A matrix 
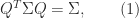
where 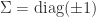

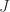

It is easy to show that 

Since 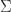


What are some examples of pseudo-orthogonal matrices? For 
![\Sigma = \left[\begin{smallmatrix}1 & 0 \\ 0 & -1 \end{smallmatrix}\right]](https://s0.wp.com/latex.php?latex=%5CSigma+%3D+%5Cleft%5B%5Cbegin%7Bsmallmatrix%7D1+%26+0+%5C%5C+0+%26+-1+%5Cend%7Bsmallmatrix%7D%5Cright%5D&bg=ffffff&fg=222222&s=0&c=20201002)

which includes the matrices

The Lorentz group, representing symmetries of the spacetime of special relativity, corresponds to 

Equation (2) shows that 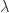

By permuting rows and columns in (1) we can arrange that
We assume that 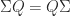

Applications
Pseudo-orthogonal matrices arise in hyperbolic problems, that is, problems where there is an underlying indefinite scalar product or weight matrix. An example is the problem of downdating the Cholesky factorization, where in the simplest case we have the Cholesky factorization 


![\notag A = \begin{array}[b]{cc} \left[\begin{array}{@{}c@{}} A_1\\ A_2 \end{array}\right] & \mskip-22mu\ \begin{array}{l} \scriptstyle p \\ \scriptstyle q \end{array} \end{array}, \quad p\ge n,](https://s0.wp.com/latex.php?latex=%5Cnotag+++A+%3D+%5Cbegin%7Barray%7D%5Bb%5D%7Bcc%7D++++++++%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%7Dc%40%7B%7D%7D++++++++++++++++++A_1%5C%5C++++++++++++++++++A_2++++++++++++++%5Cend%7Barray%7D%5Cright%5D++++++++%26+%5Cmskip-22mu%5C++++++++++%5Cbegin%7Barray%7D%7Bl%7D++++++++++++++%5Cscriptstyle+p+%5C%5C++++++++++++++%5Cscriptstyle+q++++++++++%5Cend%7Barray%7D++++%5Cend%7Barray%7D%2C++++%5Cquad+p%5Cge+n%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
and the Cholesky factorization 









with 
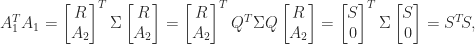
so
The factorization (6) is called a hyperbolic QR factorization and it can be computed by using hyperbolic rotations to zero out the elements of 



In general, a hyperbolic QR factorization of 


![QA = \left[\begin{smallmatrix} R \\ 0 \end{smallmatrix}\right]](https://s0.wp.com/latex.php?latex=QA+%3D+%5Cleft%5B%5Cbegin%7Bsmallmatrix%7D+R+%5C%5C+0+%5Cend%7Bsmallmatrix%7D%5Cright%5D&bg=ffffff&fg=222222&s=0&c=20201002)



Another hyperbolic problem is the indefinite least squares problem

where 




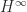
The normal equations for (7) are 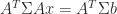
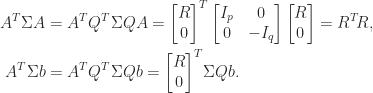
Solving the problem now reduces to solving the triangular system 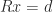
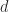


