++++++++-1+%26+2++%26+-1+++++%26++++++++%26++++%5C%5C%5B-5pt%5D++++++++++++++++++++%26+-1+%26+2++++++%26+%5Cddots+%26++++%5C%5C++++++++++++++++++++%26++++%26+%5Cddots+%26+%5Cddots+%26+-1+%5C%5C++++++++++++++++++++%26++++%26++++++++%26+-1+++++%26+2++++%5Cend%7Barray%7D%5Cright%5D+%5Cin%5Cmathbb%7BR%7D%5E%7Bn%5Ctimes+n%7D.+&bg=ffffff&fg=222222&s=0&c=20201002)
It arises when a second derivative is approximated by the central second difference 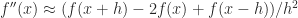
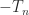
gallery('tridiag',n), which is returned as a aparse matrix.
This is Gil Strang’s favorite matrix. The photo, from his home page, shows a birthday cake representation of the matrix.

The second difference matrix is symmetric positive definite. The easiest way to see this is to define the full rank rectangular matrix
and note that 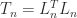

Cholesky Factorization
In an LU factorization 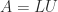
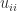
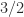
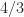
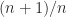
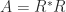

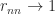

Determinant, Inverse, Condition Number
Since the determinant is the product of the pivots, 
The inverse of 
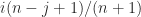
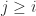
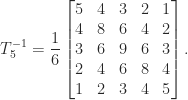
The 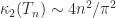
Eigenvalues and Eigenvectors
The eigenvalues of
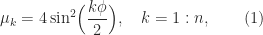
where 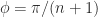
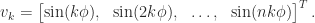
The matrix 
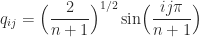
is therefore an eigenvector matrix for 
Variations
Various modifications of the second difference matrix arise and similar results can be derived. For example, consider the matrix obtained by changing the 

![\notag \widetilde{T}_n = \left[ \begin{array}{@{}*{4}{r@{\mskip10mu}}r} 2 & -1 & & & \\ -1 & 2 & -1 & & \\[-5pt] & -1 & 2 & \ddots & \\ & & \ddots & \ddots & -1 \\ & & & -1 & 1 \end{array}\right] \in\mathbb{R}^{n\times n}.](https://s0.wp.com/latex.php?latex=%5Cnotag++++%5Cwidetilde%7BT%7D_n+%3D+%5Cleft%5B++++%5Cbegin%7Barray%7D%7B%40%7B%7D%2A%7B4%7D%7Br%40%7B%5Cmskip10mu%7D%7Dr%7D+++++++++++++++++2++%26+-1+%26++++++++%26++++++++%26++++%5C%5C+++++++++++++++++-1+%26+2++%26+-1+++++%26++++++++%26++++%5C%5C%5B-5pt%5D++++++++++++++++++++%26+-1+%26+2++++++%26+%5Cddots+%26++++%5C%5C++++++++++++++++++++%26++++%26+%5Cddots+%26+%5Cddots+%26+-1+%5C%5C++++++++++++++++++++%26++++%26++++++++%26+-1+++++%26+1++++%5Cend%7Barray%7D%5Cright%5D+%5Cin%5Cmathbb%7BR%7D%5E%7Bn%5Ctimes+n%7D.+&bg=ffffff&fg=222222&s=0&c=20201002)
It can be shown that 


If we perturb the 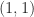
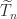
![\notag \widehat{T}_n = \left[ \begin{array}{@{}*{4}{r@{\mskip10mu}}r} 3 & -1 & & & \\ -1 & 2 & -1 & & \\[-5pt] & -1 & 2 & \ddots & \\ & & \ddots & \ddots & -1 \\ & & & -1 & 1 \end{array}\right] \in\mathbb{R}^{n\times n}.](https://s0.wp.com/latex.php?latex=%5Cnotag++++%5Cwidehat%7BT%7D_n+%3D+%5Cleft%5B++++%5Cbegin%7Barray%7D%7B%40%7B%7D%2A%7B4%7D%7Br%40%7B%5Cmskip10mu%7D%7Dr%7D+++++++++++++++++3++%26+-1+%26++++++++%26++++++++%26++++%5C%5C+++++++++++++++++-1+%26+2++%26+-1+++++%26++++++++%26++++%5C%5C%5B-5pt%5D++++++++++++++++++++%26+-1+%26+2++++++%26+%5Cddots+%26++++%5C%5C++++++++++++++++++++%26++++%26+%5Cddots+%26+%5Cddots+%26+-1+%5C%5C++++++++++++++++++++%26++++%26++++++++%26+-1+++++%26+1++++%5Cend%7Barray%7D%5Cright%5D+%5Cin%5Cmathbb%7BR%7D%5E%7Bn%5Ctimes+n%7D.+&bg=ffffff&fg=222222&s=0&c=20201002)
The inverse is 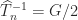

