A sparse matrix is one with a large number of zero entries. A more practical definition is that a matrix is sparse if the number or distribution of the zero entries makes it worthwhile to avoid storing or operating on the zero entries.
Sparsity is not to be confused with data sparsity, which refers to the situation where, because of redundancy, the data can be efficiently compressed while controlling the loss of information. Data sparsity typically manifests itself in low rank structure, whereas sparsity is solely a property of the pattern of nonzeros.
Important sources of sparse matrices include discretization of partial differential equations, image processing, optimization problems, and networks and graphs. In designing algorithms for sparse matrices we have several aims.
- Store the nonzeros only, in some suitable data structure.
- Avoid operations involving only zeros.
- Preserve sparsity, that is, minimize fill-in (a zero element becoming nonzero).
We wish to achieve these aims without sacrificing speed, stability, or reliability.
An important class of sparse matrices is banded matrices. A matrix  has bandwidth
has bandwidth  if the elements outside the main diagonal and the first superdiagonals and subdiagonals are zero, that is, if
if the elements outside the main diagonal and the first superdiagonals and subdiagonals are zero, that is, if 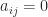 for
for 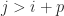 and
and  .
.
The most common type of banded matrix is a tridiagonal matrix  ), of which an archetypal example is the second-difference matrix, illustrated for
), of which an archetypal example is the second-difference matrix, illustrated for 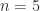 by
by
![\notag A_5 = \left[ \begin{array}{@{}*{4}{r@{\mskip10mu}}r} 2 & -1 & 0 & 0 & 0\\ -1 & 2 & -1 & 0 & 0\\ 0 & -1 & 2 & -1 & 0\\ 0 & 0 &-1 & 2 & -1\\ 0 & 0 & 0 & -1 & 2 \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cnotag++++A_5+%3D+%5Cleft%5B++++%5Cbegin%7Barray%7D%7B%40%7B%7D%2A%7B4%7D%7Br%40%7B%5Cmskip10mu%7D%7Dr%7D+++++++++++++++++2+%26++-1++%26+0++%26+0+%26+0%5C%5C+++++++++++++++++-1+%26+2++%26+-1++%26+0+%26+0%5C%5C++++++++++++++++++0+%26+-1++%26+2+%26+-1+%26+0%5C%5C++++++++++++++++++0+%26++0++%26-1+%26+2++%26+-1%5C%5C++++++++++++++++++0+%26++0++%26+0+%26+-1+%26+2++++%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
This matrix (or more precisely its negative) corresponds to a centered finite difference approximation to a second derivative: 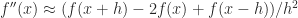 .
.
The following plots show the sparsity patterns for two symmetric positive definite matrices. Here, the nonzero elements are indicated by dots.
 The matrices are both from power network problems and they are taken from the SuiteSparse Matrix Collection (
The matrices are both from power network problems and they are taken from the SuiteSparse Matrix Collection (https://sparse.tamu.edu/). The matrix names are shown in the titles and the nz values below the  -axes are the numbers of nonzeros. The plots were produced using MATLAB code of the form
-axes are the numbers of nonzeros. The plots were produced using MATLAB code of the form
W = ssget('HB/494_bus'); A = W.A; spy(A)
where the ssget function is provided with the collection. The matrix on the left shows no particular pattern for the nonzero entries, while that on the right has a structure comprising four diagonal blocks with a relatively small number of elements connecting the blocks.
It is important to realize that while the sparsity pattern often reflects the structure of the underlying problem, it is arbitrary in that it will change under row and column reorderings. If we are interested in solving  , for example, then for any permutation matrices
, for example, then for any permutation matrices  and
and  we can form the transformed system
we can form the transformed system 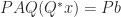 , which has a coefficient matrix
, which has a coefficient matrix  having permuted rows and columns, a permuted right-hand side
having permuted rows and columns, a permuted right-hand side  , and a permuted solution. We usually wish to choose the permutations to minimize the fill-in or (almost equivalently) the number of nonzeros in
, and a permuted solution. We usually wish to choose the permutations to minimize the fill-in or (almost equivalently) the number of nonzeros in  and
and  . Various methods have been derived for this task; they are necessarily heuristic because finding the minimum is in general an NP-complete problem. When is symmetric we take
. Various methods have been derived for this task; they are necessarily heuristic because finding the minimum is in general an NP-complete problem. When is symmetric we take  in order to preserve symmetry.
in order to preserve symmetry.
For the HB/494_bus matrix the symmetric reverse Cuthill-McKee permutation gives a reordered matrix with the following sparsity pattern, plotted with the MATLAB commands
r = symrcm(A); spy(A(r,r))

