The definition of matrix multiplication says that for 







In 1969 Volker Strassen showed that when 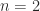

The evaluation requires 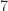
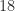


At first sight, Strassen’s formulas may appear simply to be a curiosity. However, the formulas do not rely on commutativity so are valid when the 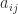

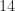


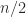
Let us examine the number of multiplications for the recursive Strassen algorithm. Denote by 
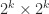
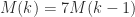

But 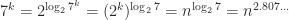
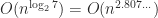
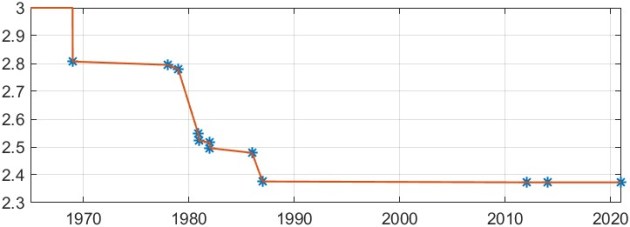
Strassen’s work sparked interest in finding matrix multiplication algorithms of even lower complexity. Since there are 
The current record upper bound on the exponent is 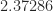
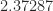
In the methods that achieve exponents lower than 2.775, various intricate techniques are used, based on representing matrix multiplication in terms of bilinear or trilinear forms and their representation as tensors having low rank. Laderman, Pan, and Sha (1993) explain that for these methods “very large overhead constants are hidden in the `
Strassen’s method, when carefully implemented, can be faster than conventional matrix multiplication for reasonable dimensions. In practice, one does not recur down to 

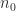
Strassen’s method has the drawback that it satisfies a weaker form of rounding error bound that conventional multiplication. For conventional multiplication 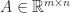


where 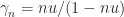

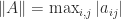
Theorem 1 (Brent). Let
, where
. Suppose that
is computed by Strassen’s method and that
is the threshold at which conventional multiplication is used. The computed product
satisfies
![\notag \|C - \widehat{C}\| \le \left[ \Bigl( \displaystyle\frac{n}{n_0} \Bigr)^{\log_2{12}} (n_0^2+5n_0) - 5n \right] u \|A\|\, \|B\| + O(u^2). \qquad(2)](https://s0.wp.com/latex.php?latex=%5Cnotag++++%5C%7CC+-+%5Cwidehat%7BC%7D%5C%7C+%5Cle+%5Cleft%5B+%5CBigl%28+%5Cdisplaystyle%5Cfrac%7Bn%7D%7Bn_0%7D+%5CBigr%29%5E%7B%5Clog_2%7B12%7D%7D+++++++++++++++++++++++%28n_0%5E2%2B5n_0%29+-+5n+%5Cright%5D+u+%5C%7CA%5C%7C%5C%2C+%5C%7CB%5C%7C+++++++++++++++++++++++%2B+O%28u%5E2%29.+%5Cqquad%282%29+&bg=ffffff&fg=222222&s=0&c=20201002)
With full recursion (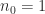
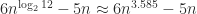
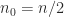

The fact that Strassen’s method does not satisfy a componentwise error bound is a significant weakness of the method. Indeed Strassen’s method cannot even accurately multiply by the identity matrix. The product
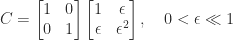
is evaluated exactly in floating-point arithmetic by conventional multiplication, but Strassen’s method computes

Because 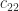
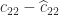

