Matthew G. Kirschenbaum’s recent book Track Changes: A Literary History of Word Processing contains a lot of interesting detail about the early days of word processing, covering the period 1964 to 1984. Most of the book concerns non-scientific writing, though 
Inspired by the book, I thought it might be useful to collect some information on early mathematical wordprocessing. Little information of this kind seems to be available online.
It is first worth noting that before the advent of word processors papers were typed on a typewriter and mathematical symbols were typically filled in by hand, as in this example from A Study of the Matrix Exponential (1975) by Charlie Van Loan: 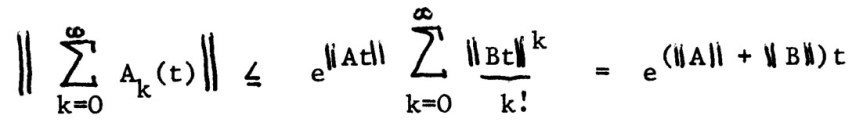
Some institutions had the luxury of IBM Selectric typewriters, which had a “golf ball” that could be changed in order to type special characters. (See this page for informative videos about the Selectric.) Here is an example of output from the Selectric, taken from my MSc thesis:  This illustrates some characteristic weaknesses of typewriter output: superscripts, subscripts, and operators are of the same size as the main symbols and spacing between characters is fixed (as in the vertical bars making up the norm signs here).
This illustrates some characteristic weaknesses of typewriter output: superscripts, subscripts, and operators are of the same size as the main symbols and spacing between characters is fixed (as in the vertical bars making up the norm signs here).
In 1980s at the Department of Mathematics at the University of Manchester the word processor Vuwriter was used. It was produced by a spin-off company Vuman Computer Systems, which took its name from “Victoria University of Manchester”, the university’s full name. Vuwriter ran on the Apricot PC, produced by the British company Apricot computers. At least one of my first papers was typed on Vuwriter by the office staff and I still have the original 1984 technical report Computing the Polar Decomposition—with Applications, which I have scanned and is available here. A typical equation from the report is this one:

The article
Peter Dolton, Comparing Scientific Word Processor Packages:
and Vuwriter, The Economic Journal 100, 311-315, 1990
reviews a version of Vuwriter that ran under MS DOS on IBM PC compatibles. Another review is
D. L. Mealand, Word Processing in Greek using Vuwriter Arts: A Test case for Foreign Language Word Processing, Literary and Linguistic Computing 2, 30-33, 1987
which describes a version of the program for use with foreign languages.
The Department of Mathematics at UMIST (which merged with the University of Manchester in 2004) used an MSDOS word processor called ChiWriter.
In the same period I also prepared manuscripts on my own microcomputers: first on a Commodore 64 and then on a Commodore 128 (essentially a Commodore 64 with a screen 80 characters wide rather than 40 characters wide), using a wordprocessor called Vizawrite. For output I used an Epson FX-80 dot matrix printer, and later an Epson LQ 850 (which produced high resolution output thanks to its 24 pin print head, as opposed to the 9 pin print head of the FX-80). Vizawrite was able to take advantage of the Epson printers’ ability to produce subscripts and superscripts, Greek characters, and mathematical symbols. An earlier post links to a scan of my 1985 article Matrix Computations in Basic on a Microcomputer produced in Vizawrite.
In the 1980s some colleagues wrote papers on a Mac. An example (preserved at the Cornell eCommons digital repository) is A Storage Efficient WY Representation for Products of Householder Transformations (1987) by Charlie Van Loan. I think that report was prepared in Mac Write. Here is a sample equation:

Also in the 1980s I built a database of papers that I had read, and wrote a program that could extract the items that I wanted to cite, format them, and print a sorted list. This was a big time-saver for producing reference lists, especially for my PhD thesis. The database was originally held in Superbase for the Commodore C128, with the program written in Superbase’s own language, and was later transferred to PC-File running on an IBM PC-clone with the program converted to GW-Basic. I was essentially building my own much simpler version of BibTeX, which did not exist when I started the database.
I am aware of two good sources of information about technical word processors for the IBM PC. The first is the article
P. K. Wong, Choices for Mathematical Wordprocessing Software, SIAM News 17(6), pp. 8-9, 1984
This article notes that
“There are over 120 wordprocessing programs for the IBM PC alone and the machine is not yet three years old! Of this large number, however, less than half a dozen can claim scientific wordprocessing capabilities, and these have only been available within the past six to nine months.”
The other source is two articles published in the Notices of the American Mathematical Society in the 1980s.
PC Technical Group of IBM PC Users Group of the Boston Computer Society, Technical Wordprocessors for the IBM PC and Compatibles, Notices Amer. Math. Soc. 33, 8-37, 1986
PC Technical Group of IBM PC Users Group of the Boston Computer Society, Technical Wordprocessors for the IBM PC and Compatibles, Part IIB: Reviews, Notices Amer. Math. Soc. 34, 462-491, 1987
These two articles do not appear to be available online. The first of them includes a set of benchmarks, consisting of extracts from technical journals and books, which were used to test the abilities of the packages. The authors make the interesting comment that
“Microsoft chose not to answer our review request for Word, and based on discussion with Word owners, Word is not set up for equations.”
Finally, Roger Horn told me that his book Topics in Matrix Analysis (CUP, 1991), co-authored with Charlie Johnson, was produced from the camera-ready output of the
If you have any information to add, please put it in the “Leave a Reply” box below.
Acknowledgement: thanks to Christopher Baker and David Silvester for comments on a draft of this post.
 with
with  element
element 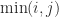 is with
is with 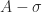 , with a scalar
, with a scalar 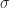 , he or she usually means
, he or she usually means  and not
and not  with
with 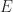 the matrix of ones.
the matrix of ones.  ? Many free online resources are available, including “getting started” guides, FAQs, references, Wikis, and so on. But in my view you can’t beat using a (physical) book. A book can be read anywhere. You can write notes in it, stick page markers on it, and quickly browse it or look something up in the index.
? Many free online resources are available, including “getting started” guides, FAQs, references, Wikis, and so on. But in my view you can’t beat using a (physical) book. A book can be read anywhere. You can write notes in it, stick page markers on it, and quickly browse it or look something up in the index.