The reordered matrix with a variable band structure that is characteristic of the symmetric reverse Cuthill-McKee permutation. The number of nonzeros is, of course, unchanged by reordering, so what has been gained? The next plots show the Cholesky factors of the HB/494_bus matrix and the reordered matrix. The Cholesky factor for the reordered matrix has a much narrower bandwidth than that for the original matrix and has fewer nonzeros by a factor 3. Reordering has greatly reduced the amount of fill-in that occurs; it leads to a Cholesky factor that is cheaper to compute and requires less storage.
Because Cholesky factorization is numerically stable, the matrix can be permuted without affecting the numerical stability of the computation. For a nonsymmetric problem the choice of row and column interchanges also needs to take into account the need for numerical stability, which complicates matters.
The world of sparse matrix computations is very different from that for dense matrices. In the first place, sparse matrices are not stored as  arrays, but rather just the nonzeros are stored, in some suitable data structure. Programming sparse matrix computations is, consequently, more difficult than for dense matrix computations. A second difference from the dense case is that certain operations are, for practical purposes, forbidden, Most notably, we never invert sparse matrices because of the possibly severe fill-in. Indeed the inverse of a sparse matrix is usually dense. For example, the inverse of the tridiagonal matrix given at the start of this article is
arrays, but rather just the nonzeros are stored, in some suitable data structure. Programming sparse matrix computations is, consequently, more difficult than for dense matrix computations. A second difference from the dense case is that certain operations are, for practical purposes, forbidden, Most notably, we never invert sparse matrices because of the possibly severe fill-in. Indeed the inverse of a sparse matrix is usually dense. For example, the inverse of the tridiagonal matrix given at the start of this article is

While it is always true that one should not solve by forming  , for reasons of cost and numerical stability (unless is orthogonal!), it is even more true when is sparse.
, for reasons of cost and numerical stability (unless is orthogonal!), it is even more true when is sparse.
Finally, we mention an interesting property of  . Its upper triangle agrees with the upper triangle of the rank-
. Its upper triangle agrees with the upper triangle of the rank- matrix
matrix

This property generalizes to other tridiagonal matrices. So while a tridiagonal matrix is sparse, its inverse is data sparse—as it has to be because in general depends on 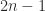 parameters and hence so does
parameters and hence so does  . One implication of this property is that it is possible to compute the condition number
. One implication of this property is that it is possible to compute the condition number  of a tridiagonal matrix in
of a tridiagonal matrix in 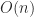 flops.
flops.
References
This is a minimal set of references, which contain further useful references within.
- Timothy A. Davis, Direct Methods for Sparse Linear Systems, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2006.
- Timothy A. Davis, Sivasankaran Rajamanickam, and Wissam M. Sid-Lakhdar, A Survey of Direct Methods for Sparse Linear Systems, Acta Numerica 25, 383–566, 2016.
- Timothy A. Davis and Yifan Hu, The University of Florida Sparse Matrix Collection, ACM Trans. Math. Software 38 (1), 1:1–1:25, 2011. Note: this collection is now called the SuiteSparse Matrix Collection.
- Gareth I. Hargreaves, Computing the Condition Number of Tridiagonal and Diagonal-Plus-Semiseparable Matrices in Linear Time, SIAM J. Matrix Anal. Appl. 27, 801–820, 2006.
- Gérard Meurant, A Review on the Inverse of Symmetric Tridiagonal and Block Tridiagonal Matrices, SIAM J. Matrix Anal. Appl. 13, 707–728, 1992.
- Yousef Saad, Iterative Methods for Sparse Linear Systems, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2003.
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.



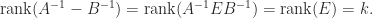








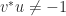

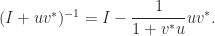
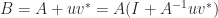





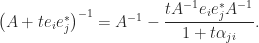
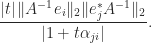





![\notag T = \left[\begin{array}{rrrr} 1 & -1 & -2 & -3\\ 0 & 1 & -4 & -5\\ 0 & 0 & 1 & -6\\ 0 & 0 & 0 & 1 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cnotag++T+%3D++%5Cleft%5B%5Cbegin%7Barray%7D%7Brrrr%7D+++1+%26+-1+%26+-2+%26+-3%5C%5C+++0+%26+1+%26+-4+%26+-5%5C%5C+++0+%26+0+%26+1+%26+-6%5C%5C+++0+%26+0+%26+0+%26+1+++%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=222222&s=0&c=20201002)


