A vector norm measures the size, or length, of a vector. For complex 

with equality if and only if
(nonnegativity),
for all
(homogeneity),
for all
(the triangle inequality).

An important class of norms is the Hölder 
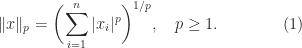
The 


Other important special cases are

A useful concept is that of the dual norm associated with a given vector norm, which is defined by

The maximum is attained because the definition is equivalent to 

We can rewrite the definition of dual norm, using the homogeneity of vector norms, as
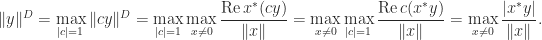
Hence we have the attainable inequality
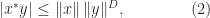
which is the generalized Hölder inequality.
The dual of the 
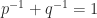

An important special case is the Cauchy–Schwarz inequality,

The notation 

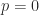



In numerical linear algebra, vector norms play a crucial role in the definition of a subordinate matrix norm, as we will explain in the next post in this series.
All norms on 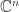
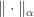
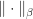
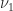
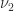
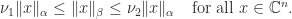
For example, it is easy to see that
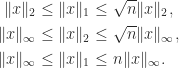
The 2-norm is invariant under unitary transformations: if 

Care must be taken to avoid overflow and (damaging) underflow when evaluating a vector 



References
This is a minimal set of references, which contain further useful references within.
- Takeyuki Harayama, Shuhei Kudo, Daichi Mukunoki, Toshiyuki Imamura, and Daisuke Takahashi, A Rapid Euclidean Norm Calculation Algorithm that Reduces Overflow and Underflow, in Computational Science and Its Applications–ICCSA 2021, O. Gervasi et al., eds, 95–110, Springer, 2021.
- Nicholas J. Higham, Accuracy and Stability of Numerical Algorithms, second edition, Society for Industrial and Applied Mathematics,
- Roger A. Horn and Charles R. Johnson, Matrix Analysis, second edition, Cambridge University Press, 2013. My review of the second edition.
Note: This article was revised on October 12, 2021 to change the definition of dual norm to use 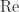
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.

 , and future exascale computer systems will be able to tackle even larger problems. Rounding error analysis shows that the computed solution satisfies a componentwise backward error bound that, under favorable assumptions, is of order
, and future exascale computer systems will be able to tackle even larger problems. Rounding error analysis shows that the computed solution satisfies a componentwise backward error bound that, under favorable assumptions, is of order 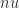 , where
, where  is the unit roundoff of the floating-point arithmetic:
is the unit roundoff of the floating-point arithmetic:  for double precision and
for double precision and 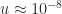 for single precision. This backward error bound cannot guarantee any stability for single precision solution of today’s largest problems and suggests a loss of half the digits in the backward error for double precision.
for single precision. This backward error bound cannot guarantee any stability for single precision solution of today’s largest problems and suggests a loss of half the digits in the backward error for double precision. for
for  for both half precision formats, suggesting a potentially complete loss of numerical stability. Yet inner products with
for both half precision formats, suggesting a potentially complete loss of numerical stability. Yet inner products with  of two
of two  can computed as
can computed as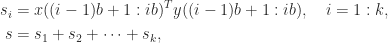
 and
and 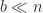 is the block size. The inner product has been broken into
is the block size. The inner product has been broken into  , which are computed independently then summed. Many linear algebra algorithms are blocked in an analogous way, where the blocking is into submatrices with
, which are computed independently then summed. Many linear algebra algorithms are blocked in an analogous way, where the blocking is into submatrices with  or
or  , so blocking brings a substantial reduction in the error bounds.
, so blocking brings a substantial reduction in the error bounds.
 . By computing the sum
. By computing the sum  with a more accurate summation method the error constant is further reduced to
with a more accurate summation method the error constant is further reduced to 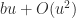 (this is the FABsum method of Blanchard et al. (2020)).
(this is the FABsum method of Blanchard et al. (2020)).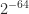 rather than
rather than  for double precision, giving error bounds smaller by a factor up to
for double precision, giving error bounds smaller by a factor up to  .
.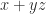 with one rounding error instead of two. This results in a reduction in error bounds by a factor
with one rounding error instead of two. This results in a reduction in error bounds by a factor  , with matrices
, with matrices  of fixed size, are available on Google tensor processing units, NVIDIA GPUs, and in the ARMv8-A architecture. For half precision inputs these devices can produce results of single precision quality, which can give a significant boost in accuracy when block FMAs are chained together to form a matrix product of arbitrary dimension.
of fixed size, are available on Google tensor processing units, NVIDIA GPUs, and in the ARMv8-A architecture. For half precision inputs these devices can produce results of single precision quality, which can give a significant boost in accuracy when block FMAs are chained together to form a matrix product of arbitrary dimension.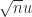 when a corresponding worst-case bound is proportional to
when a corresponding worst-case bound is proportional to  , which is a significant reduction. Block FMAs and extended precision registers provide further reductions.
, which is a significant reduction. Block FMAs and extended precision registers provide further reductions. solved in single precision with a block size of
solved in single precision with a block size of  versus
versus 