The Exchange Operator
A simple technique exists for converting pseudo-orthogonal matrices into orthogonal matrices and vice versa. Let 
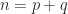
![\notag A = \mskip5mu \begin{array}[b]{@{\mskip-20mu}c@{\mskip0mu}c@{\mskip-1mu}c@{}} & \mskip10mu\scriptstyle p & \scriptstyle q \\ \mskip15mu \begin{array}{r} \scriptstyle p \\ \scriptstyle q \end{array}~ & \multicolumn{2}{c}{\mskip-15mu \left[\begin{array}{c@{~}c@{~}} A_{11} & A_{12}\\ A_{21} & A_{22} \end{array}\right] } \end{array}, \qquad (8)](https://s0.wp.com/latex.php?latex=%5Cnotag+++A++%3D+%5Cmskip5mu++++%5Cbegin%7Barray%7D%5Bb%5D%7B%40%7B%5Cmskip-20mu%7Dc%40%7B%5Cmskip0mu%7Dc%40%7B%5Cmskip-1mu%7Dc%40%7B%7D%7D++++%26+%5Cmskip10mu%5Cscriptstyle+p+%26+%5Cscriptstyle+q+%5C%5C+++++++%5Cmskip15mu++++++++++%5Cbegin%7Barray%7D%7Br%7D++++++++++++++%5Cscriptstyle+p+%5C%5C++++++++++++++%5Cscriptstyle+q++++++++++%5Cend%7Barray%7D%7E++++%26+++++++%5Cmulticolumn%7B2%7D%7Bc%7D%7B%5Cmskip-15mu++++++++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%40%7B%7E%7Dc%40%7B%7E%7D%7D++++++++++++++++++A_%7B11%7D+%26+A_%7B12%7D%5C%5C++++++++++++++++++A_%7B21%7D+%26+A_%7B22%7D++++++++++++++++%5Cend%7Barray%7D%5Cright%5D+++++++%7D++++%5Cend%7Barray%7D%2C+%5Cqquad+%288%29+&bg=ffffff&fg=222222&s=0&c=20201002)
and assume 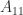
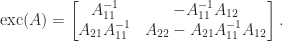
It is easy to see that the exchange operator is involutory, that is,

and moreover (recalling that

The next result gives a formula for the inverse of 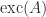
Lemma 1. Let
is nonsingular and
exists then
.
Proof. Consider the equation
By solving the first equation for
and then eliminating
By the same argument applied to
, we have
Hence for any
there is a unique
and
, which implies by (10) that
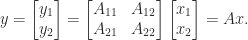
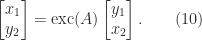


Now we will show that the exchange operator maps pseudo-orthogonal matrices to orthogonal matrices and vice versa.
Theorem 2. Let
Proof. If
, which implies that
, it follows that
also has a nonsingular
block and so
. But (9) shows that
, and we conclude that
Assume now that
exists and Lemma 1 shows that
. Hence, using (9),
which shows that
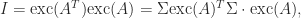
This MATLAB example uses the exchange operator to convert an orthogonal matrix obtained from a Hadamard matrix into a pseudo-orthogonal matrix.
>> p = 2; n = 4;
>> A = hadamard(n)/sqrt(n), Sigma = blkdiag(eye(p),-eye(n-p))
A =
5.0000e-01 5.0000e-01 5.0000e-01 5.0000e-01
5.0000e-01 -5.0000e-01 5.0000e-01 -5.0000e-01
5.0000e-01 5.0000e-01 -5.0000e-01 -5.0000e-01
5.0000e-01 -5.0000e-01 -5.0000e-01 5.0000e-01
Sigma =
1 0 0 0
0 1 0 0
0 0 -1 0
0 0 0 -1
>> Q = exc(A,p), Q'*Sigma*Q
Q =
1 1 -1 0
1 -1 0 -1
1 0 -1 -1
0 1 -1 1
ans =
1 0 0 0
0 1 0 0
0 0 -1 0
0 0 0 -1
The code uses the function
function X = exc(A,p)
%EXC Exchange operator.
% EXC(A,p) is the result of applying the exchange operator to
% the square matrix A, which is regarded as a block 2-by-2
% matrix with leading block of dimension p.
% p defaults to floor(n)/2.
[m,n] = size(A);
if m ~= n, error('Matrix must be square.'), end
if nargin < 2, p = floor(n/2); end
A11 = A(1:p,1:p);
A12 = A(1:p,p+1:n);
A21 = A(p+1:n,1:p);
A22 = A(p+1:n,p+1:n);
X21 = A11\A12;
X = [inv(A11) -X21;
A21/A11 A22-A21*X21];
Hyperbolic CS Decomposition
For an orthogonal matrix expressed in block 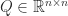
![\notag Q = \begin{array}[b]{@{\mskip33mu}c@{\mskip-16mu}c@{\mskip-10mu}c@{}} \scriptstyle p & \scriptstyle n-p & \\ \multicolumn{2}{c}{ \left[\begin{array}{c@{~}c@{~}} Q_{11}& Q_{12} \\ Q_{21}& Q_{22} \\ \end{array}\right]} & \mskip-12mu\ \begin{array}{c} \scriptstyle p \\ \scriptstyle n-p \end{array} \end{array}, \quad p \le \displaystyle\frac{n}{2}.](https://s0.wp.com/latex.php?latex=%5Cnotag++++Q+%3D++++%5Cbegin%7Barray%7D%5Bb%5D%7B%40%7B%5Cmskip33mu%7Dc%40%7B%5Cmskip-16mu%7Dc%40%7B%5Cmskip-10mu%7Dc%40%7B%7D%7D++++%5Cscriptstyle+p+%26++++%5Cscriptstyle+n-p+%26++++%5C%5C++++%5Cmulticolumn%7B2%7D%7Bc%7D%7B++++++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%40%7B%7E%7Dc%40%7B%7E%7D%7D++++++++++++++++++Q_%7B11%7D%26+Q_%7B12%7D+%5C%5C++++++++++++++++++Q_%7B21%7D%26+Q_%7B22%7D+%5C%5C++++++++++++++%5Cend%7Barray%7D%5Cright%5D%7D++++%26+%5Cmskip-12mu%5C++++++++++%5Cbegin%7Barray%7D%7Bc%7D++++++++++++++%5Cscriptstyle+p+%5C%5C++++++++++++++%5Cscriptstyle+n-p++++++++++++++%5Cend%7Barray%7D++++%5Cend%7Barray%7D%2C+%5Cquad+p+%5Cle+%5Cdisplaystyle%5Cfrac%7Bn%7D%7B2%7D.+&bg=ffffff&fg=222222&s=0&c=20201002)
Then there exist orthogonal matrices 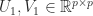

