
Jack Williams passed away on November 13th, 2015, at the age of 72.
Jack obtained his PhD from the University of Oxford Computing Laboratory in 1968 and spent two years as a Lecturer in Mathematics at the University of Western Australia in Perth. He was appointed Lecturer in Numerical Analysis at the University of Manchester in 1971.
He was a member of the Numerical Analysis Group (along with Christopher Baker, Ian Gladwell, Len Freeman, George Hall, Will McLewin, and Joan Walsh) that, together with numerical analysis colleagues at UMIST, took the subject forward at Manchester from the 1970s onwards.
Jack’s main research area was approximation theory, focusing particularly on Chebyshev approximation of real and complex functions. He also worked on stiff ordinary differential equations (ODEs). His early work on Chebyshev approximation in the complex plane by polynomials and rationals was particularly influential and is among his most-cited. Example contributions are
J. Williams (1972). Numerical Chebyshev approximation by interpolating rationals. Math. Comp., 26(117), 199–206.
S. Ellacott and J. Williams (1976). Rational Chebyshev approximation in the complex plane. SIAM J. Numer. Anal., 13(3), 310–323.
His later work on discrete Chebyshev approximation was of particular interest to me as it involved linear systems with Chebyshev-Vandermonde coefficient matrices, which I, and a number of other people, worked on a few years later:
M. Almacany, C. B. Dunham and J. Williams (1984). Discrete Chebyshev approximation by interpolating rationals. IMA J. Numer. Anal. 4, 467–477.
On the differential equations side, Jack wrote the opening chapter “Introduction to discrete variable methods” of the proceedings of a summer school organized jointly by the University of Liverpool and the University of Manchester in 1975 and published in G. Hall and J. M. Watt, eds, Modern Numerical Methods for Ordinary Differential Equations, Oxford University Press, 1976. This book’s timely account of the state of the art, covering stiff and nonstiff problems, boundary value problems, delay-differential equations, and integral equations, was very influential, as indicted by its 549 citations on Google Scholar. Jack contributed articles on ODEs and PDEs to three later Liverpool–Manchester volumes (1979, 1981, 1986).
Jack’s interests in approximation theory and differential equations were combined in his later work on parameter estimation in ODEs, where a theory of Chebyshev approximation applied to solutions of parameter-dependent ODEs was established, as exemplified by
J. Williams and Z. Kalogiratou (1993). Least squares and Chebyshev fitting for parameter estimation in ODEs. Adv. Comp. Math., 1(3), 357–366.
More details on Jack’s publications can be found at his MathSciNet author profile (subscription required). Some of his later unpublished technical reports from the 1990s can be accessed at from the list of Numerical Analysis Reports of the Manchester Centre for Computational Mathematics.
Jack spent a sabbatical year in the Department of Computer Science at the University of Toronto, 1976–1977, at the invitation of Professor Tom Hull. Over a number of years several visits between Manchester and Toronto were made in both directions by numerical analysts in the two departments.
It’s a fact of academic life that seminars can be boring and even impenetrable. Jack could always be relied on to ask insightful questions, whatever the topic, thereby improving the experience of everyone in the room.
Jack was an excellent lecturer, who taught at all levels from first year undergraduate through to Masters courses. He was confident, polished, and entertaining, and always took care to emphasize practicalities along with the theory. He had the charisma—and the loud voice!—to keep the attention of any audience, no matter how large it might be.
He studied Spanish at the Instituto Cervantes in Manchester, gaining an A-level in 1989 and a Diploma Basico de Espanol Como Lengua Extranjera from the Spanish Ministerio de Educación y Ciencia in 1992. He subsequently set up a four-year degree in Mathematics with Spanish, linking Manchester with Universidad Complutense de Madrid.
Jack was promoted to Senior Lecturer in 1996 and took early retirement in 2000. He continued teaching in the department right up until the end of the 2014/2015 academic year.
I benefited greatly from Jack’s advice and support both as a postgraduate student and when I began as a lecturer. My office was next to his, and from time to time I would hear strains of classical guitar, which he studied seriously and sometimes practiced during the day. For many years I shared pots of tea with him in the Senior Common Room at the refectory, where a group of mathematics colleagues met for lunchtime discussions.
Jack was gregarious, ever cheerful, and a good friend to many of his colleagues. He will be sadly missed.


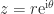 for complex numbers, where
for complex numbers, where  ,
, 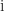 is the imaginary unit, and
is the imaginary unit, and ![\theta\in(-\pi,\pi]](https://s0.wp.com/latex.php?latex=%5Ctheta%5Cin%28-%5Cpi%2C%5Cpi%5D&bg=ffffff&fg=222222&s=0&c=20201002) . The generalization to an
. The generalization to an 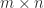 matrix is
matrix is 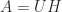 , where
, where  is
is  is
is  and Hermitian positive semidefinite. Here,
and Hermitian positive semidefinite. Here, 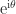 in the scalar case and
in the scalar case and  .
. has full rank. Since
has full rank. Since 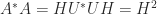 , we see that
, we see that 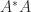 . Therefore we set
. Therefore we set  , after which
, after which 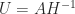 is forced. It just remains to check that this
is forced. It just remains to check that this 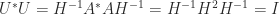 .
. , where
, where  is diagonal with the eigenvalues of
is diagonal with the eigenvalues of  is a unitary matrix of eigenvectors. Then
is a unitary matrix of eigenvectors. Then  is an SVD! My PhD student Pythagoras Papadimitriou and I
is an SVD! My PhD student Pythagoras Papadimitriou and I 
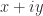 as
as  . Relph notes that the code fails when the real part is zero and that, because it adds
. Relph notes that the code fails when the real part is zero and that, because it adds 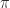 to the
to the 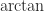 , the imaginary part is on the wrong range, which should be
, the imaginary part is on the wrong range, which should be ![(-\pi,\pi]](https://s0.wp.com/latex.php?latex=%28-%5Cpi%2C%5Cpi%5D&bg=ffffff&fg=222222&s=0&c=20201002) for the principal logarithm. Moreover, the original code incorrectly uses
for the principal logarithm. Moreover, the original code incorrectly uses 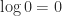 and has a missing minus sign in one statement.
and has a missing minus sign in one statement.