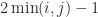

Notes
The factorization 
For a derivation of the eigenvalues and eigenvectors see Todd (1977, p. 155 ff.). For the eigenvalues of
References
This is a minimal set of references, which contain further useful references within.
- J. Fortiana and C. N. Cuadras, A Family of Matrices, the Discretized Brownian Bridge, and Distance-Based Regression, Linear Algebra Appl. 264, 173–188, 1997.
- Morris Newman and John Todd, The Evaluation of Matrix Inversion Programs, J. Soc. Indust. Appl. Math. 6(4), 466–476, 1958.
- Gilbert Strang, Essays in Linear Algebra, Wellesley-Cambridge Press, Wellesley, MA, USA, 2012. Chapter A.3: “My Favorite Matrix”.
- John Todd, Basic Numerical Mathematics, Vol.
Related Blog Posts
- What Is a Diagonally Dominant Matrix? (2021)
- What Is a Sparse Matrix? (2020)
- What Is a Symmetric Positive Definite Matrix? (2020)
- What Is a Tridiagonal Matrix? (2022)
- What Is an M-Matrix? (2021)
This article is part of the “What Is” series, available from https://nhigham.com/index-of-what-is-articles/ and in PDF form from the GitHub repository https://github.com/higham/what-is.
 upper Hessenberg matrix
upper Hessenberg matrix![\notag F_n = \left[\begin{array}{*{6}c} n & n-1 & n-2 & \dots & 2 & 1 \\ n-1 & n-1 & n-2 & \dots & 2 & 1 \\ 0 & n-2 & n-2 & \dots & 2 & 1 \\[-3pt] \vdots & 0 & \ddots & \ddots & \vdots & 1 \\[-3pt] \vdots & \vdots & \dots & 2 & 2 & 1 \\ 0 & 0 & \dots & 0 & 1 & 1 \\ \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cnotag+++F_n+%3D+++%5Cleft%5B%5Cbegin%7Barray%7D%7B%2A%7B6%7Dc%7D+++n++++++%26+n-1++++%26+n-2++++%26+%5Cdots++%26+2++++++%26+1+%5C%5C+++n-1++++%26+n-1++++%26+n-2++++%26+%5Cdots++%26+2++++++%26+1+%5C%5C+++0++++++%26+n-2++++%26+n-2++++%26+%5Cdots++%26+2++++++%26+1+%5C%5C%5B-3pt%5D+++%5Cvdots+%26+0++++++%26+%5Cddots+%26+%5Cddots+%26+%5Cvdots+%26+1+%5C%5C%5B-3pt%5D+++%5Cvdots+%26+%5Cvdots+%26+%5Cdots++%26+++2++++%26+2++++++%26+1+%5C%5C+++0++++++%26+0++++++%26+%5Cdots++%26+++0++++%26+1++++++%26+1+%5C%5C+++%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=222222&s=0&c=20201002)
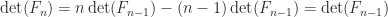 , and since
, and since  we have
we have  .
.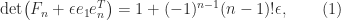
 element from 1 to
element from 1 to  changes the determinant by
changes the determinant by  .
.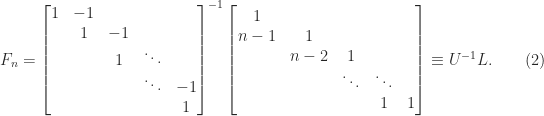
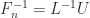 is lower Hessenberg with integer entries. This factorization provides another way to see that
is lower Hessenberg with integer entries. This factorization provides another way to see that 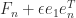 is singular for
is singular for 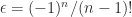 , which implies that
, which implies that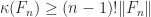
 . In fact, this lower bound is within a factor
. In fact, this lower bound is within a factor  of the condition number for the
of the condition number for the  -norms for
-norms for 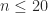 .
. the characteristic polynomial of
the characteristic polynomial of 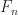 . By expanding about the first column one can show that
. By expanding about the first column one can show that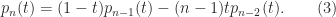
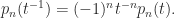
 is an eigenvalue when
is an eigenvalue when 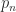 is palindromic when
is palindromic when  for any
for any  , and hence
, and hence  can perturb
can perturb 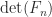 by
by 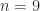 .
. (also called the logarithmic derivative) is defined by
(also called the logarithmic derivative) is defined by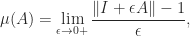
 .
. ,
,
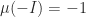 .
.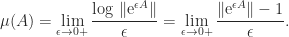
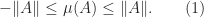
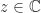 , we define
, we define 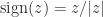 for
for 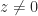 and
and  .
.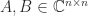 and
and 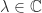 ,
,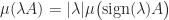 ,
, ,
, ,
,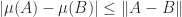 .
. features in an easily evaluated bound for the norm of
features in an easily evaluated bound for the norm of  and that, moreover,
and that, moreover, 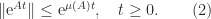