![\notag \begin{bmatrix} U_1^T & 0\\ 0 & U_2^T \end{bmatrix} \begin{bmatrix} Q_{11} & Q_{12}\\ Q_{21} & Q_{22} \end{bmatrix} \begin{bmatrix} V_1 & 0\\ 0 & V_2 \end{bmatrix} = \begin{array}[b]{@{\mskip35mu}c@{\mskip30mu}c@{\mskip-10mu}c@{}c} \scriptstyle p & \scriptstyle p & \scriptstyle n-2p & \\ \multicolumn{3}{c}{ \left[\begin{array}{c@{~}|c@{~}c} C & -S & 0 \\ \hline -S & C & 0 \\ 0 & 0 & I_{n-2p} \end{array}\right]} & \mskip-12mu \begin{array}{c} \scriptstyle p \\ \scriptstyle p \\ \scriptstyle n-2p \end{array} \end{array}, \qquad (11)](https://s0.wp.com/latex.php?latex=%5Cnotag++++%5Cbegin%7Bbmatrix%7D++U_1%5ET+%26+0%5C%5C++++++++++++++++++++++++++0+++%26+U_2%5ET++++%5Cend%7Bbmatrix%7D++++%5Cbegin%7Bbmatrix%7D++Q_%7B11%7D+%26+Q_%7B12%7D%5C%5C++++++++++++++++++++++++++Q_%7B21%7D+%26+Q_%7B22%7D++++%5Cend%7Bbmatrix%7D++++%5Cbegin%7Bbmatrix%7D++V_1+%26+0%5C%5C++++++++++++++++++++++++++0+++%26+V_2++++%5Cend%7Bbmatrix%7D++++%3D++++%5Cbegin%7Barray%7D%5Bb%5D%7B%40%7B%5Cmskip35mu%7Dc%40%7B%5Cmskip30mu%7Dc%40%7B%5Cmskip-10mu%7Dc%40%7B%7Dc%7D++++%5Cscriptstyle+p+%26++++%5Cscriptstyle+p+%26++++%5Cscriptstyle+n-2p+%26++++%5C%5C++++%5Cmulticolumn%7B3%7D%7Bc%7D%7B++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%40%7B%7E%7D%7Cc%40%7B%7E%7Dc%7D++++C+%26+++-S++++++%26+0+++%5C%5C++++%5Chline+++-S+%26++++C++++++%26+0+++%5C%5C++++0+%26++++0++++++%26+I_%7Bn-2p%7D++++%5Cend%7Barray%7D%5Cright%5D%7D++++%26+%5Cmskip-12mu++++%5Cbegin%7Barray%7D%7Bc%7D++++%5Cscriptstyle+p+%5C%5C++++%5Cscriptstyle+p+%5C%5C++++%5Cscriptstyle+n-2p++++%5Cend%7Barray%7D++++%5Cend%7Barray%7D%2C+%5Cqquad+%2811%29+&bg=ffffff&fg=222222&s=0&c=20201002)
where 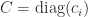
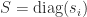
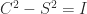
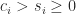
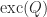
The leading principal submatrix ![\left[\begin{smallmatrix}C & -S \\ -S & C \end{smallmatrix}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Bsmallmatrix%7DC+%26+-S+%5C%5C+-S+%26+C+%5Cend%7Bsmallmatrix%7D%5Cright%5D&bg=ffffff&fg=222222&s=0&c=20201002)
Note that the matrix on the right in (11) is symmetric positive definite. Therefore the singular values of
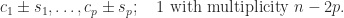
Since 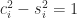
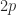
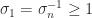
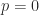
Numerical Stability
While an orthogonal matrix is perfectly conditioned, a pseudo-orthogonal matrix can be arbitrarily ill conditioned, as follows from (3). For example, the MATLAB function gallery('randjorth') produces a random pseudo-orthogonal matrix with a default condition number of sqrt(1/eps).
>> rng(1); A = gallery('randjorth',2,2) % p = 2, n = 4
A =
2.9984e+03 -4.2059e+02 1.5672e+03 -2.5907e+03
1.9341e+03 -2.6055e+03 3.1565e+03 -7.5210e+02
3.1441e+03 -6.2852e+02 1.8157e+03 -2.6427e+03
1.6870e+03 -2.5633e+03 3.0204e+03 -5.4157e+02
>> cond(A)
ans =
6.7109e+07
This means that algorithms that use pseudo-orthogonal matrices are potentially numerically unstable. Therefore algorithms need to be carefully constructed and rounding error analysis must be done to ensure that an appropriate form of numerical stability is obtained.
Notes
Pseudo-orthogonal matrices form the automorphism group of the scalar product defined by 