![\notag \left[\begin{array}{cccc} 0.044 & 0.029 & 0.006 & 0.001 \\ 0.063 & 0.041 & 0.009 & 0.001 \\ 0.322 & 0.212 & 0.044 & 0.007 \\ 2.258 & 1.510 & 0.321 & 0.053 \\ \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cnotag+++%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccc%7D++0.044++%26++0.029++%26++0.006++%26++0.001++%5C%5C++0.063++%26++0.041++%26++0.009++%26++0.001++%5C%5C++0.322++%26++0.212++%26++0.044++%26++0.007++%5C%5C++2.258++%26++1.510++%26++0.321++%26++0.053++%5C%5C+++%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=222222&s=0&c=20201002)

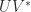



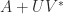


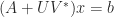







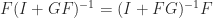



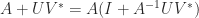

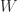


![\notag \begin{aligned} \begin{bmatrix} A & U \\ V^* & -W^{-1} \end{bmatrix}^{-1} &= \begin{bmatrix} I & -A^{-1}U \\ 0 & I \end{bmatrix}. \begin{bmatrix} A^{-1} & 0 \\ 0 & -(W^{-1} + V^*A^{-1}U)^{-1} \end{bmatrix} \begin{bmatrix} I & 0 \\ -V^*A^{-1} & I \end{bmatrix}\\[\smallskipamount] &= \begin{bmatrix} A^{-1} - A^{-1}U(W^{-1} + V^*A^{-1}U)^{-1}V^*A^{-1} & A^{-1}U(W^{-1} + V^*A^{-1U})^{-1} \\ (W^{-1} + V^*A^{-1}U)^{-1} V^*A^{-1} & -(W^{-1} + V^*A^{-1}U)^{-1} \end{bmatrix}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cnotag+%5Cbegin%7Baligned%7D++++%5Cbegin%7Bbmatrix%7D+A+%26+U+%5C%5C+V%5E%2A+%26+-W%5E%7B-1%7D+%5Cend%7Bbmatrix%7D%5E%7B-1%7D+++++%26%3D++++%5Cbegin%7Bbmatrix%7D+I+%26+-A%5E%7B-1%7DU+%5C%5C+0+%26+I+%5Cend%7Bbmatrix%7D.++++%5Cbegin%7Bbmatrix%7D+A%5E%7B-1%7D+%26+0+%5C%5C+0+%26+-%28W%5E%7B-1%7D+%2B+V%5E%2AA%5E%7B-1%7DU%29%5E%7B-1%7D+%5Cend%7Bbmatrix%7D++++%5Cbegin%7Bbmatrix%7D+I+%26+0+%5C%5C+-V%5E%2AA%5E%7B-1%7D+%26+I+%5Cend%7Bbmatrix%7D%5C%5C%5B%5Csmallskipamount%5D+++++%26%3D++++%5Cbegin%7Bbmatrix%7D+A%5E%7B-1%7D+-+A%5E%7B-1%7DU%28W%5E%7B-1%7D+%2B+V%5E%2AA%5E%7B-1%7DU%29%5E%7B-1%7DV%5E%2AA%5E%7B-1%7D+%26++++++++++++++++++++A%5E%7B-1%7DU%28W%5E%7B-1%7D+%2B+V%5E%2AA%5E%7B-1U%7D%29%5E%7B-1%7D+%5C%5C++++++++++%28W%5E%7B-1%7D+%2B+V%5E%2AA%5E%7B-1%7DU%29%5E%7B-1%7D+V%5E%2AA%5E%7B-1%7D+%26+-%28W%5E%7B-1%7D+%2B+V%5E%2AA%5E%7B-1%7DU%29%5E%7B-1%7D++++++%5Cend%7Bbmatrix%7D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=222222&s=0&c=20201002)
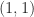
![P = \bigl[\begin{smallmatrix} 0 & I \\ I & 0 \end{smallmatrix} \bigr]](https://s0.wp.com/latex.php?latex=P+%3D+%5Cbigl%5B%5Cbegin%7Bsmallmatrix%7D+0+%26+I+%5C%5C+I+%26+0+%5Cend%7Bsmallmatrix%7D+%5Cbigr%5D&bg=ffffff&fg=222222&s=0&c=20201002)

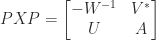


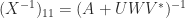



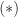
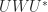
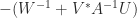