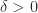 , by Lemma 1 there exists
, by Lemma 1 there exists 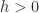 such that
such that![\notag \displaystyle\frac{ \| \mathrm{e}^{At}\| - 1}{t} - \mu(A) < \delta, \quad t\in[0,h],](https://s0.wp.com/latex.php?latex=%5Cnotag+++++%5Cdisplaystyle%5Cfrac%7B+%5C%7C+%5Cmathrm%7Be%7D%5E%7BAt%7D%5C%7C+-+1%7D%7Bt%7D+-+%5Cmu%28A%29+%3C+%5Cdelta%2C+++++%5Cquad+t%5Cin%5B0%2Ch%5D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
![\notag \| \mathrm{e}^{At}\| \le 1 + (\mu(A) + \delta)t \le \mathrm{e}^{(\mu(A) + \delta)t}, \quad t\in[0,h]](https://s0.wp.com/latex.php?latex=%5Cnotag+++++%5C%7C+%5Cmathrm%7Be%7D%5E%7BAt%7D%5C%7C+%5Cle+1+%2B+%28%5Cmu%28A%29+%2B+%5Cdelta%29t+++++++++%5Cle+%5Cmathrm%7Be%7D%5E%7B%28%5Cmu%28A%29+%2B+%5Cdelta%29t%7D%2C+++++%5Cquad+t%5Cin%5B0%2Ch%5D+&bg=ffffff&fg=222222&s=0&c=20201002)
 for all
for all  ). Then for any integer
). Then for any integer  ,
, 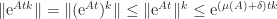 , and hence
, and hence  holds for all
holds for all  . Since
. Since 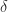 is arbitrary, it follows that
is arbitrary, it follows that 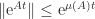 .
. for all
for all  then
then 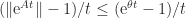 for all
for all  and taking
and taking  we conclude that
we conclude that  .
. , but
, but 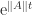 is increasing in
is increasing in 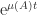 potentially decays, since
potentially decays, since  is possible.
is possible.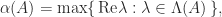
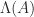 denotes the spectrum of
denotes the spectrum of  (the set of eigenvalues). Whereas the norm bounds the spectral radius (
(the set of eigenvalues). Whereas the norm bounds the spectral radius (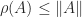 ), the logarithmic norm bounds the spectral abscissa, as shown by the next result.
), the logarithmic norm bounds the spectral abscissa, as shown by the next result.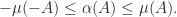