For 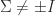
One can define pseudo-unitary matrices in an analogous way, as 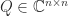
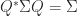
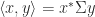
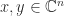
The exchange operator is also known as the principal pivot transform and as the sweep operator in statistics. Tsatsomeros (2000) gives a survey of its properties
The hyperbolic CS decomposition was derived by Lee (1948) and, according to Lee, was present in work of Autonne (1912).
References
This is a minimal set of references, which contain further useful references within.
- Adam Bojanczyk, Nicholas J. Higham and Harikrishna Patel, Solving the Indefinite Least Squares Problem by Hyperbolic QR Factorization, SIAM J. Matrix Anal. Appl. 24(3), 914–931, 2003
- Nicholas J. Higham,
- H. C. Lee, Canonical Factorization of Pseudo-Unitary Matrices, Proc. London Math. Soc. s2-50, 230–241, 1948.
- D. Steven Mackey, Niloufer Mackey, and Françoise Tisseur, Structured Factorizations in Scalar Product Spaces, SIAM J. Matrix Anal. Appl. 27(3), 821–850, 2006.
- Sara M. Motlaghian, Ali Armandnejad, and Frank J. Hall, Topological Properties of
- Michael Stewart and G. W. Stewart, On Hyperbolic Triangularization: Stability and Pivoting, SIAM J. Matrix Anal. Appl. 19(4), 847–860, 1998
- Michael J. Tsatsomeros, Principal Pivot Transforms: Properties and Applications, Linear Algebra Appl. 307, 151–165, 2000.
Related Blog Posts
- What Is an Orthogonal Matrix? (2020)
- What Is the CS Decomposition? (2020)
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
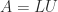 , where
, where  is unit lower triangular and
is unit lower triangular and  is upper triangular. “Unit” means that
is upper triangular. “Unit” means that ![\notag \left[\begin{array}{rrrr} 3 & -1 & 1 & 1\\ -1 & 3 & 1 & -1\\ -1 & -1 & 3 & 1\\ 1 & 1 & 1 & 3 \end{array}\right] = \left[\begin{array}{rrrr} 1 & 0 & 0 & 0\\ -\frac{1}{3} & 1 & 0 & 0\\ -\frac{1}{3} & -\frac{1}{2} & 1 & 0\\ \frac{1}{3} & \frac{1}{2} & 0 & 1 \end{array}\right] \left[\begin{array}{rrrr} 3 & -1 & 1 & 1\\ 0 & \frac{8}{3} & \frac{4}{3} & -\frac{2}{3}\\ 0 & 0 & 4 & 1\\ 0 & 0 & 0 & 3 \end{array}\right]. \qquad (1)](https://s0.wp.com/latex.php?latex=%5Cnotag++++%5Cleft%5B%5Cbegin%7Barray%7D%7Brrrr%7D++++++3+%26+-1+%26+1+%26+1%5C%5C+++++-1+%26+3+%26+1+%26+-1%5C%5C+++++-1+%26+-1+%26+3+%26+1%5C%5C++++++1+%26+1+%26+1+%26+3++++%5Cend%7Barray%7D%5Cright%5D+++%3D++++%5Cleft%5B%5Cbegin%7Barray%7D%7Brrrr%7D+++++1+%26+0+%26+0+%26+0%5C%5C++++-%5Cfrac%7B1%7D%7B3%7D+%26+1+%26+0+%26+0%5C%5C++++-%5Cfrac%7B1%7D%7B3%7D+%26+-%5Cfrac%7B1%7D%7B2%7D+%26+1+%26+0%5C%5C+++++%5Cfrac%7B1%7D%7B3%7D+%26+%5Cfrac%7B1%7D%7B2%7D+%26+0+%26+1++++%5Cend%7Barray%7D%5Cright%5D++++%5Cleft%5B%5Cbegin%7Barray%7D%7Brrrr%7D++++3+%26+-1+%26+1+%26+1%5C%5C++++0+%26+%5Cfrac%7B8%7D%7B3%7D+%26+%5Cfrac%7B4%7D%7B3%7D+%26+-%5Cfrac%7B2%7D%7B3%7D%5C%5C++++0+%26+0+%26+4+%26+1%5C%5C++++0+%26+0+%26+0+%26+3++++%5Cend%7Barray%7D%5Cright%5D.+%5Cqquad+%281%29+&bg=ffffff&fg=222222&s=0&c=20201002)
 reduces to solving the triangular systems
reduces to solving the triangular systems 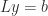 and
and  , since then
, since then  .
.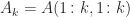 the leading principal submatrix of
the leading principal submatrix of  .
. is nonsingular for
is nonsingular for  . If
. If  then the factorization may exist, but if so it is not unique.
then the factorization may exist, but if so it is not unique. then the
then the  are necessarily nonsingular and so
are necessarily nonsingular and so  . The left side of this equation is unit lower triangular and the right side is upper triangular; therefore both sides must equal the identity matrix, which means that
. The left side of this equation is unit lower triangular and the right side is upper triangular; therefore both sides must equal the identity matrix, which means that  and
and  , as required.
, as required. , which implies that
, which implies that  . Hence
. Hence 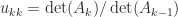 . In fact, such determinantal formulas hold for all the elements of