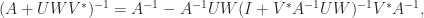


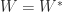
 matrix (two block rows and two block columns). For
matrix (two block rows and two block columns). For  , partitioning into
, partitioning into ![\notag A = \left[\begin{array}{cc|cc} a_{11} & a_{12} & a_{13} & a_{14}\\ a_{21} & a_{22} & a_{23} & a_{24}\\\hline a_{31} & a_{32} & a_{33} & a_{34}\\ a_{41} & a_{42} & a_{43} & a_{44}\\ \end{array}\right] = \begin{bmatrix} A_{11} & A_{12} \\ A_{21} & A_{22} \end{bmatrix},](https://s0.wp.com/latex.php?latex=%5Cnotag+++A+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7Ccc%7D+++++++++a_%7B11%7D+%26+a_%7B12%7D+%26+a_%7B13%7D+%26+a_%7B14%7D%5C%5C+++++++++a_%7B21%7D+%26+a_%7B22%7D+%26+a_%7B23%7D+%26+a_%7B24%7D%5C%5C%5Chline+++++++++a_%7B31%7D+%26+a_%7B32%7D+%26+a_%7B33%7D+%26+a_%7B34%7D%5C%5C+++++++++a_%7B41%7D+%26+a_%7B42%7D+%26+a_%7B43%7D+%26+a_%7B44%7D%5C%5C+++++++++%5Cend%7Barray%7D%5Cright%5D++++%3D++%5Cbegin%7Bbmatrix%7D+++++++++A_%7B11%7D+%26+A_%7B12%7D+%5C%5C+++++++++A_%7B21%7D+%26+A_%7B22%7D++++++++%5Cend%7Bbmatrix%7D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
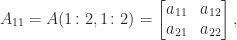
 matrix could be partitioned as
matrix could be partitioned as![\notag A = \left[\begin{array}{c|ccc} a_{11} & a_{12} & a_{13} & a_{14}\\\hline a_{21} & a_{22} & a_{23} & a_{24}\\ a_{31} & a_{32} & a_{33} & a_{34}\\ a_{41} & a_{42} & a_{43} & a_{44}\\ \end{array}\right] = \begin{bmatrix} A_{11} & A_{12} \\ A_{21} & A_{22} \end{bmatrix},](https://s0.wp.com/latex.php?latex=%5Cnotag+++A+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7Cccc%7D+++++++++a_%7B11%7D+%26+a_%7B12%7D+%26+a_%7B13%7D+%26+a_%7B14%7D%5C%5C%5Chline+++++++++a_%7B21%7D+%26+a_%7B22%7D+%26+a_%7B23%7D+%26+a_%7B24%7D%5C%5C+++++++++a_%7B31%7D+%26+a_%7B32%7D+%26+a_%7B33%7D+%26+a_%7B34%7D%5C%5C+++++++++a_%7B41%7D+%26+a_%7B42%7D+%26+a_%7B43%7D+%26+a_%7B44%7D%5C%5C+++++++++%5Cend%7Barray%7D%5Cright%5D++++%3D++%5Cbegin%7Bbmatrix%7D+++++++++A_%7B11%7D+%26+A_%7B12%7D+%5C%5C+++++++++A_%7B21%7D+%26+A_%7B22%7D++++++++%5Cend%7Bbmatrix%7D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
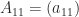 is a scalar,
is a scalar, 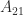 is a column vector, and
is a column vector, and 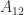 is a row vector.
is a row vector. of two block matrices
of two block matrices 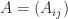 and
and 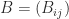 of the same dimension is obtained by adding blockwise as long as
of the same dimension is obtained by adding blockwise as long as 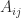 and
and 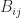 have the same dimensions for all
have the same dimensions for all  ,
, of an
of an 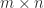 matrix
matrix 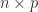 matrix
matrix 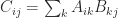 as long as the products
as long as the products 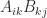 are all defined. In this case the matrices
are all defined. In this case the matrices  has as many block rows as
has as many block rows as 
 we can write
we can write
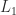 have the correct form for a unit lower triangular matrix and likewise the first row and column of
have the correct form for a unit lower triangular matrix and likewise the first row and column of  have the correct form for an upper triangular matrix. If we can find an LU factorization
have the correct form for an upper triangular matrix. If we can find an LU factorization 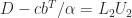 of the
of the  Schur complement
Schur complement  then
then  is an LU factorization of
is an LU factorization of 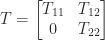
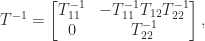
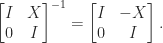
 is upper triangular then so are
is upper triangular then so are 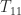 and
and 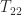 . By taking
. By taking  this formula can be used to construct a divide and conquer algorithm for computing
this formula can be used to construct a divide and conquer algorithm for computing 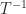 .
. , a fact that will be used in the next section.
, a fact that will be used in the next section.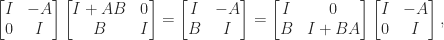
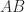 and
and 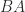 are defined. Taking determinants gives the formula
are defined. Taking determinants gives the formula  . In particular we can take
. In particular we can take 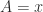 ,
, 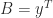 , for
, for  , giving
, giving  .
. ) then
) then
 involutory matrix. And if
involutory matrix. And if 
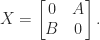