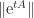 at
at 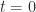 , so
, so 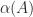 , since
, since 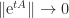 as
as 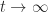 if and only if
if and only if 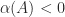 , which can be proved using the Jordan canonical form.
, which can be proved using the Jordan canonical form. then
then
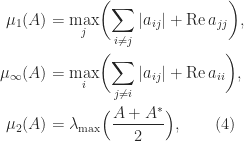
 denotes the largest eigenvalue of a Hermitian matrix.
denotes the largest eigenvalue of a Hermitian matrix.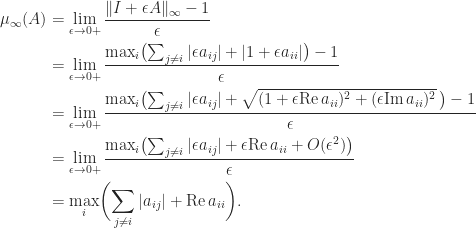
 follows, since
follows, since  implies
implies  . For the
. For the  , we have
, we have
 with
with  , then
, then  .
.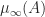 for
for  .
.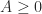 then
then  .
.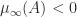 if and only if
if and only if 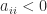 for all
for all  and
and 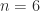 by
by![\notag A_6 = \left[\begin{array}{cccccc} -5 & 2 & 0 & 0 & 0 & 0\\ \frac{1}{2} & -7 & 3 & 0 & 0 & 0\\ 0 & \frac{1}{3} & -9 & 4 & 0 & 0\\ 0 & 0 & \frac{1}{4} & -11 & 5 & 0\\ 0 & 0 & 0 & \frac{1}{5} & -13 & 6\\ 0 & 0 & 0 & 0 & \frac{1}{6} & -15 \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cnotag+++++A_6+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccccc%7D++++++-5+%26+2+%26+0+%26+0+%26+0+%26+0%5C%5C++++++%5Cfrac%7B1%7D%7B2%7D+%26+-7+%26+3+%26+0+%26+0+%26+0%5C%5C++++++0+%26+%5Cfrac%7B1%7D%7B3%7D+%26+-9+%26+4+%26+0+%26+0%5C%5C++++++0+%26+0+%26+%5Cfrac%7B1%7D%7B4%7D+%26+-11+%26+5+%26+0%5C%5C++++++0+%26+0+%26+0+%26+%5Cfrac%7B1%7D%7B5%7D+%26+-13+%26+6%5C%5C++++++0+%26+0+%26+0+%26+0+%26+%5Cfrac%7B1%7D%7B6%7D+%26+-15++++++%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
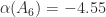 and
and 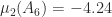 , and it is easy to see that
, and it is easy to see that  and
and  for all
for all 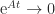 as
as 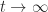 and
and  gives a faster decaying bound than
gives a faster decaying bound than 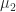 and
and 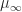 .
.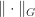 based on the vector norm
based on the vector norm 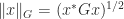 , where
, where 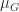 can be expressed as the largest eigenvalue of a Hermitian definite generalized eigenvalue problem.
can be expressed as the largest eigenvalue of a Hermitian definite generalized eigenvalue problem.
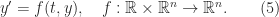
 be symmetric positive definite and consider the inner product
be symmetric positive definite and consider the inner product 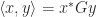 and the corresponding norm defined by
and the corresponding norm defined by 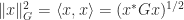 . It can be shown that for
. It can be shown that for 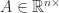 ,
,
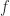 satisfies a one-sided Lipschitz condition if there is a function
satisfies a one-sided Lipschitz condition if there is a function  such that
such that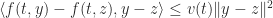
 in some region and all
in some region and all 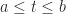 . For the linear differential equation with
. For the linear differential equation with 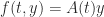 in (5), using (6) we obtain
in (5), using (6) we obtain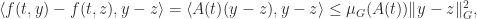
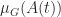 can be taken as a one-sided Lipschitz constant. This observation leads to results on contractivity of ODEs; see Lambert (1991) for details.
can be taken as a one-sided Lipschitz constant. This observation leads to results on contractivity of ODEs; see Lambert (1991) for details.
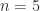 by
by![\notag T_5 = \left[ \begin{array}{@{}*{4}{r@{\mskip10mu}}r} 4 & -1 & & & \\ -1 & 4 & -1 & & \\ & -1 & 4 & -1 & \\ & & -1 & 4 & -1 \\ & & & -1 & 4 \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cnotag++++T_5+%3D+%5Cleft%5B++++%5Cbegin%7Barray%7D%7B%40%7B%7D%2A%7B4%7D%7Br%40%7B%5Cmskip10mu%7D%7Dr%7D+++++++++++++++++4++%26+-1+%26++++%26++++%26++++%5C%5C+++++++++++++++++-1+%26+4++%26+-1+%26++++%26++++%5C%5C++++++++++++++++++++%26+-1+%26+4++%26+-1+%26++++%5C%5C++++++++++++++++++++%26++++%26+-1+%26+4++%26+-1+%5C%5C++++++++++++++++++++%26++++%26++++%26+-1+%26+4++++%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
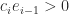 for all
for all  with positive diagonal elements such that
with positive diagonal elements such that 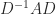 is symmetric, with
is symmetric, with  element
element  .
. . Equating
. Equating  and
and 
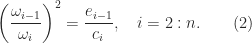
 and solve (2) to obtain real, positive
and solve (2) to obtain real, positive  ,
,  . The formula for the off-diagonal elements of the symmetrized matrix follows from (1) and (2).
. The formula for the off-diagonal elements of the symmetrized matrix follows from (1) and (2).