. In fact, such determinantal formulas hold for all the elements of ![\notag \begin{aligned} \ell_{ij} &= \frac{ \det\bigl( A( [1:j-1, \, i], 1:j ) \bigr) }{ \det( A_j ) }, \quad i > j, \\ u_{ij} &= \frac{ \det\bigl( A( 1:i, [1:i-1, \, j] ) \bigr) } { \det( A_{i-1} ) }, \quad i \le j. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cnotag++++%5Cbegin%7Baligned%7D++++%5Cell_%7Bij%7D+%26%3D+%5Cfrac%7B+%5Cdet%5Cbigl%28+A%28+%5B1%3Aj-1%2C+%5C%2C+i%5D%2C+1%3Aj+%29+%5Cbigr%29+%7D%7B+%5Cdet%28+A_j+%29+%7D%2C+++++++++++++%5Cquad+i+%3E+j%2C+%5C%5C++++u_%7Bij%7D+%26%3D+%5Cfrac%7B+%5Cdet%5Cbigl%28+A%28+1%3Ai%2C+%5B1%3Ai-1%2C+%5C%2C+j%5D+%29+%5Cbigr%29+%7D+++++++++++++++++++%7B+%5Cdet%28+A_%7Bi-1%7D+%29+%7D%2C+++++++++++++%5Cquad+i+%5Cle+j.++++%5Cend%7Baligned%7D+&bg=ffffff&fg=222222&s=0&c=20201002)
 , where
, where  and
and  are vectors of subscripts, denotes the submatrix formed from the intersection of the rows indexed by
are vectors of subscripts, denotes the submatrix formed from the intersection of the rows indexed by 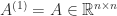 to upper triangular form
to upper triangular form 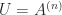 in
in  stages. At the
stages. At the 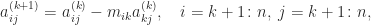
 are the multipliers. Of course each
are the multipliers. Of course each 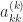 must be nonzero for these formulas to be defined, and this is connected with the conditions of Theorem 1, since
must be nonzero for these formulas to be defined, and this is connected with the conditions of Theorem 1, since  . The final
. The final  for
for 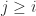 , and
, and  for
for  , that is, the multipliers make up the
, that is, the multipliers make up the  we can just solve
we can just solve  and
and  , re-using the LU factorization. Similarly, solving
, re-using the LU factorization. Similarly, solving  reduces to solving the triangular systems
reduces to solving the triangular systems  and
and  .
.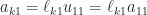 then determines the first column of
then determines the first column of  . This leads to the Doolittle method, which involves inner products of partial rows of
. This leads to the Doolittle method, which involves inner products of partial rows of 
 ordering of the loops in the factorization is the basis of early Fortran implementations of LU factorization, such as that in LINPACK. The inner loop travels down the columns of
ordering of the loops in the factorization is the basis of early Fortran implementations of LU factorization, such as that in LINPACK. The inner loop travels down the columns of  ordering, which updates the matrix a row at a time, and is appropriate for a language such as C that stores arrays by row.
ordering, which updates the matrix a row at a time, and is appropriate for a language such as C that stores arrays by row. and
and  orderings correspond to the Doolittle method. The last two of the
orderings correspond to the Doolittle method. The last two of the  orderings are the
orderings are the 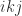 and
and  orderings, to which we will return later.
orderings, to which we will return later. we can write
we can write
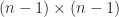 matrix
matrix  is called the Schur complement of
is called the Schur complement of  in
in  and
and  have the correct forms for a unit lower triangular matrix and an upper triangular matrix, respectively. If we can find an LU factorization
have the correct forms for a unit lower triangular matrix and an upper triangular matrix, respectively. If we can find an LU factorization  then
then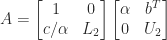
 . If we can show that the Schur complement inherits the same structure then it follows by induction that we can compute the factorization for
. If we can show that the Schur complement inherits the same structure then it follows by induction that we can compute the factorization for 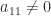 and
and  -matrices,
-matrices, if
if 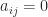 for
for  and lower bandwidth
and lower bandwidth  if
if  . Another use of (2) is to show that
. Another use of (2) is to show that  and
and  have only
have only  :
:
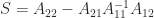 . This leads to the following algorithm:
. This leads to the following algorithm: .
. for
for  .
. for
for  .
. .
. .