Another weakness of Strassen’s method is that while the scaling 

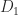


Should one use Strassen’s method in practice, assuming that an implementation is available that is faster than conventional multiplication? Not if one needs a componentwise error bound, which ensures accurate products of matrices with nonnegative entries and ensures that the column scaling of
Notes
For recent work on high-performance implementation of Strassen’s method see Huang et al. (2016, 2020).
Theorem 1 is from an unpublished technical report of Brent (1970). A proof can be found in Higham (2002, §23.2.2).
For more on fast matrix multiplication see Bini (2014) and Higham (2002, Chapter 23).
References
This is a minimal set of references, which contain further useful references within.
- Josh Alman and Virginia Vassilevska Williams. A refined laser method and faster matrix multiplication. In Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms (SODA), Society for Industrial and Applied Mathematics, January 2021, pages 522–539.
- Grey Ballard, Austin R. Benson, Alex Druinsky, Benjamin Lipshitz, and Oded Schwartz. Improving the numerical stability of fast matrix multiplication. SIAM J. Matrix Anal. Appl, 37(4):1382–1418, 2016.
- Benson, Alex Druinsky, Benjamin Lipshitz, and Oded Schwartz. Improving the numerical stability of fast matrix multiplication. SIAM J. Matrix Anal. Appl., 37(4):1382–1418, 2016.
- Dario A. Bini. Fast matrix multiplication. In Handbook of Linear Algebra, Leslie Hogben, editor, second edition, Chapman and Hall/CRC, Boca Raton, FL, USA, 2014, pages 61.1–61.17.
- Bogdan Dumitrescu. Improving and estimating the accuracy of Strassen’s algorithm. Numer. Math., 79:485–499, 1998.
- Nicholas J. Higham, Accuracy and Stability of Numerical Algorithms, second edition, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2002.
- Jianyu Huang, Tyler M. Smith, Greg M. Henry, and Robert A. van de Geijn. Strassen’s algorithm reloaded. In SC16: International Conference for High Performance Computing, Networking, Storage and Analysis, IEEE, November 2016.
- Jianyu Huang, Chenhan D. Yu, and Robert A. van de Geijn. Strassen’s algorithm reloaded on GPUs, ACM Trans. Math. Software, 46(1):1:1–1:22, 2020.
- Julian Laderman, Victor Pan, and Xuan-He Sha. On practical algorithms for accelerated matrix multiplication. Linear Algebra Appl., 162–164:557–588, 1992.
- François Le Gall. Powers of tensors and fast matrix multiplication. In Proceedings of the 39th International Symposium on Symbolic and Algebraic Computation, 2014, pages 296–303.
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
 is the symmetric matrix defined by
is the symmetric matrix defined by
![\notag P_5 = \left[\begin{array}{ccccc} 1 & 1 & 1 & 1 & 1\\ 1 & 2 & 3 & 4 & 5\\ 1 & 3 & 6 & 10 & 15\\ 1 & 4 & 10 & 20 & 35\\ 1 & 5 & 15 & 35 & 70 \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cnotag++P_5+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccc%7D+++++1+%26+1+%26+1+%26+1+%26+1%5C%5C+++++1+%26+2+%26+3+%26+4+%26+5%5C%5C+++++1+%26+3+%26+6+%26+10+%26+15%5C%5C+++++1+%26+4+%26+10+%26+20+%26+35%5C%5C+++++1+%26+5+%26+15+%26+35+%26+70+%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)

 are the rows of Pascal’s triangle. For example,
are the rows of Pascal’s triangle. For example,![\notag L_5 = \left[\begin{array}{ccccc} 1 & 0 & 0 & 0 & 0\\ 1 & 1 & 0 & 0 & 0\\ 1 & 2 & 1 & 0 & 0\\ 1 & 3 & 3 & 1 & 0\\ 1 & 4 & 6 & 4 & 1 \end{array}\right]\\](https://s0.wp.com/latex.php?latex=%5Cnotag++++L_5+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccc%7D+1+%26+0+%26+0+%26+0+%26+0%5C%5C+1+%26+1+%26+0+%26+0+%26+0%5C%5C+1+%26+2+%26+1+%26+0+%26+0%5C%5C+1+%26+3+%26+3+%26+1+%26+0%5C%5C+1+%26+4+%26+6+%26+4+%26+1+%5Cend%7Barray%7D%5Cright%5D%5C%5C+&bg=ffffff&fg=222222&s=0&c=20201002)
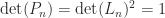 . Form this equation, or by inverting (1), it follows that
. Form this equation, or by inverting (1), it follows that 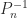 has integer elements. Indeed the inverse is known to have
has integer elements. Indeed the inverse is known to have  element
element