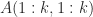 ,
,  , is singular. In general, partial pivoting must be used to ensure existence and numerical stability, giving a factorization
, is singular. In general, partial pivoting must be used to ensure existence and numerical stability, giving a factorization  where
where  has at most two nonzeros per column and
has at most two nonzeros per column and  has an extra superdiagonal. The growth factor
has an extra superdiagonal. The growth factor  is easily seen to be bounded by
is easily seen to be bounded by 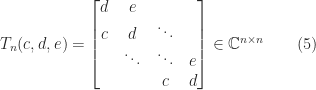
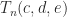 has an LU factorization with LU factors (3) and that
has an LU factorization with LU factors (3) and that 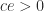 and
and  . Then
. Then  decreases monotonically and
decreases monotonically and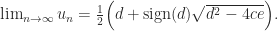
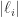 increases monotonically and
increases monotonically and  . Note that the conditions of Theorem 2 are satisfied if
. Note that the conditions of Theorem 2 are satisfied if 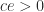 implies
implies 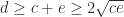 . Note also that if we symmetrize
. Note also that if we symmetrize  , which is irreducibly diagonally dominant and hence positive definite if
, which is irreducibly diagonally dominant and hence positive definite if  .
.![\notag T_5(-1,3,-1)^{-1} = \left[\begin{array}{rrrrr} 3 & -1 & 0 & 0 & 0\\ -1 & 3 & -1 & 0 & 0\\ 0 & -1 & 3 & -1 & 0\\ 0 & 0 & -1 & 3 & -1\\ 0 & 0 & 0 & -1 & 3 \end{array}\right]^{-1} = \frac{1}{144} \left[\begin{array}{ccccc} 55 & 21 & 8 & 3 & 1 \\ 21 & 63 & 24 & 9 & 3 \\ 8 & 24 & 64 & 24 & 8 \\ 3 & 9 & 24 & 63 & 21\\ 1 & 3 & 8 & 21 & 55 \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cnotag+++T_5%28-1%2C3%2C-1%29%5E%7B-1%7D+++%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Brrrrr%7D+3+%26+-1+%26+0+%26+0+%26+0%5C%5C+++++++++++++++++++++++++++++++-1+%26+3+%26+-1+%26+0+%26+0%5C%5C+++++++++++++++++++++++++++++++0+%26+-1+%26+3+%26+-1+%26+0%5C%5C+++++++++++++++++++++++++++++++0+%26+0+%26+-1+%26+3+%26+-1%5C%5C+++++++++++++++++++++++++++++++0+%26+0+%26+0+%26+-1+%26+3+%5Cend%7Barray%7D%5Cright%5D%5E%7B-1%7D++%3D++%5Cfrac%7B1%7D%7B144%7D+++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccc%7D+55+%26+21+%26+8++%26+3++%26+1+%5C%5C++++++++++++++++++++++++++++++++21+%26+63+%26+24+%26+9++%26+3+%5C%5C++++++++++++++++++++++++++++++++8+%26+24+%26+64+%26+24+%26+8+%5C%5C+3+%26+9+%26+24+%26+63+%26+21%5C%5C++++++++++++++++++++++++++++++++1+%26+3++%26+8++%26+21+%26+55+%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
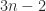 parameters, the same must be true of its inverse, meaning that there must be relations between the elements of the inverse. Indeed, in
parameters, the same must be true of its inverse, meaning that there must be relations between the elements of the inverse. Indeed, in  any
any  submatrix whose elements lie in the upper triangle is singular, and the
submatrix whose elements lie in the upper triangle is singular, and the 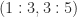 submatrix is also singular. The next result explains this special structure. We note that a tridiagonal matrix is irreducible if
