
When I am testing an algorithm running in double precision arithmetic I often want to compare the computed solution with a reference solution: a solution that is fully accurate to double precision. To obtain one I solve the same problem in quadruple precision and round the result back to double precision. If the conditioning of the problem leads me to doubt that that this reference solution will be correct to double precision, I compute it at a precision even higher than quadruple. Whether it is feasible to compute a reference solution in this way depends on the size of the problem and the speed of quadruple precision arithmetic. This is just one scenario where quadruple precision arithmetic is needed; others are discussed in my earlier post The Rise of Mixed Precision Arithmetic.
Roughly speaking, a quadruple precision number 
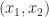
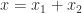
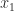
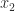
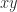
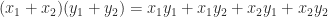
Various aspects need to be taken into consideration when we compare double precision and quadruple precision arithmetics. First, the relative speed of the arithmetics may depend on the type of operations being performed (scalar versus vectorizable operations), memory traffic considerations, and to what extent the implementations exploit multicore processors. Second, are we to compare the same code running in different precisions or computational kernels coded specially for each precision? I will take the second approach, as it is more relevant to my usage of quadruple precision. However, this does mean that I am comparing algorithms and their implementations as well as the underlying arithmetic.
I have done some very simple comparisons in MATLAB using the VPA arithmetic of the Symbolic Math Toolbox and the MP arithmetic of the third party Multiprecision Computing Toolbox from Advanpix.
The Multiprecision Computing Toolbox supports IEEE-compliant quadruple precision arithmetic, which is invoked by using the function mp.Digits to set the precision to 34 decimal digits (in fact, this is the default). For the VPA arithmetic in the Symbolic Math Toolbox 34 decimal digit precision is specified with the command digits(34) (the default is 32 digits). According to the documentation, VPA arithmetic uses a few guard digits, that is, it computes with a few extra digits of precision. The number of guard digits cannot be set by the user. In the Multiprecision Computing Toolbox the number of guard digits can be set with the function mp.GuardDigits, and the default is to use no guard digits.
These experiments were performed on an Intel Broadwell-E Core i7-6800K CPU @ 3.40GHz, which has 6 cores. The software details are:
MATLAB Version: 9.2.0.538062 (R2017a)
Operating System: Microsoft Windows 10 Home Version 10.0
(Build 15063)
Advanpix Multiprecision Computing Toolbox Version 4.4.1.12580
Symbolic Math Toolbox Version 7.2 (R2017a)
Further details on the Multiprecision Computing Toolbox can be seen by typing mp.Info, which lists details of open source libraries that are used.
In these experiments I do not check that the computed results are correct. Such checks are done in more extensive tests available in the test scripts at https://www.advanpix.com/2015/02/12/version-3-8-0-release-notes/. I note that the timings vary from run to run, but it is the order of magnitudes of the ratios that are of interest and these are correctly reflected by the reported results.
Test 1: LU Factorization
This code compares the speed of the arithmetics for LU factorization of a 250-by-250 matrix.
%QUAD_PREC_TEST1 LU factorization.
rng(1), n = 250;
A = randn(n); A_mp = mp(A,34); A_vpa = vpa(A,34);
t = clock; [L,U] = lu(A); t_dp = etime(clock, t)
t = clock; [L,U] = lu(A_mp); t_mp = etime(clock, t)
t = clock; [L,U] = lu(A_vpa); t_vpa = etime(clock, t)
fprintf('mp/double: %8.2e, vpa/double: %8.2e, vpa/mp: %8.2e\n',....
t_mp/t_dp, t_vpa/t_dp, t_vpa/t_mp)
The output is
t_dp = 1.0000e-03 t_mp = 9.8000e-02 t_vpa = 2.4982e+01 mp/double: 9.80e+01, vpa/double: 2.50e+04, vpa/mp: 2.55e+02
Here, the MP quadruple precision is 98 times slower than double precision, but VPA is 25,000 times slower than double precision.
Test 2: Complete Eigensystem of Nonsymmetric Matrix
%QUAD_PREC_TEST2 Complete eigensystem of nonsymmetric matrix.
rng(1), n = 125;
A = randn(n); A_mp = mp(A,34); A_vpa = vpa(A,34);
t = clock; [V,D] = eig(A); t_dp = etime(clock, t)
t = clock; [V,D] = eig(A_mp); t_mp = etime(clock, t)
t = clock; [V,D] = eig(A_vpa); t_vpa = etime(clock, t)
fprintf('mp/double: %8.2e, vpa/double: %8.2e, vpa/mp: %8.2e\n',....
t_mp/t_dp, t_vpa/t_dp, t_vpa/t_mp)
The output is
t_dp = 1.8000e-02 t_mp = 1.3430e+00 t_vpa = 1.0839e+02 mp/double: 7.46e+01, vpa/double: 6.02e+03, vpa/mp: 8.07e+01
Here, MP is 75 times slower than double, and VPA is closer to the speed of MP.
