A stochastic matrix is an  matrix with nonnegative entries and unit row sums. If
matrix with nonnegative entries and unit row sums. If  is stochastic then
is stochastic then  , where
, where ![e = [1,1,\dots,1]^T](https://s0.wp.com/latex.php?latex=e+%3D+%5B1%2C1%2C%5Cdots%2C1%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002) is the vector of ones. This means that
is the vector of ones. This means that  is an eigenvector of
is an eigenvector of  corresponding to the eigenvalue
corresponding to the eigenvalue  .
.
The identity matrix is stochastic, as is any permutation matrix. Here are some other examples of stochastic matrices:
![\notag \begin{aligned} A_n &= n^{-1}ee^T, \quad \textrm{in particular}~~ A_3 = \begin{bmatrix} \frac{1}{3} & \frac{1}{3} & \frac{1}{3}\\[3pt] \frac{1}{3} & \frac{1}{3} & \frac{1}{3}\\[3pt] \frac{1}{3} & \frac{1}{3} & \frac{1}{3} \end{bmatrix}, \qquad (1)\\ B_n &= \frac{1}{n-1}(ee^T -I), \quad \textrm{in particular}~~ B_3 = \begin{bmatrix} 0 & \frac{1}{2} & \frac{1}{2}\\[2pt] \frac{1}{2} & 0 & \frac{1}{2}\\[2pt] \frac{1}{2} & \frac{1}{2} & 0 \end{bmatrix}, \qquad (2)\\ C_n &= \begin{bmatrix} 1 & & & \\ \frac{1}{2} & \frac{1}{2} & & \\ \vdots & \vdots &\ddots & \\ \frac{1}{n} & \frac{1}{n} &\cdots & \frac{1}{n} \end{bmatrix}. \qquad (3)\\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cnotag+%5Cbegin%7Baligned%7D+++A_n+%26%3D+n%5E%7B-1%7Dee%5ET%2C+%5Cquad+%5Ctextrm%7Bin+particular%7D%7E%7E+++++A_3+%3D+%5Cbegin%7Bbmatrix%7D++++%5Cfrac%7B1%7D%7B3%7D+%26+%5Cfrac%7B1%7D%7B3%7D+%26+%5Cfrac%7B1%7D%7B3%7D%5C%5C%5B3pt%5D++++%5Cfrac%7B1%7D%7B3%7D+%26+%5Cfrac%7B1%7D%7B3%7D+%26+%5Cfrac%7B1%7D%7B3%7D%5C%5C%5B3pt%5D++++%5Cfrac%7B1%7D%7B3%7D+%26+%5Cfrac%7B1%7D%7B3%7D+%26+%5Cfrac%7B1%7D%7B3%7D++++%5Cend%7Bbmatrix%7D%2C+%5Cqquad+%281%29%5C%5C+++B_n+%26%3D+%5Cfrac%7B1%7D%7Bn-1%7D%28ee%5ET+-I%29%2C+%5Cquad+%5Ctextrm%7Bin+particular%7D%7E%7E+++++B_3+%3D+%5Cbegin%7Bbmatrix%7D++++++++++++++0+%26+%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B1%7D%7B2%7D%5C%5C%5B2pt%5D++++%5Cfrac%7B1%7D%7B2%7D+%26+0+++++++++++%26+%5Cfrac%7B1%7D%7B2%7D%5C%5C%5B2pt%5D++++%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B1%7D%7B2%7D+%26+0++++%5Cend%7Bbmatrix%7D%2C++++%5Cqquad+%282%29%5C%5C+++C_n+%26%3D+%5Cbegin%7Bbmatrix%7D+++++++++++++1+++++++++%26+++++++++++++++++++%26+++++++++++%26++++%5C%5C++++++%5Cfrac%7B1%7D%7B2%7D++++++%26++%5Cfrac%7B1%7D%7B2%7D++++++%26+++++++++++%26++++%5C%5C++++++%5Cvdots+++++++++++%26++%5Cvdots+++++++++++%26%5Cddots+++++%26++++%5C%5C++++++%5Cfrac%7B1%7D%7Bn%7D++++++%26++%5Cfrac%7B1%7D%7Bn%7D++++++%26%5Ccdots+++++%26++%5Cfrac%7B1%7D%7Bn%7D++++++%5Cend%7Bbmatrix%7D.+++%5Cqquad+%283%29%5C%5C+%5Cend%7Baligned%7D+&bg=ffffff&fg=222222&s=0&c=20201002)
For any matrix , the spectral radius  is bounded by
is bounded by 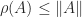 for any norm. For a stochastic matrix, taking the
for any norm. For a stochastic matrix, taking the  -norm (the maximum row sum of absolute values) gives
-norm (the maximum row sum of absolute values) gives 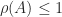 , so since we know that is an eigenvalue,
, so since we know that is an eigenvalue, 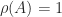 . It can be shown that is a semisimple eigenvalue, that is, if there are
. It can be shown that is a semisimple eigenvalue, that is, if there are  eigenvalues equal to then there are linearly independent eigenvectors corresponding to (Meyer, 2000, p. 696).
eigenvalues equal to then there are linearly independent eigenvectors corresponding to (Meyer, 2000, p. 696).
A lower bound on the spectral radius can be obtained from Gershgorin’s theorem. The  th Gershgorin disc is defined by
th Gershgorin disc is defined by 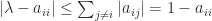 , which implies
, which implies  . Every eigenvalue
. Every eigenvalue 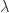 lies in the union of the
lies in the union of the  discs and so must satisfy
discs and so must satisfy
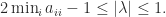
The lower bound is positive if is strictly diagonally dominant by rows.
