The trace of an 
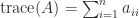
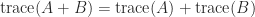
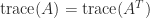
A key fact is that the trace is also the sum of the eigenvalues. The proof is by considering the characteristic polynomial 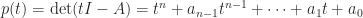

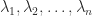

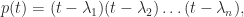
and so 
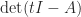
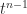
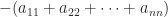
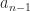
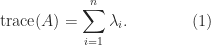
A consequence of (1) is that any transformation that preserves the eigenvalues preserves the trace. Therefore the trace is unchanged under similarity transformations: 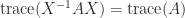

An an example of how the trace can be useful, suppose 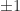



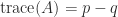
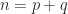
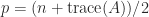
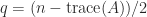
Another important property is that for an 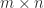
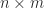

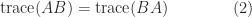
(despite the fact that 
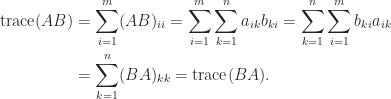
This simple fact can have non-obvious consequences. For example, consider the equation 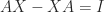
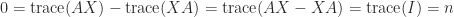
The relation (2) gives 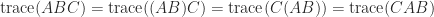

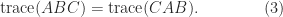
So we can cyclically permute terms in a matrix product without changing the trace.
As an example of the use of (2) and (3), if 


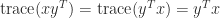
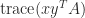
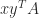
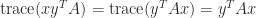
The trace is useful in calculations with the Frobenius norm of an
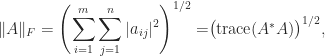
where 
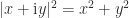
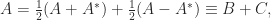
where 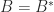

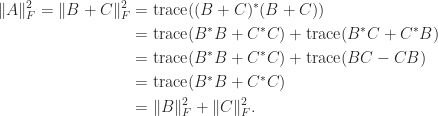
If a matrix is not explicitly known but we can compute matrix–vector products with it then the trace can be estimated by
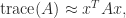
where the vector 
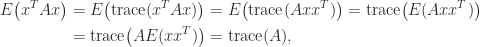
since 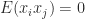
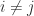
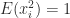

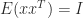
References
- Haim Avron and Sivan Toledo, Randomized Algorithms for Estimating the Trace of an Implicit Symmetric Positive Semi-definite Matrix, J. ACM 58, 8:1-8:34, 2011.
Related Blog Posts
- What Is a Matrix Norm? (2021)
- What Is an Eigenvalue? (2022)
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.

In the definition of the Frobenius norm, I think you want the second summation to be on j.
Fixed – thanks,
In the last part, does x have to drawn from specifically the normal distribution? Seems to me as long as the components are independent with mean 0 and variance 1 it works the same.
Yes, x doesn’t have to be from the normal distribution.
Hi, shouldn’t the second term in the last series of equations (the one after the words “The expectation of this estimate is”) be removed?
It’s important to note that $x^TAx$ is a scalar. If the second term is removed this hides a key step and will puzzle some readers.