Test 3: Complete Eigensystem of Symmetric Matrix
%QUAD_PREC_TEST3 Complete eigensystem of symmetric matrix.
rng(1), n = 200;
A = randn(n); A = A + A'; A_mp = mp(A,34); A_vpa = vpa(A,34);
t = clock; [V,D] = eig(A); t_dp = etime(clock, t)
t = clock; [V,D] = eig(A_mp); t_mp = etime(clock, t)
t = clock; [V,D] = eig(A_vpa); t_vpa = etime(clock, t)
fprintf('mp/double: %8.2e, vpa/double: %8.2e, vpa/mp: %8.2e\n',....
t_mp/t_dp, t_vpa/t_dp, t_vpa/t_mp)
The output is
t_dp = 1.1000e-02 t_mp = 3.5800e-01 t_vpa = 1.2246e+02 mp/double: 3.25e+01, vpa/double: 1.11e+04, vpa/mp: 3.42e+02
Note that there are at least three different algorithms that could be used here (the QR algorithm, divide and conquer, and multiple relatively robust representations), so the three eig invocations may be using different algorithms.
Test 4: Componentwise Exponentiation
%QUAD_PREC_TEST4 Componentwise exponentiation.
rng(1), n = 1000;
A = randn(n); A_mp = mp(A,34); A_vpa = vpa(A,34);
t = clock; X = exp(A); t_dp = etime(clock, t)
t = clock; X - exp(A_mp); t_mp = etime(clock, t)
t = clock; X - exp(A_vpa); t_vpa = etime(clock, t)
fprintf('mp/double: %8.2e, vpa/double: %8.2e, vpa/mp: %8.2e\n',....
t_mp/t_dp, t_vpa/t_dp, t_vpa/t_mp)
The output is
t_dp = 7.0000e-03 t_mp = 8.5000e-02 t_vpa = 3.4852e+01 mp/double: 1.21e+01, vpa/double: 4.98e+03, vpa/mp: 4.10e+02
Both MP and VPA come closer to double precision on this problem of computing the scalar exponential at each matrix element.
Summary
Not too much emphasis should be put on the precise timings, which vary with the value of the dimension n. The main conclusions are that 34-digit MP arithmetic is 1 to 2 orders of magnitude slower than double precision and 34-digit VPA arithmetic is 3 to 4 orders of magnitude slower than double precision.
It is worth noting that the documentation for the Multiprecision Computing Toolbox states that the toolbox is optimized for quadruple precision.
It is also interesting to note that the authors of the GNU MPFR library (for multiple-precision floating-point computations with correct rounding) are working on optimizing the library for double precision and quadruple precision computations, as explained in a talk given by Paul Zimmermann at the 24th IEEE Symposium on Computer Arithmetic in July 2017; see the slides and the corresponding paper.
[Updated September 6, 2017 to clarify mp.Info and April 6, 2018 to change “Multiplication” to “Multiprecision” in penultimate paragraph.]
 as an approximation to a scalar
as an approximation to a scalar 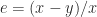 . I recently came across a program in which
. I recently came across a program in which  had been computed as
had been computed as  . It had never occurred to me to compute it this way. The second version is slightly easier to type, requiring no parentheses, and it has the same cost of evaluation: one division and one subtraction. Is there any reason not to use this parenthesis-free expression?
. It had never occurred to me to compute it this way. The second version is slightly easier to type, requiring no parentheses, and it has the same cost of evaluation: one division and one subtraction. Is there any reason not to use this parenthesis-free expression? 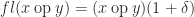 with
with  , where
, where 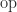 is any one of the four elementary arithmetic operations and
is any one of the four elementary arithmetic operations and  is the unit roundoff. For the expression
is the unit roundoff. For the expression  we obtain, with a hat denoting a computed quantity,
we obtain, with a hat denoting a computed quantity, 

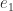 is computed very accurately.
is computed very accurately. 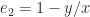 , we have
, we have 

 is of order
is of order  , and hence is very large when
, and hence is very large when  .
.  , we evaluated the relative error of
, we evaluated the relative error of 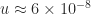 . (The MATLAB script that generates the figure is available as
. (The MATLAB script that generates the figure is available as 
 is very inaccurate when
is very inaccurate when  retains its accuracy as
retains its accuracy as  even the order of magnitude is incorrect for
even the order of magnitude is incorrect for  should be preferred.
should be preferred. 
