 James Wilkinson’s 1963 book Rounding Errors in Algebraic Processes has been hugely influential. It came at a time when the effects of rounding errors on numerical computations in finite precision arithmetic had just starting to be understood, largely due to Wilkinson’s pioneering work over the previous two decades. The book gives a uniform treatment of error analysis of computations with polynomials and matrices and it is notable for making use of backward errors and condition numbers and thereby distinguishing problem sensitivity from the stability properties of any particular algorithm.
James Wilkinson’s 1963 book Rounding Errors in Algebraic Processes has been hugely influential. It came at a time when the effects of rounding errors on numerical computations in finite precision arithmetic had just starting to be understood, largely due to Wilkinson’s pioneering work over the previous two decades. The book gives a uniform treatment of error analysis of computations with polynomials and matrices and it is notable for making use of backward errors and condition numbers and thereby distinguishing problem sensitivity from the stability properties of any particular algorithm.
The book was originally published by Her Majesty’s Stationery Office in the UK and Prentice-Hall in the USA. It was reprinted by Dover in 1994 but has been out of print for some time. SIAM has now reprinted the book in its Classics in Applied Mathematics series. It is available from the SIAM Bookstore and, for those with access to it, the SIAM Institutional Book Collection.
I was asked to write a foreword to the book, which I include below. The photo shows Wilkinson lecturing at Argonne National Laboratory. For more about Wilkinson see the James Hardy Wilkinson web page.

Foreword
Rounding Errors in Algebraic Processes was the first book to give detailed analyses of the effects of rounding errors on a variety of key computations involving polynomials and matrices.
The book builds on James Wilkinson’s 20 years of experience in using the ACE and DEUCE computers at the National Physical Laboratory in Teddington, just outside London. The original design for the ACE was prepared by Alan Turing in 1945, and after Turing left for Cambridge Wilkinson led the group that continued to design and build the machine and its software. The ACE made its first computations in 1950. A Cambridge educated mathematician, Wilkinson was perfectly placed to develop and analyze numerical algorithms on the ACE and the DEUCE (the commercial version of the ACE). The intimate access he had to the computers (which included the ability to observe intermediate computed quantities on lights on the console) helped Wilkinson to develop a deep understanding of the numerical methods he was using and their behavior in finite precision arithmetic.
The principal contribution of the book is the analysis of the effects of rounding errors on algorithms, using backward error analysis (then in its infancy) or forward error analysis as appropriate. The book laid the foundations for the error analysis of algebraic processes on digital computers.
Three types of computer arithmetic are analyzed: floating-point arithmetic, fixed-point arithmetic (in which numbers are represented as a number on a fixed interval such as
with a fixed scale factor), and block floating-point arithmetic, which is a hybrid of floating-point arithmetic and fixed-point arithmetic. Although floating-point arithmetic dominates today’s computational landscape, fixed-point arithmetic is widely used in digital signal processing and block floating-point arithmetic is enjoying renewed interest in machine learning.
A notable feature of the book is its careful consideration of problem sensitivity, as measured by condition numbers, and this approach inspired future generations of numerical analysis textbooks.
Wilkinson recognized that the worst-case error bounds he derived are pessimistic and he noted that more realistic bounds are obtained by taking the square roots of the dimension-dependent terms (see pages 26, 52, 102, 151). In recent years, rigorous results have been derived that support Wilkinson’s intuition: they show that bounds with the square roots of the constants hold with high probability under certain probabilistic assumptions on the rounding errors.
It is entirely fitting that Rounding Errors in Algebraic Processes is reprinted in the SIAM Classics series. The book is a true classic, it continues to be well-cited, and it will remain a valuable reference for years to come.


 has been greatly expanded, reflecting both the many new and useful packages and my improved knowledge of typesetting.
has been greatly expanded, reflecting both the many new and useful packages and my improved knowledge of typesetting.

 for
for 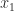 ,
, 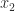 ,
,  , etc”
, etc” floating-point operations a second”, and teraflop, “a thousand billion floating-point operations a second”. I just wish the latter definition contained “
floating-point operations a second”, and teraflop, “a thousand billion floating-point operations a second”. I just wish the latter definition contained “ “, because there is scope for misunderstanding because of the alternative meaning of a billion as a million million in the UK.
“, because there is scope for misunderstanding because of the alternative meaning of a billion as a million million in the UK.