submatrix is also singular. The next result explains this special structure. We note that a tridiagonal matrix is irreducible if  and
and  are nonzero for all
are nonzero for all  ,
,  ,
,  , all of whose elements are nonzero, such that
, all of whose elements are nonzero, such that![\notag (A^{-1})_{ij} = \begin{cases} u_iv_j, & i\le j,\\ x_iy_j, & i\ge j.\\[4pt] \end{cases}](https://s0.wp.com/latex.php?latex=%5Cnotag+++++++++++%28A%5E%7B-1%7D%29_%7Bij%7D+%3D+%5Cbegin%7Bcases%7D+++++++++++++++++++++++++++++++++u_iv_j%2C+%26+i%5Cle+j%2C%5C%5C+++++++++++++++++++++++++++++++++x_iy_j%2C+%26+i%5Cge+j.%5C%5C%5B4pt%5D+++++++++++++++++++++++++++%5Cend%7Bcases%7D+&bg=ffffff&fg=222222&s=0&c=20201002)
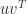 ) and the lower triangle of the inverse agrees with the lower triangle of another rank-
) and the lower triangle of the inverse agrees with the lower triangle of another rank- ). This explains the singular submatrices that we see in the example above.
). This explains the singular submatrices that we see in the example above.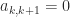 then it has the block form
then it has the block form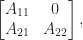
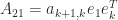 , and so
, and so
 block is rank
block is rank 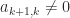 . This blocking can be applied recursively until Theorem 1 can be applied to all the diagonal blocks.
. This blocking can be applied recursively until Theorem 1 can be applied to all the diagonal blocks.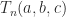 is known explicitly; see Dow (2003, Sec. 3.1).
is known explicitly; see Dow (2003, Sec. 3.1).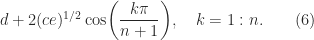
 in which the
in which the  , for any
, for any  . The matrix
. The matrix  is lower triangular with nonzero diagonal elements
is lower triangular with nonzero diagonal elements  and hence it is nonsingular. Therefore
and hence it is nonsingular. Therefore  for all
for all 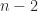 when
when 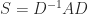 and so are real. The matrix
and so are real. The matrix  is tridiagonal and irreducible so it is nonderogatory by Theorem 4, which means that its eigenvalues are simple because it is symmetric.
is tridiagonal and irreducible so it is nonderogatory by Theorem 4, which means that its eigenvalues are simple because it is symmetric.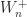 , defined by
, defined by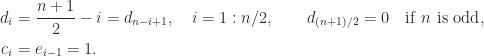
![\notag W_5^+ = \left[\begin{array}{ccccc} 2 & 1 & 0 & 0 & 0\\ 1 & 1 & 1 & 0 & 0\\ 0 & 1 & 0 & 1 & 0\\ 0 & 0 & 1 & 1 & 1\\ 0 & 0 & 0 & 1 & 2 \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cnotag+++W_5%5E%2B+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccc%7D+2+%26+1+%26+0+%26+0+%26+0%5C%5C+1+%26+1+%26+1+%26+0+%26+0%5C%5C+0+%26+1+%26+0+%26+1+%26+0%5C%5C+0+%26+0+%26+1+%26+1+%26+1%5C%5C+0+%26+0+%26+0+%26+1+%26+2+%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
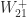 , as computed by MATLAB.
, as computed by MATLAB. for
for 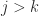 once
once 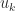 is close enough to the limit.
is close enough to the limit.