For the last 30 years, most floating point calculations in scientific computing have been carried out in 64-bit IEEE double precision arithmetic, which provides the elementary operations of addition, subtraction, multiplication, and division at a relative accuracy of about 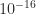 . We are now seeing growing use of mixed precision, in which different floating point precisions are combined in order to deliver a result of the required accuracy at minimal cost.
. We are now seeing growing use of mixed precision, in which different floating point precisions are combined in order to deliver a result of the required accuracy at minimal cost.
Single precision arithmetic (32 bits) is an attractive alternative to double precision because it halves the costs of storing and transferring data, and on Intel chips the SSE extensions allow single precision arithmetic to run twice as fast as double.
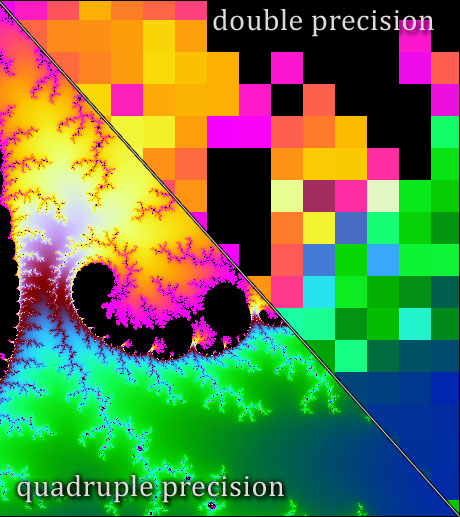
Quadruple precision arithmetic, which was included in the 2008 revision of the IEEE standard, is supported by some compilers, and it can be implemented in terms of double precision arithmetic via double-double arithmetic. Arbitrary precision floating point arithmetic is available through, for example, the GNU MPFR library, the mpmath library for Python, the core data type BigFloat in the new language Julia, VPA arithmetic in the MATLAB Symbolic Math Toolbox, or the Advanpix Multiprecision Computing Toolbox for MATLAB.
Half precision arithmetic, in which a number occupies 16 bits, is supported by the IEEE standard for storage but not for computation. It has been argued that for deep learning half precision, with its relative accuracy of about  , is good enough for training and running neural networks. Here are some of the ways in which extra precision is currently being used.
, is good enough for training and running neural networks. Here are some of the ways in which extra precision is currently being used.
- Iterative refinement, in the traditional form that first became popular in the 1960s, improves the quality of an approximate solution to a linear system via updates obtained from residuals computed in extra precision.
- When an algorithm suffers instability it may be possible to overcome it by using extra precision in just a few, key places. This has been done recently in eigensolvers and for matrix orthonormalization.
- Any iterative algorithm that accepts an arbitrary starting point can be run once at a given precision and the solution used to “warm start” a second run of the same algorithm at higher precision. This idea has been used recently in linear programming.
- Numerical integration of differential equations over long time periods may need higher precision in order to allow the phenomena of interest to be observed. A recent example is in the study of Kerr (rotating) black holes, where the underlying hyperbolic partial differential equation is solved using quadruple precision arithmetic running on GPUs.
- When one is developing error bounds or testing algorithms, one needs in principle the exact solution. In practice, a solution computed at high precision and rounded to the working precision is usually adequate, and this is an approach I frequently use in my work in numerical linear algebra.
As the relative costs and ease of computing at different precisions evolve, due to changing architectures and software, as well as the disruptive influence of accelerators such as GPUs, we will see an increasing development and use of mixed precision algorithms. In some ways this is analogous to the increasing interoperability of programming languages (illustrated by C++, Julia, and Python, for example): one uses the main tool (precision) one would like to work with and brings in other tools (precisions) as necessary in order to complete the task.
Update: linear programming link updated December 18, 2018.


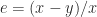


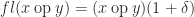

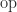




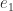
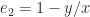






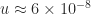





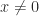 and
and 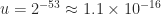 , which is called the unit roundoff.
, which is called the unit roundoff.  , where the infinity norm is
, where the infinity norm is  ? It does not seem to be well known that
? It does not seem to be well known that  can be much less than
can be much less than 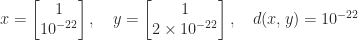 .
.  is possible.
is possible.  -vectors of normalized floating point numbers.
-vectors of normalized floating point numbers.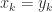 for all
for all  such that
such that  .
.