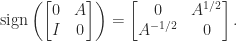
![\notag \mathrm{e}^X = \left[\begin{array}{cc} \cosh\sqrt{AB} & A (\sqrt{BA})^{-1} \sinh \sqrt{BA} \\[\smallskipamount] B(\sqrt{AB})^{-1} \sinh \sqrt{AB} & \cosh\sqrt{BA} \end{array}\right],](https://s0.wp.com/latex.php?latex=%5Cnotag+++%5Cmathrm%7Be%7D%5EX+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7D+++++++++++++++++++%5Ccosh%5Csqrt%7BAB%7D+%26+A+%28%5Csqrt%7BBA%7D%29%5E%7B-1%7D+%5Csinh+%5Csqrt%7BBA%7D++++++++++++++++++++++++%5C%5C%5B%5Csmallskipamount%5D+++++++++++++++++++++++B%28%5Csqrt%7BAB%7D%29%5E%7B-1%7D+%5Csinh+%5Csqrt%7BAB%7D+%26++++++++++++++++++++++%5Ccosh%5Csqrt%7BBA%7D++++++++++++++++++%5Cend%7Barray%7D%5Cright%5D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
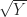 denotes any square root of
denotes any square root of 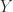 . With
. With  , this formula arises in the solution of the ordinary differential equation initial value problem
, this formula arises in the solution of the ordinary differential equation initial value problem  ,
,  ,
, 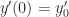 ,
, . The eigenvalues of
. The eigenvalues of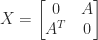
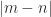 additional zeros if
additional zeros if  , and the eigenvectors of
, and the eigenvectors of 
 ),
), ),
), that is,
that is,  with eigenvector
with eigenvector 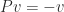 .
. eigenvalues
eigenvalues  for every such
for every such 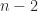 and determinant
and determinant  , a Householder matrix can be written as
, a Householder matrix can be written as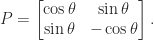
![v = e = [1,1,\dots,1]^T](https://s0.wp.com/latex.php?latex=v+%3D+e+%3D+%5B1%2C1%2C%5Cdots%2C1%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002) , for which
, for which  . For
. For 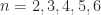 we obtain the matrices
we obtain the matrices![\notag \begin{gathered} \left[\begin{array}{@{\mskip2mu}rr@{\mskip2mu}} 0 & -1 \\ -1 & 0 \end{array}\right], \quad \displaystyle\frac{1}{3} \left[\begin{array}{@{\mskip2mu}rrr@{\mskip2mu}} 1 & -2 & -2\\ -2 & 1 & -2\\ -2 & -2 & 1\\ \end{array}\right], \quad \displaystyle\frac{1}{2} \left[\begin{array}{@{\mskip2mu}rrrr@{\mskip2mu}} 1 & -1 & -1 & -1\\ -1 & 1 & -1 & -1\\ -1 & -1 & 1 & -1\\ -1 & -1 & -1 & 1\\ \end{array}\right], \\ \displaystyle\frac{1}{5} \left[\begin{array}{@{\mskip2mu}rrrrr@{\mskip2mu}} 3 & -2 & -2 & -2 & -2\\ -2 & 3 & -2 & -2 & -2\\ -2 & -2 & 3 & -2 & -2\\ -2 & -2 & -2 & 3 & -2\\ -2 & -2 & -2 & -2 & 3 \end{array}\right], \quad \displaystyle\frac{1}{3} \left[\begin{array}{@{\mskip2mu}rrrrrr@{\mskip2mu}} 2 & -1 & -1 & -1 & -1 & -1\\ -1 & 2 & -1 & -1 & -1 & -1\\ -1 & -1 & 2 & -1 & -1 & -1\\ -1 & -1 & -1 & 2 & -1 & -1\\ -1 & -1 & -1 & -1 & 2 & -1\\ -1 & -1 & -1 & -1 & -1 & 2 \end{array}\right]. \end{gathered}](https://s0.wp.com/latex.php?latex=%5Cnotag++++%5Cbegin%7Bgathered%7D++++++++%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip2mu%7Drr%40%7B%5Cmskip2mu%7D%7D++++++++++++++++++++++0+%26+-1+%5C%5C+-1+%26+0++++++++%5Cend%7Barray%7D%5Cright%5D%2C+%5Cquad+++%5Cdisplaystyle%5Cfrac%7B1%7D%7B3%7D++++++++%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip2mu%7Drrr%40%7B%5Cmskip2mu%7D%7D+++++++++++++++++++++++1+%26++-2+%26++-2%5C%5C++++++++++++++++++++++-2+%26+++1+%26++-2%5C%5C++++++++++++++++++++++-2+%26++-2+%26+++1%5C%5C++++++++%5Cend%7Barray%7D%5Cright%5D%2C+%5Cquad++++%5Cdisplaystyle%5Cfrac%7B1%7D%7B2%7D++++++++%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip2mu%7Drrrr%40%7B%5Cmskip2mu%7D%7D++++++++++++++++++++++++1+%26+++-1+%26+++-1+%26+++-1%5C%5C+++++++++++++++++++++++-1+%26++++1+%26+++-1+%26+++-1%5C%5C+++++++++++++++++++++++-1+%26+++-1+%26++++1+%26+++-1%5C%5C+++++++++++++++++++++++-1+%26+++-1+%26+++-1+%26++++1%5C%5C++++++++%5Cend%7Barray%7D%5Cright%5D%2C+%5C%5C+++%5Cdisplaystyle%5Cfrac%7B1%7D%7B5%7D++++++++%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip2mu%7Drrrrr%40%7B%5Cmskip2mu%7D%7D++++3+%26+-2+%26+-2+%26+-2+%26+-2%5C%5C+-2+%26+3+%26+-2+%26+-2+%26++++-2%5C%5C+-2+%26+-2+%26+3+%26+-2+%26+-2%5C%5C+-2+%26+-2+%26+-2+%26+3+%26+-2%5C%5C+-2+%26+-2+%26+-2+%26+-2+%26+3+++%5Cend%7Barray%7D%5Cright%5D%2C+%5Cquad++%5Cdisplaystyle%5Cfrac%7B1%7D%7B3%7D+%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip2mu%7Drrrrrr%40%7B%5Cmskip2mu%7D%7D+++2+%26+-1+%26+-1+%26+-1+%26+-1+%26+-1%5C%5C+-1+%26+2+%26+-1+%26+-1+%26+-1+%26+-1%5C%5C+++-1+%26+-1+%26+2+%26+-1+%26+-1+%26+-1%5C%5C+-1+%26+-1+%26+-1+%26+2+%26+-1+%26+-1%5C%5C+-1+%26+-1+%26+-1+%26+-1+%26+2+%26+-1%5C%5C+++-1+%26+-1+%26+-1+%26+-1+%26+-1+%26+2+%5Cend%7Barray%7D%5Cright%5D.++++%5Cend%7Bgathered%7D+&bg=ffffff&fg=222222&s=0&c=20201002)
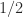 times a Hadamard matrix.
times a Hadamard matrix.
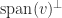 , as illustrated in the following diagram, which explains why
, as illustrated in the following diagram, which explains why  , where
, where  is orthogonal to
is orthogonal to  , so the component of
, so the component of  , the
, the  , which has
, which has 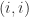 position. In this case premultiplying a vector by
position. In this case premultiplying a vector by 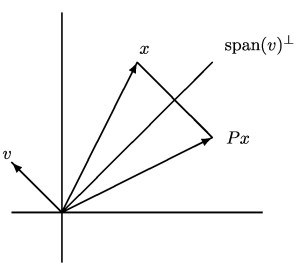
 . Since
. Since  , and we exclude the trivial case
, and we exclude the trivial case  . Now
. Now
 for some
for some  . Now with
. Now with 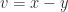 we have
we have
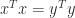 ,
,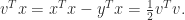

