In many applications a matrix 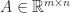
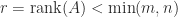

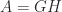
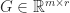

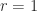


What is usually wanted is a factorization that displays how close

where 
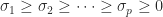

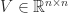
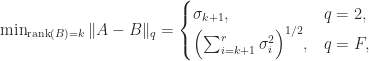
and that the minimum is attained at

so 


Although the SVD is expensive to compute, it may not be significantly more expensive than alternative factorizations. However, the SVD is expensive to update when a row or column is added to or removed from the matrix, as happens repeatedly in signal processing applications.
Many different definitions of a rank-revealing factorization have been given, and they usually depend on a particular matrix factorization. We will use the following general definition.
Definition 1. A rank-revealing factorization (RRF) of

where
,
is diagonal and nonsingular, and
and
are well conditioned.
An RRF concentrates the rank deficiency and ill condition of

where 
Without loss of generality we can assume that

(since 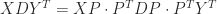



so 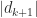

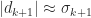
Definition 2 is a strong requirement, since it requires all the singular values of
Numerical Rank
An RRF helps to determine the numerical rank, which we now define.
Definition 2. For a given
the numerical rank of
.
By the Eckart–Young theorem, the numerical rank is the smallest rank attained over all 
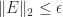



QR Factorization
One might attempt to compute an RRF by using a QR factorization 
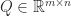
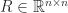
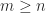

However, it is easy to see that QR factorization in its basic form is flawed as a means for computing an RRF. Consider the matrix
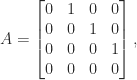
which is a Jordan block with zero eigenvalue. This matrix is its own QR factorization (
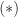
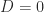




![[a_1,a_2,a_3,a_4]](https://s0.wp.com/latex.php?latex=%5Ba_1%2Ca_2%2Ca_3%2Ca_4%5D&bg=ffffff&fg=222222&s=0&c=20201002)
![[a_2,a_3,a_4,a_1]](https://s0.wp.com/latex.php?latex=%5Ba_2%2Ca_3%2Ca_4%2Ca_1%5D&bg=ffffff&fg=222222&s=0&c=20201002)

For a less trivial example, consider the matrix
![\notag A = \left[\begin{array}{rrrr} 1 & 1 &\theta &0\\ 1 & -1 & 2 &1 \\ 1 & 0 &1+\theta &-1\\ 1 &-1 & 2 &-1 \end{array}\right], \quad \theta = 10^{-8}. \qquad (\dagger)](https://s0.wp.com/latex.php?latex=%5Cnotag+++A+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Brrrr%7D++++++++1+%26+1++%26%5Ctheta+%260%5C%5C++++++++1+%26+-1+%26+2+%261+%5C%5C++++++++1+%26+0++%261%2B%5Ctheta+%26-1%5C%5C++++++++1+%26-1++%26+2+%26-1+++%5Cend%7Barray%7D%5Cright%5D%2C+%5Cquad+%5Ctheta+%3D+10%5E%7B-8%7D.+%5Cqquad+%28%5Cdagger%29+&bg=ffffff&fg=222222&s=0&c=20201002)
Computing the QR factorization we obtain
R =
-2.0000e+00 5.0000e-01 -2.5000e+00 5.0000e-01
0 1.6583e+00 -1.6583e+00 -1.5076e-01
0 0 -4.2640e-09 8.5280e-01
0 0 0 -1.4142e+00
The 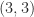
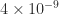
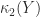
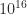
QR Factorization With Column Pivoting
A common method for computing an RRF is QR factorization with column pivoting, which for a matrix 