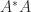 . Personally, I prefer the more elegant, if less intuitively obvious, proof in Golub and Van Loan’s
. Personally, I prefer the more elegant, if less intuitively obvious, proof in Golub and Van Loan’s  discs form a connected region that is isolated from the other discs then that region contains precisely
discs form a connected region that is isolated from the other discs then that region contains precisely 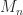 for an
for an  matrix, is not included.
matrix, is not included.
 The differences between the RGB version and the other two versions may be shocking! Fortunately, when the CMYK version is viewed on a printed page in isolation from the RGB version (necessarily displayed on a monitor) it does not look so bad. [Of course, if you are reading a printed version of this post then the first two images will look essentially the same.]
The differences between the RGB version and the other two versions may be shocking! Fortunately, when the CMYK version is viewed on a printed page in isolation from the RGB version (necessarily displayed on a monitor) it does not look so bad. [Of course, if you are reading a printed version of this post then the first two images will look essentially the same.]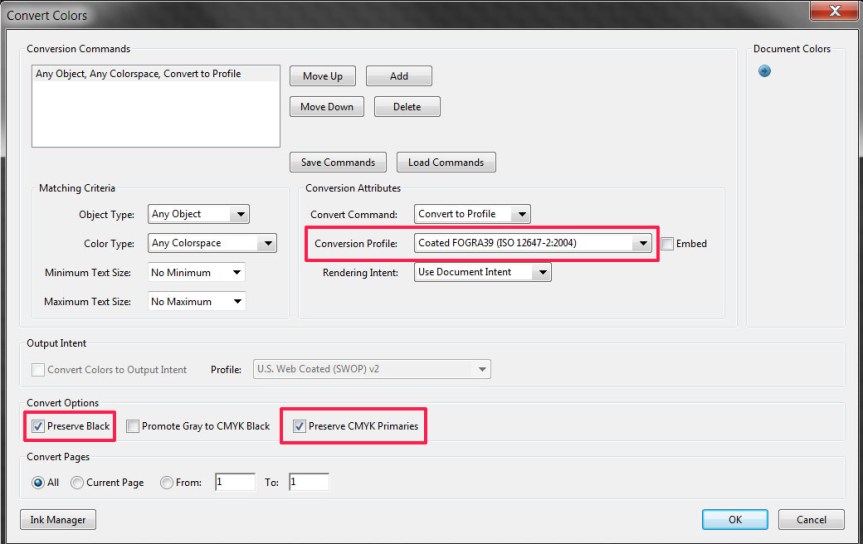 There are a couple of things to note. First, Adobe Acrobat does not remember the settings in the dialog box, so they need to be re-entered every time. Second, since “Embed profile” is not selected with the settings shown, there is no way to tell which profile has been used once the conversion has been done.
There are a couple of things to note. First, Adobe Acrobat does not remember the settings in the dialog box, so they need to be re-entered every time. Second, since “Embed profile” is not selected with the settings shown, there is no way to tell which profile has been used once the conversion has been done. On the left is the result of converting the original RGB image to “U.S. Web Coated (SWOP) v2” and on the right is the result of converting to “Photoshop 5 default CMYK” (and converting back to RGB in both cases, the latter conversion producing no visual difference in Photoshop). There is a significant difference between the two conversions in every color except white! In principle, both conversions will produce the same result when printed with the target ink and paper, but if you choose the profile without knowing the target you have little idea what the printed result will be.
On the left is the result of converting the original RGB image to “U.S. Web Coated (SWOP) v2” and on the right is the result of converting to “Photoshop 5 default CMYK” (and converting back to RGB in both cases, the latter conversion producing no visual difference in Photoshop). There is a significant difference between the two conversions in every color except white! In principle, both conversions will produce the same result when printed with the target ink and paper, but if you choose the profile without knowing the target you have little idea what the printed result will be.



 engine. If you are still generating dvi files you should consider making the switch!
engine. If you are still generating dvi files you should consider making the switch!