. partitioning, in which we assume we have already computed the first block column of
partitioning, in which we assume we have already computed the first block column of 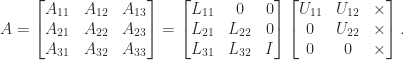
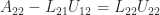 .
. for
for  .
. —
— .
. lower triangular and
lower triangular and 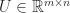 upper trapezoidal. The conditions for existence and uniqueness of an LU factorization of
upper trapezoidal. The conditions for existence and uniqueness of an LU factorization of 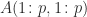 , where
, where  .
.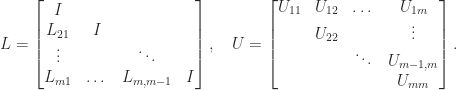
![\notag A = \left[ \begin{array}{rr|rr} 0 & 1 & 1 & 1 \\ -1 & 1 & 1 & 1 \\\hline -2 & 3 & 4 & 2 \\ -1 & 2 & 1 & 3 \\ \end{array} \right] = \left[ \begin{array}{cc|cc} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\\hline 1 & 2 & 1 & 0 \\ 1 & 1 & 0 & 1 \\ \end{array} \right] \left[ \begin{array}{rr|rr} 0 & 1 & 1 & 1 \\ -1 & 1 & 1 & 1 \\\hline 0 & 0 & 1 & -1 \\ 0 & 0 & -1 & 1 \\ \end{array} \right].](https://s0.wp.com/latex.php?latex=%5Cnotag+++++A+%3D++++++%5Cleft%5B+%5Cbegin%7Barray%7D%7Brr%7Crr%7D++++++0++%26++1++%26++1++%26++1++%5C%5C+++++-1++%26++1++%26++1++%26++1++%5C%5C%5Chline+++++-2++%26++3++%26++4++%26++2++%5C%5C+++++-1++%26++2++%26++1++%26++3++%5C%5C+++++++++++++%5Cend%7Barray%7D++++++%5Cright%5D++++++%3D++++++%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7Ccc%7D++++++1++%26++0++%26++0++%26++0++%5C%5C++++++0++%26++1++%26++0++%26++0++%5C%5C%5Chline++++++1++%26++2++%26++1++%26++0++%5C%5C++++++1++%26++1++%26++0++%26++1++%5C%5C+++++++++++++%5Cend%7Barray%7D++++++%5Cright%5D++++++%5Cleft%5B+%5Cbegin%7Barray%7D%7Brr%7Crr%7D++++++0++%26++1++%26++1++%26++1++%5C%5C+++++-1++%26++1++%26++1++%26++1++%5C%5C%5Chline++++++0++%26++0++%26++1++%26+-1++%5C%5C++++++0++%26++0++%26+-1++%26++1++%5C%5C+++++++++++++%5Cend%7Barray%7D++++++%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
 submatrix. In the context of a linear system
submatrix. In the context of a linear system 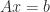 , we have effectively solved for the variables
, we have effectively solved for the variables  and
and  and then substituted for
and then substituted for  leading principal block submatrices of
leading principal block submatrices of  involving the diagonal blocks of
involving the diagonal blocks of  an LU factorization
an LU factorization 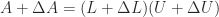 exists. To first order, this equation is
exists. To first order, this equation is  , which gives
, which gives
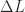 is strictly lower triangular and
is strictly lower triangular and  is upper triangular, we have, to first order,
is upper triangular, we have, to first order,
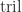 denotes the strictly lower triangular part and
denotes the strictly lower triangular part and  the strictly upper triangular part. Clearly, the sensitivity of the LU factors depends on the inverses of
the strictly upper triangular part. Clearly, the sensitivity of the LU factors depends on the inverses of 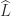 and
and 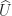 are numerically stable in the sense that
are numerically stable in the sense that  with
with  , where
, where 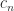 is a constant and
is a constant and 
![\notag \left[\begin{array}{rrr} 3 & -1 & -2\\ -2 & 3 & -1\\ -2 & -1 & 3 \end{array}\right] \qquad (1)](https://s0.wp.com/latex.php?latex=%5Cnotag++%5Cleft%5B%5Cbegin%7Barray%7D%7Brrr%7D+++++3+%26+-1+%26+-2%5C%5C++++-2+%26++3+%26+-1%5C%5C++++-2+%26+-1+%26++3+++%5Cend%7Barray%7D%5Cright%5D+%5Cqquad+%281%29+&bg=ffffff&fg=222222&s=0&c=20201002)
![[1~1~1]^T](https://s0.wp.com/latex.php?latex=%5B1%7E1%7E1%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002) is a null vector. A useful definition of a matrix with large diagonal requires a stronger property.
is a null vector. A useful definition of a matrix with large diagonal requires a stronger property. is diagonally dominant by rows if
is diagonally dominant by rows if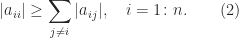
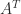 is (strictly) diagonally dominant by rows.
is (strictly) diagonally dominant by rows. let
let  and choose
and choose  . Then the
. Then the 