In particular,

If 
![\notag R = \begin{array}[b]{@{\mskip33mu}c@{\mskip-16mu}c@{\mskip-10mu}c@{}} \scriptstyle k & \scriptstyle n-k & \\ \multicolumn{2}{c}{ \left[\begin{array}{c@{~}c@{~}} R_{11}& R_{12} \\ 0 & R_{22} \\ \end{array}\right]} & \mskip-12mu\ \begin{array}{c} \scriptstyle k \\ \scriptstyle n-k \end{array} \end{array}, \qquad(4)](https://s0.wp.com/latex.php?latex=%5Cnotag++++R+%3D++++%5Cbegin%7Barray%7D%5Bb%5D%7B%40%7B%5Cmskip33mu%7Dc%40%7B%5Cmskip-16mu%7Dc%40%7B%5Cmskip-10mu%7Dc%40%7B%7D%7D++++%5Cscriptstyle+k+%26++++%5Cscriptstyle+n-k+%26++++%5C%5C++++%5Cmulticolumn%7B2%7D%7Bc%7D%7B++++++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%40%7B%7E%7Dc%40%7B%7E%7D%7D++++++++++++++++++R_%7B11%7D%26+R_%7B12%7D+%5C%5C++++++++++++++++++++0+++%26+R_%7B22%7D+%5C%5C++++++++++++++%5Cend%7Barray%7D%5Cright%5D%7D++++%26+%5Cmskip-12mu%5C++++++++++%5Cbegin%7Barray%7D%7Bc%7D++++++++++++++%5Cscriptstyle+k+%5C%5C++++++++++++++%5Cscriptstyle+n-k++++++++++++++%5Cend%7Barray%7D++++%5Cend%7Barray%7D%2C++%5Cqquad%284%29+&bg=ffffff&fg=222222&s=0&c=20201002)
with
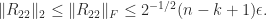
Hence 
![\left[\begin{smallmatrix} R_{11} & R_{12} \\ 0 & 0 \end{smallmatrix}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Bsmallmatrix%7D+R_%7B11%7D+%26+R_%7B12%7D+%5C%5C+0+%26+0+%5Cend%7Bsmallmatrix%7D%5Cright%5D&bg=ffffff&fg=222222&s=0&c=20201002)
![Q = [Q_1~Q_2]](https://s0.wp.com/latex.php?latex=Q+%3D+%5BQ_1%7EQ_2%5D&bg=ffffff&fg=222222&s=0&c=20201002)

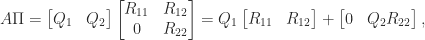
so ![\| A\Pi - Q_1 [R_{11}~R_{12}]\|_2 \le \|R_{22}\|_2](https://s0.wp.com/latex.php?latex=%5C%7C+A%5CPi+-+Q_1+%5BR_%7B11%7D%7ER_%7B12%7D%5D%5C%7C_2+%5Cle+%5C%7CR_%7B22%7D%5C%7C_2&bg=ffffff&fg=222222&s=0&c=20201002)

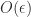
To assess how good an RRF this factorization is (with 

Applying (1) gives

where 


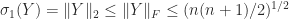


The lower bound is an approximate equality for small 
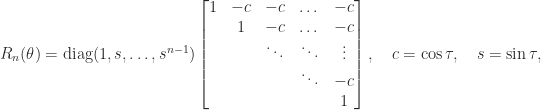
devised by Kahan, which is invariant under QR factorization with column pivoting. Therefore QR factorization with column pivoting is not guaranteed to reveal the rank, and indeed it can fail to do so by an exponentially large factor.
For the matrix 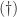
![A\Pi = [a_3,~a_4,~a_2,~a_1]](https://s0.wp.com/latex.php?latex=A%5CPi+%3D+%5Ba_3%2C%7Ea_4%2C%7Ea_2%2C%7Ea_1%5D&bg=ffffff&fg=222222&s=0&c=20201002)
R =
-3.0000e+00 3.3333e-01 1.3333e+00 -1.6667e+00
0 -1.6997e+00 2.6149e-01 2.6149e-01
0 0 1.0742e+00 1.0742e+00
0 0 0 3.6515e-09
This 



QR Factorization with Other Pivoting Choices
Consider a 
![\notag R = \begin{array}[b]{@{\mskip33mu}c@{\mskip-16mu}c@{\mskip-10mu}c@{}} \scriptstyle k & \scriptstyle n-k & \\ \multicolumn{2}{c}{ \left[\begin{array}{c@{~}c@{~}} R_{11}& R_{12} \\ 0 & R_{22} \\ \end{array}\right]} & \mskip-12mu\ \begin{array}{c} \scriptstyle k \\ \scriptstyle n-k \end{array} \end{array}. \qquad (6)](https://s0.wp.com/latex.php?latex=%5Cnotag++++R+%3D++++%5Cbegin%7Barray%7D%5Bb%5D%7B%40%7B%5Cmskip33mu%7Dc%40%7B%5Cmskip-16mu%7Dc%40%7B%5Cmskip-10mu%7Dc%40%7B%7D%7D++++%5Cscriptstyle+k+%26++++%5Cscriptstyle+n-k+%26++++%5C%5C++++%5Cmulticolumn%7B2%7D%7Bc%7D%7B++++++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%40%7B%7E%7Dc%40%7B%7E%7D%7D++++++++++++++++++R_%7B11%7D%26+R_%7B12%7D+%5C%5C++++++++++++++++++++0+++%26+R_%7B22%7D+%5C%5C++++++++++++++%5Cend%7Barray%7D%5Cright%5D%7D++++%26+%5Cmskip-12mu%5C++++++++++%5Cbegin%7Barray%7D%7Bc%7D++++++++++++++%5Cscriptstyle+k+%5C%5C++++++++++++++%5Cscriptstyle+n-k++++++++++++++%5Cend%7Barray%7D++++%5Cend%7Barray%7D.+%5Cqquad+%286%29+&bg=ffffff&fg=222222&s=0&c=20201002)
We have

where (7) is from singular value interlacing inequalities and (8) follows from the Eckart-Young theorem, since setting 


