In a keynote talk at JuliaCon 2018 I described a variety of tricks, tips and techniques that I’ve found useful in my work in numerical computing.
The first part of the talk was about two aspects of complex arithmetic: the complex step method for approximating derivatives, and understanding multivalued functions with the help of the unwinding number. Then I talked about the role of the associativity of matrix multiplication, which turns out to be the key property that makes the Sherman-Morrison formula work (this formula gives the inverse of a matrix after a rank 1 update). I pointed out the role of associativity in backpropagation in neural networks and deep learning.
After giving an example of using randomization to avoid pathological cases, I discussed why low precision (specifically half precision) arithmetic is of growing interest and identified some issues that need to be overcome in order to make the best use of it.
Almost every talk at JuliaCon was livecast on YouTube, and these talks are available to watch on the Julia Language channel. The slides for my talk are available here.
Also at the conference, my PhD student Weijian Zhang spoke about the work he has been doing on evolving graphs in his PhD.
The logarithm was first presented in John Napier’s 1614 book Mirifici Logarithmorum Canonis Descriptio (Description of the Wonderful Canon of Logarithms). Last week I was celebrating 400 years of logarithms at the Napier 400 workshop held at the ICMS in Edinburgh and organized by NAIS. The previous such celebrations had been in 1914 and, as one speaker remarked, it is nice to participate in an event held only once every 100 years.
This one-day workshop included talks by Mike Giles on computing logarithms and other special functions on GPUs, and Jacek Gondzio on the history of the logarithmic barrier function in linear and nonlinear optimization.
My interest is in the matrix logarithm. The earliest explicit occurrence that I am aware of is in an 1892 paper by Metzler On the Roots of Matrices, so we are only just into the second century of matrix logarithms.
Photo and Tweet by @DesHigham: “@nhigham introduced by Dugald Duncan at @ICMS_Edinburgh”.
In my talk The Matrix Logarithm: from Theory to Computation I explained how the inverse scaling and squaring (ISS) algorithm that we use today to compute the matrix logarithm is a direct analogue of the method Henry Briggs used to produce his 1624 tables Arithmetica Logarithmica, which give logarithms to the base 10 of the numbers 1–20,000 and 90,000–100,000 to 14 decimal places. Briggs’s impressive hand computations were done by using the formulas and to write . The ISS algorithm for the matrix case uses the same idea, with the square roots being matrix square roots, but approximates at a matrix argument using Padé approximants, evaluated using a partial fraction expansion. The Fréchet derivative of the logarithm can be obtained by Fréchet differentiating the formulas used in the ISS algorithm. For details see Improved Inverse Scaling and Squaring Algorithms for the Matrix Logarithm (2012) and Computing the Fréchet Derivative of the Matrix Logarithm and Estimating the Condition Number (2013).
As well as the logarithm itself, various log-like functions are of interest nowadays. One is the unwinding function, discussed in my previous post. Another is the Lambert W function, defined as the solution of . Its many applications include the solution of delay differential equations. Rob Corless and his colleagues produced a wonderful poster about the Lambert W function, which I have on my office wall. Cleve Moler has a recent blog post on the function.
A few years ago I wrote a paper with Rob, Hui Ding and David Jeffrey about the matrix Lambert W function: The solution of S exp(S) = A is not always the Lambert W function of A. We show that as a primary matrix function the Lambert function does not yield all solutions to , just as the primary logarithm does not yield all solutions to . I am involved in some further work on the matrix Lambert W function and hope to have more to report in due course.

 and
and 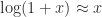 to write
to write 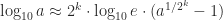 . The ISS algorithm for the matrix case uses the same idea, with the square roots being matrix square roots, but approximates
. The ISS algorithm for the matrix case uses the same idea, with the square roots being matrix square roots, but approximates 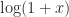 at a matrix argument using Padé approximants, evaluated using a partial fraction expansion. The Fréchet derivative of the logarithm can be obtained by Fréchet differentiating the formulas used in the ISS algorithm. For details see
at a matrix argument using Padé approximants, evaluated using a partial fraction expansion. The Fréchet derivative of the logarithm can be obtained by Fréchet differentiating the formulas used in the ISS algorithm. For details see 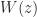 of
of 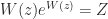 . Its many applications include the solution of delay differential equations. Rob Corless and his colleagues produced a
. Its many applications include the solution of delay differential equations. Rob Corless and his colleagues produced a 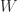 function does not yield all solutions to
function does not yield all solutions to 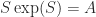 , just as the primary logarithm does not yield all solutions to
, just as the primary logarithm does not yield all solutions to 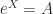 . I am involved in some further work on the matrix Lambert W function and hope to have more to report in due course.
. I am involved in some further work on the matrix Lambert W function and hope to have more to report in due course.