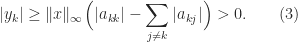
 and so
and so  such that
such that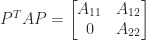
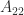 square matrices. Irreducibility is equivalent to the directed graph of
square matrices. Irreducibility is equivalent to the directed graph of  for some
for some 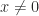 such that
such that 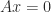 . Define
. Define

 ,
,
 is nonempty, because if it were empty then we would have
is nonempty, because if it were empty then we would have  for all
for all  , then putting
, then putting 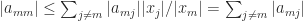 , which is a contradiction. Hence as long as
, which is a contradiction. Hence as long as  for some
for some 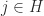 , we obtain
, we obtain  , which contradicts the diagonal dominance. Therefore we must have
, which contradicts the diagonal dominance. Therefore we must have  for all
for all  . This means that all the rows indexed by
. This means that all the rows indexed by  have zeros in the columns indexed by
have zeros in the columns indexed by ![\notag T_n = \left[\begin{array}{@{\mskip 5mu}c*{4}{@{\mskip 15mu} r}@{\mskip 5mu}} 2 & -1 & & & \\ -1 & 2 & -1 & & \\ & -1 & 2 & \ddots & \\ & & \ddots & \ddots & -1\\ & & & -1 & 2 \end{array}\right], \qquad (5)](https://s0.wp.com/latex.php?latex=%5Cnotag++T_n+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip+5mu%7Dc%2A%7B4%7D%7B%40%7B%5Cmskip+15mu%7D+r%7D%40%7B%5Cmskip+5mu%7D%7D++++++2+%26+++-1++%26++++++++++%26+++++++++%26+%5C%5C+++++-1+%26++++2++%26++-1++++++%26+++++++++%26+%5C%5C++++++++%26++++-1+%26+++2++++++%26++%5Cddots+%26+%5C%5C++++++++%26+++++++%26++%5Cddots++%26++%5Cddots+%26+-1%5C%5C++++++++%26+++++++%26++++++++++%26++-1+++++%26+2++++++++++++%5Cend%7Barray%7D%5Cright%5D%2C+%5Cqquad+%285%29+&bg=ffffff&fg=222222&s=0&c=20201002)
 or
or  by
by  , then
, then  remains nonsingular by the same argument. What if we replace both
remains nonsingular by the same argument. What if we replace both 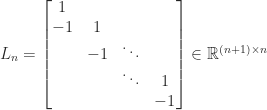
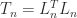 and
and
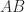 and
and 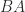 have the same nonzero eigenvalues, we conclude that
have the same nonzero eigenvalues, we conclude that  , where
, where  denotes the spectrum. Hence
denotes the spectrum. Hence 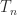 is symmetric positive definite and
is symmetric positive definite and 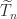 is singular and symmetric positive semidefinite.
is singular and symmetric positive semidefinite. is singular and hence cannot be strictly diagonally dominant, by Theorem 1. So
is singular and hence cannot be strictly diagonally dominant, by Theorem 1. So 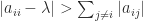 cannot be true for all
cannot be true for all 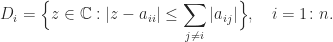
 , so
, so  , so the eigenvalues are nonnegative, and hence positive since nonzero. This provides another proof that the matrix
, so the eigenvalues are nonnegative, and hence positive since nonzero. This provides another proof that the matrix 