In view of the inequalities (7) and (8) this means that we wish to choose 

Some theoretical results are available on the existence of such QR factorizations. First, we give a result that shows that for 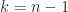

Theorem 1. For
and
, where
.
Proof. Let
, with
and let
be such that
satisfies
. Then if
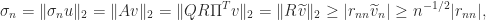
since
, which yields the result.
Next, we write
, where
, and partition

with
. Then
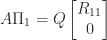
implies
. On the other hand, if
is an SVD with
,
, and
then

so

Finally, we note that we can partition the orthogonal matrix
as
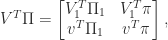
and the CS decomposition implies that

Hence
, as required.

Theorem 1 is a special case of the next result of Hong and Pan (1992).
Theorem 2. For

where
.
The proof of Theorem 2 is constructive and chooses 

Theorem 2 shows the existence of an RRF up to the factor 
Much work has been done on algorithms that choose the permutation matrix 
UTV Decomposition
By applying Householder transformations on the right, a QR factorization with column pivoting can be turned into a complete orthogonal decomposition of
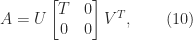
where 


The UTV decomposition is easy to update (when a row is added) and downdate (when a row is removed) using Givens rotations and it is suitable for parallel implementation. Initial determination of the UTV decomposition can be done by applying the updating algorithm as the rows are brought in one at a time.
LU Factorization
Instead of QR factorization we can build an RRF from an LU factorization with pivoting. For

where 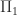



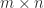

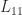

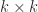




A result of Pan (2000) shows that an RRF based on LU factorization always exists up to a modest factor 
Theorem 3 For
![\notag \Pi_1 A \Pi_2 = LU = \begin{bmatrix} L_{11} & 0 \\ L_{12} & I_{m-k,n-k} \end{bmatrix} \begin{array}[b]{@{\mskip33mu}c@{\mskip-16mu}c@{\mskip-10mu}c@{}} \scriptstyle k & \scriptstyle n-k & \\ \multicolumn{2}{c}{ \left[\begin{array}{c@{~}c@{~}} U_{11}& U_{12} \\ 0 & U_{22} \\ \end{array}\right]} & \mskip-12mu\ \begin{array}{c} \scriptstyle k \\ \scriptstyle n-k \end{array} \end{array},](https://s0.wp.com/latex.php?latex=%5Cnotag+++++%5CPi_1+A+%5CPi_2+%3D+LU+%3D+++++%5Cbegin%7Bbmatrix%7D+++++L_%7B11%7D+%26++0++++%5C%5C+++++L_%7B12%7D+%26+I_%7Bm-k%2Cn-k%7D+++++%5Cend%7Bbmatrix%7D++++%5Cbegin%7Barray%7D%5Bb%5D%7B%40%7B%5Cmskip33mu%7Dc%40%7B%5Cmskip-16mu%7Dc%40%7B%5Cmskip-10mu%7Dc%40%7B%7D%7D++++%5Cscriptstyle+k+%26++++%5Cscriptstyle+n-k+%26++++%5C%5C++++%5Cmulticolumn%7B2%7D%7Bc%7D%7B++++++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%40%7B%7E%7Dc%40%7B%7E%7D%7D++++++++++++++++++U_%7B11%7D%26+U_%7B12%7D+%5C%5C++++++++++++++++++++0+++%26+U_%7B22%7D+%5C%5C++++++++++++++%5Cend%7Barray%7D%5Cright%5D%7D++++%26+%5Cmskip-12mu%5C++++++++++%5Cbegin%7Barray%7D%7Bc%7D++++++++++++++%5Cscriptstyle+k+%5C%5C++++++++++++++%5Cscriptstyle+n-k++++++++++++++%5Cend%7Barray%7D++++%5Cend%7Barray%7D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
where
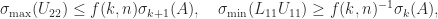
where
.
Again the proof is constructive, but the permutations it chooses are too expensive to compute. In practice, complete pivoting often yields a good RRF.
In terms of Definition 1, an RRF has
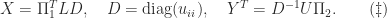
For the matrix (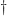
U =
1.0000e+00 1.0000e+00 1.0000e-08 0
0 -2.0000e+00 2.0000e+00 1.0000e+00
0 0 5.0000e-09 -1.5000e+00
0 0 0 -2.0000e+00
As for QR factorization without pivoting, an RRF is not obtained from 
U =
2.0000e+00 1.0000e+00 -1.0000e+00 1.0000e+00
0 -2.0000e+00 0 0
0 0 1.0000e+00 1.0000e+00
0 0 0 -5.0000e-09
which yields a very good RRF 
Notes
QR factorization with column pivoting is difficult to implement efficiently, as the criterion for choosing the pivots requires the norms of the active parts of the remaining columns and this requires a significant amount of data movement. In recent years, randomized RRF algorithms have been developed that use projections with random matrices to make pivot decisions based on small sample matrices and thereby reduce the amount of data movement. See, for example, Martinsson et al. (2019).
References
This is a minimal set of references, which contain further useful references within.
- Shivkumar Chandrasekaran and Ilse C. F. Ipsen, On Rank-Revealing Factorisations, SIAM J. Matrix Anal. Appl. 15 (2), 592–622, 1994
- Y. P. Hong and C.-T. Pan, Rank-Revealing QR Factorizations and the Singular Value Decomposition, Math. Comp. 58 (197), 213–232, 1992.
- P. G. Martinsson, G. Quintana-Orti, and N. Heavner, randUTV: A Blocked Randomized Algorithm for Computing a Rank-Revealing UTV Factorization, ACM Trans. Math. Software 45(1), 4:1–4:26, 2019.
- C.-T. Pan, On the Existence and Computation of Rank-Revealing LU Factorizations, Linear Algebra Appl. 316, 199–222, 2000.
- G. W. Stewart, Matrix Algorithms. Volume I: Basic Decompositions, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 1998.
Related Blog Posts
- What Is the CS Decomposition? (2020)
- What Is an LU Factorization? (2021)
- What Is a QR Factorization? (2020)
- What Is the Singular Value Decomposition? (2020)
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
 math mode
math mode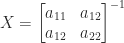