If and  are stochastic then
are stochastic then 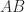 is nonnegative and
is nonnegative and  , so is stochastic. In particular, any positive integer power of is stochastic. Does
, so is stochastic. In particular, any positive integer power of is stochastic. Does 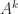 converge as
converge as 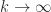 ? The answer is that it does, and the limit is stochastic, as long as is the only eigenvalue of modulus , and this will be the case if all the elements of are positive (by Perron’s theorem). The simplest example of non-convergence is the stochastic matrix
? The answer is that it does, and the limit is stochastic, as long as is the only eigenvalue of modulus , and this will be the case if all the elements of are positive (by Perron’s theorem). The simplest example of non-convergence is the stochastic matrix
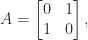
which has eigenvalues and  . Since
. Since  , all even powers are equal to
, all even powers are equal to  and all odd powers are equal to . For the matrix (1),
and all odd powers are equal to . For the matrix (1), 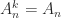 for all , while for (2),
for all , while for (2), 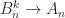 as . For (3),
as . For (3), 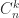 converges to the matrix with in every entry of the first column and zeros everywhere else.
converges to the matrix with in every entry of the first column and zeros everywhere else.
Stochastic matrices arise in Markov chains. A transition matrix for a finite homogeneous Markov chain is a matrix whose  element is the probability of moving from state to state
element is the probability of moving from state to state  over a time step. It has nonnegative entries and the rows sum to , so it is a stochastic matrix. In applications including finance and healthcare, a transition matrix may be estimated for a certain time period, say one year, but a transition matrix for a shorter period, say one month, may be needed. If is a transition matrix for a time period
over a time step. It has nonnegative entries and the rows sum to , so it is a stochastic matrix. In applications including finance and healthcare, a transition matrix may be estimated for a certain time period, say one year, but a transition matrix for a shorter period, say one month, may be needed. If is a transition matrix for a time period  then a stochastic th root of , which is a stochastic solution
then a stochastic th root of , which is a stochastic solution  of the equation
of the equation  , is a transition matrix for a time period a factor smaller. Therefore
, is a transition matrix for a time period a factor smaller. Therefore 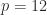 (years to months) and
(years to months) and 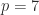 (weeks to days) are among the values of interest. Unfortunately, a stochastic th root may not exist. For example, the matrix
(weeks to days) are among the values of interest. Unfortunately, a stochastic th root may not exist. For example, the matrix
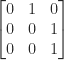
has no th roots at all, let alone stochastic ones. Yet many stochastic matrices do have stochastic roots. The matrix (3) has a stochastic th root for all , as shown by Higham and Lin (2011), who give a detailed analysis of th roots of stochastic matrices. For example, to four decimal places,

A stochastic matrix is sometime called a row-stochastic matrix to distinguish it from a column-stochastic matrix, which is a nonnegative matrix for which 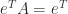 (so that
(so that 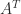 is row-stochastic). A matrix that is both row-stochastic and column-stochastic is called doubly stochastic. A permutation matrix is an example of a doubly stochastic matrix. If
is row-stochastic). A matrix that is both row-stochastic and column-stochastic is called doubly stochastic. A permutation matrix is an example of a doubly stochastic matrix. If  is a unitary matrix then the matrix with
is a unitary matrix then the matrix with  is doubly stochastic. A magic square scaled by the magic sum is also doubly stochastic. For example,
is doubly stochastic. A magic square scaled by the magic sum is also doubly stochastic. For example,
>> M = magic(4), A = M/sum(M(1,:)) % A is doubly stochastic.
M =
16 2 3 13
5 11 10 8
9 7 6 12
4 14 15 1
A =
4.7059e-01 5.8824e-02 8.8235e-02 3.8235e-01
1.4706e-01 3.2353e-01 2.9412e-01 2.3529e-01
2.6471e-01 2.0588e-01 1.7647e-01 3.5294e-01
1.1765e-01 4.1176e-01 4.4118e-01 2.9412e-02
>> [sum(A) sum(A')]
ans =
1 1 1 1 1 1 1 1
>> eig(A)'
ans =
1.0000e+00 2.6307e-01 -2.6307e-01 8.5146e-18
References
- Nicholas J. Higham and Lijing Lin, On th Roots of Stochastic Matrices, Linear Algebra Appl. 435, 448–463, 2011.
- Carl D. Meyer, Matrix Analysis and Applied Linear Algebra, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2000.

 , where
, where  is the number of positive eigenvalues of
is the number of positive eigenvalues of  is the number of negative eigenvalues of
is the number of negative eigenvalues of  is the number of zero eigenvalues of
is the number of zero eigenvalues of  . The difference
. The difference  is called the signature.
is called the signature. and
and  . But in general the diagonal elements do not tell us much about the inertia. For example, here is a matrix that has positive diagonal elements but only one positive eigenvalue (and this example works for any
. But in general the diagonal elements do not tell us much about the inertia. For example, here is a matrix that has positive diagonal elements but only one positive eigenvalue (and this example works for any 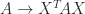 for a nonsingular matrix
for a nonsingular matrix 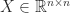 is nonsingular then
is nonsingular then  .
. does the job, where
does the job, where  is a permutation matrix,
is a permutation matrix,  is unit lower triangular, and
is unit lower triangular, and  is diagonal Then
is diagonal Then 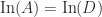 , and
, and  can be read off the diagonal of
can be read off the diagonal of  factorization, in which
factorization, in which  , always exists, and its computation is numerically stable with a suitable pivoting strategy such as symmetric rook pivoting.
, always exists, and its computation is numerically stable with a suitable pivoting strategy such as symmetric rook pivoting. .
. and
and 
 .
.