 is unit lower bidiagonal with the first
is unit lower bidiagonal with the first 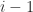 entries along the subdiagonal of
entries along the subdiagonal of  . For example,
. For example,![\notag \begin{aligned} L_5 = \left[\begin{array}{ccccc} 1 & 0 & 0 & 0 & 0\\ 0 & 1 & 0 & 0 & 0\\ 0 & 0 & 1 & 0 & 0\\ 0 & 0 & 0 & 1 & 0\\ 0 & 0 & 0 & 1 & 1 \end{array}\right] \left[\begin{array}{ccccc} 1 & 0 & 0 & 0 & 0\\ 0 & 1 & 0 & 0 & 0\\ 0 & 0 & 1 & 0 & 0\\ 0 & 0 & 1 & 1 & 0\\ 0 & 0 & 0 & 1 & 1 \end{array}\right] \left[\begin{array}{ccccc} 1 & 0 & 0 & 0 & 0\\ 0 & 1 & 0 & 0 & 0\\ 0 & 1 & 1 & 0 & 0\\ 0 & 0 & 1 & 1 & 0\\ 0 & 0 & 0 & 1 & 1 \end{array}\right] \left[\begin{array}{ccccc} 1 & 0 & 0 & 0 & 0\\ 1 & 1 & 0 & 0 & 0\\ 0 & 1 & 1 & 0 & 0\\ 0 & 0 & 1 & 1 & 0\\ 0 & 0 & 0 & 1 & 1 \end{array}\right]. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cnotag+%5Cbegin%7Baligned%7D++++L_5+%3D+++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccc%7D+1+%26+0+%26+0+%26+0+%26+0%5C%5C+0+%26+1+%26+0+%26+0+%26+0%5C%5C+0+%26+0+%26+1+%26+0+%26+0%5C%5C+0+%26+0+%26+0+%26+1+%26+0%5C%5C+0+%26+0+%26+0+%26+1+%26+1+%5Cend%7Barray%7D%5Cright%5D+++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccc%7D+1+%26+0+%26+0+%26+0+%26+0%5C%5C+0+%26+1+%26+0+%26+0+%26+0%5C%5C+0+%26+0+%26+1+%26+0+%26+0%5C%5C+0+%26+0+%26+1+%26+1+%26+0%5C%5C+0+%26+0+%26+0+%26+1+%26+1+%5Cend%7Barray%7D%5Cright%5D+++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccc%7D+1+%26+0+%26+0+%26+0+%26+0%5C%5C+0+%26+1+%26+0+%26+0+%26+0%5C%5C+0+%26+1+%26+1+%26+0+%26+0%5C%5C+0+%26+0+%26+1+%26+1+%26+0%5C%5C+0+%26+0+%26+0+%26+1+%26+1+%5Cend%7Barray%7D%5Cright%5D+++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccc%7D+1+%26+0+%26+0+%26+0+%26+0%5C%5C+1+%26+1+%26+0+%26+0+%26+0%5C%5C+0+%26+1+%26+1+%26+0+%26+0%5C%5C+0+%26+0+%26+1+%26+1+%26+0%5C%5C+0+%26+0+%26+0+%26+1+%26+1+%5Cend%7Barray%7D%5Cright%5D.+%5Cend%7Baligned%7D+&bg=ffffff&fg=222222&s=0&c=20201002)
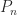 is totally positive, that is, every minor (a determinant of a square submatrix) is positive. Indeed each bidiagonal factor
is totally positive, that is, every minor (a determinant of a square submatrix) is positive. Indeed each bidiagonal factor 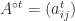 , which is the matrix with every entry raised to the power
, which is the matrix with every entry raised to the power  . We say that
. We say that  is positive semidefinite for all nonnegative
is positive semidefinite for all nonnegative  . The Pascal matrix is infinitely divisible.
. The Pascal matrix is infinitely divisible.
 . In other words,
. In other words,  is involutory, that is,
is involutory, that is, 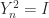 . It follows from
. It follows from  that
that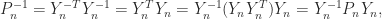