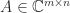 is a factorization
is a factorization 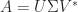 , where
, where 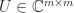 and
and 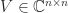 are unitary and
are unitary and 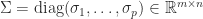 , with
, with 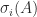 to specify the matrix to which the singular value belongs.
to specify the matrix to which the singular value belongs.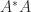 or
or 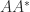 , whose eigenvalues are the squares of the singular values of
, whose eigenvalues are the squares of the singular values of 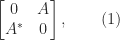
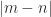 zero eigenvalues if
zero eigenvalues if 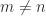 .
.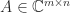 ,
,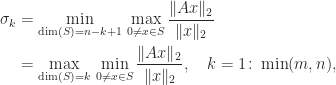
 .
.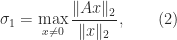

 (the equality case in the Cauchy–Schwarz inequality). For example, (2) is equivalent to
(the equality case in the Cauchy–Schwarz inequality). For example, (2) is equivalent to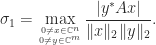
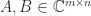 ,
,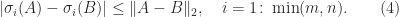
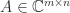 and nonsingular
and nonsingular 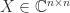 and
and  ,
,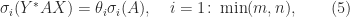
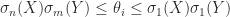 .
.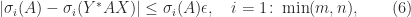
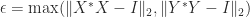 . The bounds (5) and (6) are intuitively reasonable, because unitary transformations preserve singular values and the bounds quantify in different ways how close
. The bounds (5) and (6) are intuitively reasonable, because unitary transformations preserve singular values and the bounds quantify in different ways how close  , and
, and 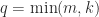 . Then
. Then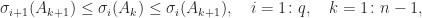
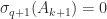 if
if 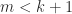 .
.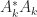 is the leading principal submatrix of order
is the leading principal submatrix of order 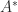 ).
). and
and  , so that
, so that 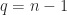 and
and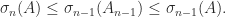
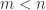 , so
, so 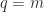 and
and
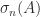 . However, when
. However, when 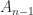 may be less than the smallest singular value of
may be less than the smallest singular value of ![A = [A_{11}~A_{12}]](https://s0.wp.com/latex.php?latex=A+%3D+%5BA_%7B11%7D%7EA_%7B12%7D%5D&bg=ffffff&fg=222222&s=0&c=20201002) then
then 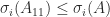 for all
for all  for which the left-hand side is defined.
for which the left-hand side is defined.