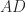 is diagonally dominant by rows for some diagonal matrix
is diagonally dominant by rows for some diagonal matrix 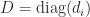 with
with  for all
for all 
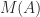 , defined by
, defined by
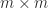 partitioning
partitioning 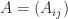 , the diagonal blocks
, the diagonal blocks  are all nonsingular and
are all nonsingular and
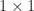 then block diagonal dominance reduces to the usual notion of diagonal dominance. Block diagonal dominance holds for certain block tridiagonal matrices arising in the discretization of PDEs.
then block diagonal dominance reduces to the usual notion of diagonal dominance. Block diagonal dominance holds for certain block tridiagonal matrices arising in the discretization of PDEs.
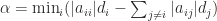 .
.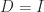 . Let
. Let  satisfy
satisfy  and let
and let  . The result is obtained on applying this bound to
. The result is obtained on applying this bound to 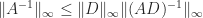 .
.  , where
, where 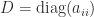 ,
, 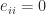 , and
, and  for
for 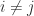 . It is easy to see that
. It is easy to see that  , which gives another proof that
, which gives another proof that 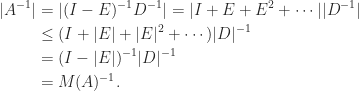
 , so in view of its sign pattern
, so in view of its sign pattern 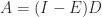 .
.
 .
.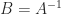 satisfies
satisfies 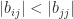 for all
for all  . Let
. Let 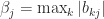 . Taking absolute values in
. Taking absolute values in  gives
gives
 , since
, since 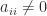 . This inequality holds for all
. This inequality holds for all 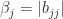 , which gives the result.
, which gives the result.