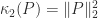 . Hence, using Stirling’s approximation (
. Hence, using Stirling’s approximation (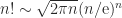 ),
),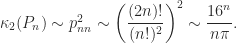
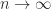 .
.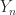 is obtained in MATLAB with
is obtained in MATLAB with 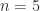 :
:![\notag \hspace*{-1cm} X = \left[\begin{array}{rrrrr} 1 & 1 & 1 & 1 & 1\\ -4 & -3 & -2 & -1 & 0\\ 6 & 3 & 1 & 0 & 0\\ -4 & -1 & 0 & 0 & 0\\ 1 & 0 & 0 & 0 & 0 \end{array}\right], \quad X^2 = \left[\begin{array}{rrrrr} 0 & 0 & 0 & 0 & 1\\ 0 & 0 & 0 & -1 & -4\\ 0 & 0 & 1 & 3 & 6\\ 0 & -1 & -2 & -3 & -4\\ 1 & 1 & 1 & 1 & 1 \end{array}\right], \quad X^3 = I.](https://s0.wp.com/latex.php?latex=%5Cnotag+%5Chspace%2A%7B-1cm%7D+X+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Brrrrr%7D+1+%26+1+%26+1+%26+1+%26+1%5C%5C+-4+%26+-3+%26+-2+%26+-1+%26+0%5C%5C+6+%26+3+%26+1+%26+0+%26+0%5C%5C+-4+%26+-1+%26+0+%26+0+%26+0%5C%5C+1+%26+0+%26+0+%26+0+%26+0+%5Cend%7Barray%7D%5Cright%5D%2C+%5Cquad+X%5E2+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Brrrrr%7D+0+%26+0+%26+0+%26+0+%26+1%5C%5C+0+%26+0+%26+0+%26+-1+%26+-4%5C%5C+0+%26+0+%26+1+%26+3+%26+6%5C%5C+0+%26+-1+%26+-2+%26+-3+%26+-4%5C%5C+1+%26+1+%26+1+%26+1+%26+1+%5Cend%7Barray%7D%5Cright%5D%2C+%5Cquad+X%5E3+%3D+I.+&bg=ffffff&fg=222222&s=0&c=20201002)
![\notag \log L_n = \left[\begin{array}{ccccc} 0 & 1 & & & \\ & 0 & 2 & & \\[-5pt] & & 0 & \ddots & \\[-5pt] & & & \ddots & n-1\\ & & & & 0 \end{array}\right]. \qquad (5)](https://s0.wp.com/latex.php?latex=%5Cnotag+++%5Clog+L_n+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccc%7D+++++0+%26+1+%26+++%26++++++++%26++%5C%5C+++++++%26+0+%26+2+%26++++++++%26+++%5C%5C%5B-5pt%5D+++++++%26+++%26+0+%26+%5Cddots+%26+++%5C%5C%5B-5pt%5D+++++++%26+++%26+++%26+%5Cddots+%26+n-1%5C%5C+++++++%26+++%26+++%26++++++++%26+0+%5Cend%7Barray%7D%5Cright%5D.++%5Cqquad+%285%29+&bg=ffffff&fg=222222&s=0&c=20201002)
 is a factorization
is a factorization 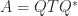 , where
, where  is unitary and
is unitary and  is upper triangular. The diagonal entries of
is upper triangular. The diagonal entries of 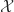 of
of 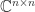 is an invariant subspace of
is an invariant subspace of 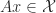 for all
for all 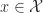 . If we partition
. If we partition ![\notag A [Q_1,~Q_2] = [Q_1,~Q_2] \begin{bmatrix} T_{11} & T_{12} \\ 0 & T_{22} \\ \end{bmatrix},](https://s0.wp.com/latex.php?latex=%5Cnotag+++A+%5BQ_1%2C%7EQ_2%5D+%3D+%5BQ_1%2C%7EQ_2%5D+++%5Cbegin%7Bbmatrix%7D+++T_%7B11%7D+%26+T_%7B12%7D+%5C%5C+++++++0++%26+T_%7B22%7D+%5C%5C+++%5Cend%7Bbmatrix%7D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
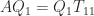 , showing that the columns of
, showing that the columns of  span an invariant subspace of
span an invariant subspace of 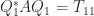 . The first column of
. The first column of 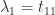 , but the other columns are not eigenvectors, in general. Eigenvectors can be computed by solving upper triangular systems involving
, but the other columns are not eigenvectors, in general. Eigenvectors can be computed by solving upper triangular systems involving 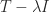 , where
, where 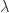 is an eigenvalue.
is an eigenvalue.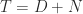 , where
, where 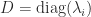 and
and 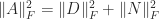 , or
, or
 is independent of the particular Schur decomposition and it provides a measure of the departure from normality. The matrix
is independent of the particular Schur decomposition and it provides a measure of the departure from normality. The matrix 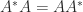 ) if and only if
) if and only if 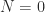 . So a normal matrix is unitarily diagonalizable:
. So a normal matrix is unitarily diagonalizable:  .
.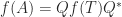 shows that computing
shows that computing  reduces to computing a function of a triangular matrix. Matrix functions illustrate what Van Loan (1975) describes as “one of the most basic tenets of numerical algebra”, namely “anything that the Jordan decomposition can do, the Schur decomposition can do better!”. Indeed the Jordan canonical form is built on a possibly ill conditioned similarity transformation while the Schur decomposition employs a perfectly conditioned unitary similarity, and the full upper triangular factor of the Schur form can do most of what the Jordan form’s bidiagonal factor can do.
reduces to computing a function of a triangular matrix. Matrix functions illustrate what Van Loan (1975) describes as “one of the most basic tenets of numerical algebra”, namely “anything that the Jordan decomposition can do, the Schur decomposition can do better!”. Indeed the Jordan canonical form is built on a possibly ill conditioned similarity transformation while the Schur decomposition employs a perfectly conditioned unitary similarity, and the full upper triangular factor of the Schur form can do most of what the Jordan form’s bidiagonal factor can do.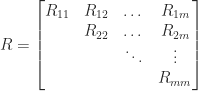
