Backward error is a measure of error associated with an approximate solution to a problem. Whereas the forward error is the distance between the approximate and true solutions, the backward error is how much the data must be perturbed to produce the approximate solution.
For a function 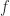


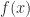
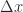
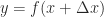
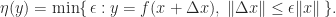
In the following figure the solid lines denote exact mappings and the dashed line shows the mapping that was actually computed.

Usually, but not always, the errors in question are rounding errors, but backward error can also be a useful way to characterize truncation errors (for example in deriving algorithms based on Padé approximation for computing matrix functions).
As an example, for the inner product 


where 
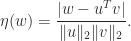
The definition of 


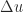

For some problems a backward error may not exist. An example is computation of the outer product 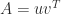

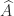

Backward error analysis refers to rounding error analysis in which a bound is obtained for a suitably defined backward error. If the backward error can be shown to be small then
Backward error analysis was developed and popularized by James Wilkinson in the 1950s and 1960s. He first used it in the context of computing zeros of polynomials, but the method’s biggest successes came when he applied it to linear algebra computations.
Backward error analysis has also been used in the context of the numerical solution of differential equations, where it is used in different forms known as defect control and shadowing.
The forward error of 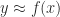
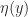
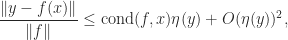
in view of the definition of condition number. Consequently, we have the rule of thumb that

References
This is a minimal set of references, which contain further useful references within.
- Robert M. Corless and Nicolas Fillion, A Graduate Introduction to Numerical Methods from the Viewpoint of Backward Error Analysis, Springer, 2013.
- Wayne Hayes and Kenneth R. Jackson, A survey of shadowing methods for numerical solutions of ordinary differential equations, Appl. Numer. Math. 53, 299–321, 2005.
- Nicholas J. Higham, Accuracy and Stability of Numerical Algorithms, second edition, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2002.
Related Blog Posts
- What Is a Condition Number? (2020).
- Wilkinson and Backward Error Analysis (with Sven Hammarling, 2019).
- Wilkinson Quotes (with Sven Hammarling, 2019).
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.

This blog post series is a great idea, thanks Nick! Backward error analysis is one of the most elegant ideas in numerical analysis. Something that helped me to “demystify” this type of analysis was to realize that for some common problems (such as linear systems) the global optimization problem is simply a standard linear least-squares problem (when using the Frobenius norm). For other problems, one can linearize first via Taylor and then solve the linear least-squares problem. This gives a first-order estimate of the backward error and is probably not very elegant, but it is probably sufficient for the last two inequalities stated in your blog post.