 ?
?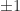 and one will be
and one will be  . This means that
. This means that 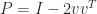 , where
, where  . It is natural to look for a square root of the form
. It is natural to look for a square root of the form  . Setting
. Setting  , and hence
, and hence  . As expected, these two square roots are complex even though
. As expected, these two square roots are complex even though  gives the following square root of the matrix above corresponding to
gives the following square root of the matrix above corresponding to  with
with 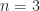 :
:![\notag X = \displaystyle\frac{1}{3} \left[\begin{array}{@{\mskip2mu}rrr} 2+\mathrm{i} & -1+\mathrm{i} & -1+\mathrm{i}\\ -1+\mathrm{i} & 2+\mathrm{i} & -1+\mathrm{i}\\ -1+\mathrm{i} & -1+\mathrm{i} & 2+\mathrm{i} \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cnotag+X+%3D+%5Cdisplaystyle%5Cfrac%7B1%7D%7B3%7D+%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip2mu%7Drrr%7D+2%2B%5Cmathrm%7Bi%7D+%26+-1%2B%5Cmathrm%7Bi%7D+%26+-1%2B%5Cmathrm%7Bi%7D%5C%5C+-1%2B%5Cmathrm%7Bi%7D+%26+2%2B%5Cmathrm%7Bi%7D+%26+-1%2B%5Cmathrm%7Bi%7D%5C%5C+-1%2B%5Cmathrm%7Bi%7D+%26+-1%2B%5Cmathrm%7Bi%7D+%26+2%2B%5Cmathrm%7Bi%7D+%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
 and
and  . Then from the construction above we know that
. Then from the construction above we know that 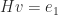 . Hence
. Hence
 and so
and so  gives
gives 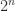 square roots on taking all possible combinations of signs on the diagonal for
square roots on taking all possible combinations of signs on the diagonal for  . Because
. Because 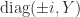 , where
, where  , where
, where 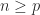 , as
, as
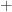 ” denotes the Moore–Penrose pseudoinverse. For
” denotes the Moore–Penrose pseudoinverse. For  ,
, 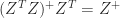 (this is most easily proved using the SVD), and so
(this is most easily proved using the SVD), and so
 is the orthogonal projector onto the range of
is the orthogonal projector onto the range of  (that is,
(that is, 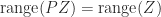 ,
,  , and
, and 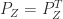 ). Hence, like a standard Householder matrix,
). Hence, like a standard Householder matrix, ![Z = \bigl[\begin{smallmatrix} 1 & 2 & 3 & 4\\ 5 & 6 & 7 & 8 \end{smallmatrix}\bigr]^T](https://s0.wp.com/latex.php?latex=Z+%3D+%5Cbigl%5B%5Cbegin%7Bsmallmatrix%7D+1+%26+2+%26+3+%26+4%5C%5C+5+%26+6+%26+7+%26+8+%5Cend%7Bsmallmatrix%7D%5Cbigr%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002) :
:![\notag \displaystyle\frac{1}{5} \left[\begin{array}{@{\mskip2mu}rrrr@{\mskip2mu}} -2 & -4 & -1 & 2\\ -4 & 2 & -2 & -1\\ -1 & -2 & 2 & -4\\ 2 & -1 & -4 & -2 \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cnotag+%5Cdisplaystyle%5Cfrac%7B1%7D%7B5%7D+%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmskip2mu%7Drrrr%40%7B%5Cmskip2mu%7D%7D+-2+%26+-4+%26+-1+%26+2%5C%5C+-4+%26+2+%26+-2+%26+-1%5C%5C+-1+%26+-2+%26+2+%26+-4%5C%5C+2+%26+-1+%26+-4+%26+-2+%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
 times and
times and  times, where
times, where  . Hence
. Hence 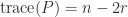 and
and  .
.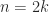 ,
,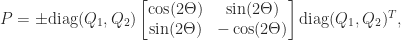
 and
and  are orthogonal and
are orthogonal and 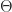 is symmetric positive definite. This formula neatly generalizes the formula for a standard Householder matrix for
is symmetric positive definite. This formula neatly generalizes the formula for a standard Householder matrix for 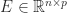 (
( ) one can construct a block Householder matrix
) one can construct a block Householder matrix  such that
such that
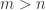 ,
,  ,
,  , and
, and
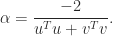
![[u^T~v^T]^T](https://s0.wp.com/latex.php?latex=%5Bu%5ET%7Ev%5ET%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002) .
. ) then a unitary matrix of the form
) then a unitary matrix of the form  (in their notation) can be constructed so that
(in their notation) can be constructed so that 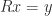 . They use this result to prove the existence of the Schur decomposition. The first systematic use of Householder matrices for computational purposes was by Householder (1958) who used them to construct the QR factorization.
. They use this result to prove the existence of the Schur decomposition. The first systematic use of Householder matrices for computational purposes was by Householder (1958) who used them to construct the QR factorization.