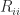 are either
are either 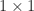 or
or  . A real matrix
. A real matrix  has a real Schur decomposition
has a real Schur decomposition 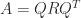 in which in which all the factors are real,
in which in which all the factors are real,  is upper quasi-triangular with any
is upper quasi-triangular with any  blocks
blocks ![R_{ii} = \left[\begin{array}{@{}rr@{\mskip2mu}} a & b \\ -b & a \end{array}\right], \quad b \ne 0,](https://s0.wp.com/latex.php?latex=R_%7Bii%7D+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%7Drr%40%7B%5Cmskip2mu%7D%7D+a+%26+b+%5C%5C++++++++++++++++-b+%26+a+%5Cend%7Barray%7D%5Cright%5D%2C+%5Cquad+b+%5Cne+0%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
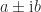 .
.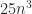 flops for
flops for 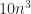 flops for
flops for  say, is orthogonal, that is,
say, is orthogonal, that is,  , so it is nonsingular and has determinant
, so it is nonsingular and has determinant 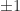 . The total number of
. The total number of  .
. , the reverse identity matrix
, the reverse identity matrix  , and the shift matrix
, and the shift matrix 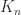 (also called the cyclic permutation matrix), illustrated for
(also called the cyclic permutation matrix), illustrated for 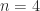 by
by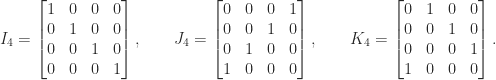
 and
and  , say. It can be written
, say. It can be written 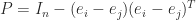 , where
, where 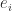 is the
is the  , and it has determinant
, and it has determinant  . A general permutation matrix can be written as a product of elementary permutation matrices
. A general permutation matrix can be written as a product of elementary permutation matrices  , where
, where  is such that
is such that  .
.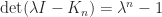 , which means that the eigenvalues of
, which means that the eigenvalues of 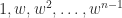 , where
, where  is the
is the  for
for 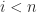 and
and 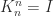 . The following animated gif superposes MATLAB spy plots of
. The following animated gif superposes MATLAB spy plots of  ,
, 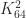 , …,
, …,  .
.
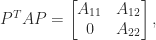
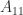 and
and 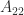 are square, nonempty submatrices.
are square, nonempty submatrices. the following conditions are equivalent.
the following conditions are equivalent.
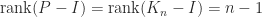 .
.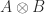 to
to 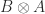 , where
, where  is the Kronecker product.
is the Kronecker product. , where
, where 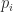 is the column index of the
is the column index of the 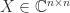 such that
such that 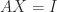 , where
, where  is the identity matrix (which has ones on the diagonal and zeros everywhere else). The inverse is written as
is the identity matrix (which has ones on the diagonal and zeros everywhere else). The inverse is written as  . If the inverse exists then
. If the inverse exists then  of
of  , as we now show. The equation
, as we now show. The equation 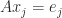 for
for 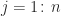 , where
, where 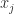 is the
is the 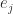 is the
is the 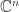 , which means that the columns are linearly independent. Now
, which means that the columns are linearly independent. Now  , so every column of
, so every column of  is in the null space of
is in the null space of  , that is,
, that is,  then premultiplying by
then premultiplying by  , or, since
, or, since  .
. , which is just another way of interpreting the equations
, which is just another way of interpreting the equations  .
.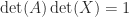 , so the inverse can only exist when
, so the inverse can only exist when  . In fact, the inverse always exists when
. In fact, the inverse always exists when 
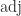 is defined by
is defined by
 denotes the submatrix of
denotes the submatrix of  . A special case is the formula
. A special case is the formula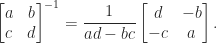
 implies
implies  .
. the null space of
the null space of 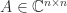 the following conditions are equivalent to
the following conditions are equivalent to 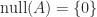 ,
, ,
,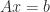 has a unique solution
has a unique solution  , for any
, for any  ,
,
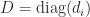 is nonsingular if
is nonsingular if 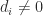 for all
for all  .
.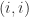 element
element 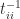 .
.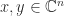 and
and 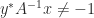 , then
, then  is nonsingular and
is nonsingular and