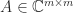 ,
, 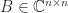 , and
, and 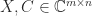 . It is named after James Joseph Sylvester (1814–1897), who considered the homogeneous version of the equation,
. It is named after James Joseph Sylvester (1814–1897), who considered the homogeneous version of the equation,  in 1884. Special cases of the equation are
in 1884. Special cases of the equation are  (matrix commutativity),
(matrix commutativity), 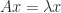 (an eigenvalue–eigenvector equation), and
(an eigenvalue–eigenvector equation), and 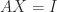 (matrix inversion).
(matrix inversion).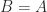 , taking the trace of both sides of the equation gives
, taking the trace of both sides of the equation gives
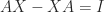 , for example, has no solution.
, for example, has no solution.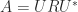 and
and  be Schur decompositions, where
be Schur decompositions, where  and
and  are upper triangular. Premultiplying the Sylvester equation by
are upper triangular. Premultiplying the Sylvester equation by  , postmultiplying by
, postmultiplying by  and
and  , we obtain
, we obtain

 are nonsingular for all
are nonsingular for all  ,
,  , …,
, …, 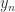 in turn. Hence the Sylvester equation has a unique solution if
in turn. Hence the Sylvester equation has a unique solution if 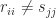 for all
for all 
 is the Kronecker product. Using the Schur transformations above it is easy to show that the eigenvalues of the coefficient matrix are given in terms of those of
is the Kronecker product. Using the Schur transformations above it is easy to show that the eigenvalues of the coefficient matrix are given in terms of those of 
 for all
for all  , it can be shown that if the eigenvalues of
, it can be shown that if the eigenvalues of  have negative real parts (that is,
have negative real parts (that is, 
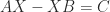 .
.
 then certain computations with
then certain computations with 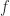 ,
,
 reduces to computing
reduces to computing  and
and 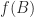 . Setting
. Setting
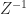 is just
is just 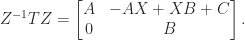
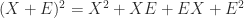 for square matrices
for square matrices 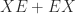 is the Fréchet derivative of the function
is the Fréchet derivative of the function  at
at 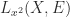 . Consequently, Newton’s method for the square root requires the solution of Sylvester equations, though in practice certain simplifications can be made to avoid their appearance. We can find the Fréchet derivative of
. Consequently, Newton’s method for the square root requires the solution of Sylvester equations, though in practice certain simplifications can be made to avoid their appearance. We can find the Fréchet derivative of  by applying the chain rule to
by applying the chain rule to  , which gives
, which gives  . Therefore
. Therefore  is the solution to the Sylvester equation
is the solution to the Sylvester equation 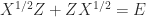 . Consequently, the Sylvester equation plays a role in the perturbation theory for matrix square roots.
. Consequently, the Sylvester equation plays a role in the perturbation theory for matrix square roots. for
for  , blockwise, by a recurrence.
, blockwise, by a recurrence. and LU factorization cannot exploit the Kronecker product structure, so this approach is prohibitively expensive unless
and LU factorization cannot exploit the Kronecker product structure, so this approach is prohibitively expensive unless 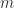 and
and 


 , where
, where  is a generalization of
is a generalization of  for
for 
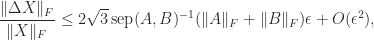
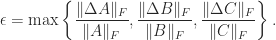
 , this inequality can be extremely weak for nonnormal matrices, so two matrices can have a small separation even if their eigenvalues are well separated. To illustrate, let
, this inequality can be extremely weak for nonnormal matrices, so two matrices can have a small separation even if their eigenvalues are well separated. To illustrate, let  denote the
denote the  for several values of
for several values of 
 apart, the separation is at the level of the unit roundoff for
apart, the separation is at the level of the unit roundoff for  .
. , the discrete Sylvester equation
, the discrete Sylvester equation 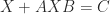 , and versions of all these for operators. It has also been generalized to multiple terms and to have coefficient matrices on both sides of
, and versions of all these for operators. It has also been generalized to multiple terms and to have coefficient matrices on both sides of 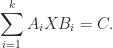
 and
and  this equation can be solved in
this equation can be solved in 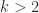 , no
, no  and
and  are large and sparse and, depending on the statistical properties of the random inputs,
are large and sparse and, depending on the statistical properties of the random inputs, 