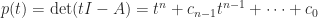 , then
, then 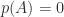 . In other words,
. In other words,  , and if
, and if 

 in
in  then computing
then computing  is both slower and less accurate in floating-point arithmetic than using LU factorization (Gaussian elimination) to solve the system directly. Indeed, for
is both slower and less accurate in floating-point arithmetic than using LU factorization (Gaussian elimination) to solve the system directly. Indeed, for  one would not solve
one would not solve 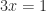 by computing
by computing 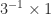 .
.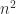 determinants of order
determinants of order 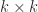 determinant costs at least
determinant costs at least  operations by standard methods, this approach costs at least
operations by standard methods, this approach costs at least 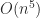 operations, which is prohibitively expensive unless
operations, which is prohibitively expensive unless 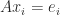 for the columns
for the columns  of
of 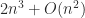 operations.
operations.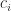 and evaluating a matrix polynomial are both expensive.
and evaluating a matrix polynomial are both expensive. operations for some
operations for some  . By using a block LU factorization recursively, one can reduce matrix inversion to matrix multiplication. If we use Strassen’s fast matrix multiplication method, which has
. By using a block LU factorization recursively, one can reduce matrix inversion to matrix multiplication. If we use Strassen’s fast matrix multiplication method, which has 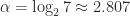 , then we can compute
, then we can compute  operations.
operations.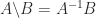 and
and  . Note that because matrix multiplication is not commutative,
. Note that because matrix multiplication is not commutative,  , in general. We have
, in general. We have  and
and  . In MATLAB, the inverse can be compute with
. In MATLAB, the inverse can be compute with 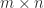 then the equation
then the equation  requires
requires 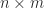 , as does
, as does  . Rank considerations show that at most one of these equations can hold if
. Rank considerations show that at most one of these equations can hold if 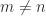 . For example, if
. For example, if  is a nonzero row vector, then
is a nonzero row vector, then 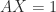 for
for 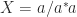 , but
, but 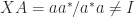 . This is an example of a
. This is an example of a ![\notag \left[\begin{array}{ccccccc} I & N & V & E & R & S & E\\ 0 & N & V & E & R & S & E\\ 0 & 0 & V & E & R & S & E\\ 0 & 0 & 0 & E & R & S & E\\ 0 & 0 & 0 & 0 & R & S & E\\ 0 & 0 & 0 & 0 & 0 & S & E\\ 0 & 0 & 0 & 0 & 0 & 0 & E \end{array}\right]^{-1} = \left[\begin{array}{*{7}{r@{\hspace{4pt}}}} 1/I & -1/I & 0 & 0 & 0 & 0 & 0\\ 0 & 1/N & -1/N & 0 & 0 & 0 & 0\\ 0 & 0 & 1/V & -1/V & 0 & 0 & 0\\ 0 & 0 & 0 & 1/E & -1/E & 0 & 0\\ 0 & 0 & 0 & 0 & 1/R & -1/R & 0\\ 0 & 0 & 0 & 0 & 0 & 1/S & -1/S\\ 0 & 0 & 0 & 0 & 0 & 0 & 1/E \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cnotag+%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccccc%7D+I+%26+N+%26+V+%26+E+%26+R+%26+S+%26+E%5C%5C+0+%26+N+%26+V+%26+E+%26+R+%26+S+%26+E%5C%5C+0+%26+0+%26+V+%26+E+%26+R+%26+S+%26+E%5C%5C+0+%26+0+%26+0+%26+E+%26+R+%26+S+%26+E%5C%5C+0+%26+0+%26+0+%26+0+%26+R+%26+S+%26+E%5C%5C+0+%26+0+%26+0+%26+0+%26+0+%26+S+%26+E%5C%5C+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+E+%5Cend%7Barray%7D%5Cright%5D%5E%7B-1%7D+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7B%2A%7B7%7D%7Br%40%7B%5Chspace%7B4pt%7D%7D%7D%7D+1%2FI+%26+-1%2FI+%26+0+%26+0+%26+0+%26+0+%26+0%5C%5C+0+%26+1%2FN+%26+-1%2FN+%26+0+%26+0+%26+0+%26+0%5C%5C+0+%26+0+%26+1%2FV+%26+-1%2FV+%26+0+%26+0+%26+0%5C%5C+0+%26+0+%26+0+%26+1%2FE+%26+-1%2FE+%26+0+%26+0%5C%5C+0+%26+0+%26+0+%26+0+%26+1%2FR+%26+-1%2FR+%26+0%5C%5C+0+%26+0+%26+0+%26+0+%26+0+%26+1%2FS+%26+-1%2FS%5C%5C+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+1%2FE+%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
 ?
?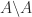 returns. I will summarize what backslash does in general, for
returns. I will summarize what backslash does in general, for 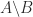 and then consider the case
and then consider the case 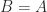 .
.
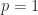 , because backslash treats the columns independently, and we write this as
, because backslash treats the columns independently, and we write this as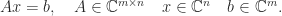
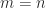
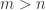
 nonzeros. Such a solution is not, in general, unique.
nonzeros. Such a solution is not, in general, unique.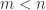
 produces a basic solution and in the former case a basic LS solution. Example:
produces a basic solution and in the former case a basic LS solution. Example:![[0~2~1]^T](https://s0.wp.com/latex.php?latex=%5B0%7E2%7E1%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002) , and the minimum
, and the minimum ![[1~1~1]^T](https://s0.wp.com/latex.php?latex=%5B1%7E1%7E1%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002) .
. . If
. If 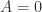 then
then 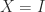 is not a basic solution, so
is not a basic solution, so  ; in fact,
; in fact, 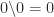 if
if 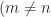 ). Often, one wants the solution of minimum
). Often, one wants the solution of minimum 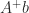 , where
, where 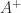 is the pseudoinverse of
is the pseudoinverse of 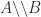 . Then
. Then  , which is the orthogonal projector onto
, which is the orthogonal projector onto  , and it is equal to the identity matrix when
, and it is equal to the identity matrix when 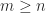 and
and 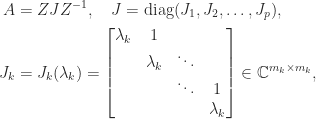
 is nonsingular and
is nonsingular and  . The matrix
. The matrix 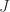 is unique up to the ordering of the blocks
is unique up to the ordering of the blocks  .
.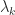 repeated
repeated  times and
times and  . Two different Jordan blocks can have the same eigenvalues.
. Two different Jordan blocks can have the same eigenvalues. we have
we have
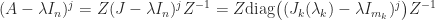 , and so
, and so
 , these quantities provide information about the size of the Jordan blocks associated with
, these quantities provide information about the size of the Jordan blocks associated with 
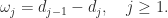
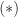 above, it can be shown that
above, it can be shown that  is the number of Jordan blocks of size at least
is the number of Jordan blocks of size at least  . Therefore if we know the eigenvalues and the ranks of
. Therefore if we know the eigenvalues and the ranks of  for each eigenvalue
for each eigenvalue  then we know that
then we know that  .
.![B = \bigl[\begin{smallmatrix} 0_r & I_r\\0_r & 0_r \end{smallmatrix}\bigr]](https://s0.wp.com/latex.php?latex=B+%3D+%5Cbigl%5B%5Cbegin%7Bsmallmatrix%7D+0_r+%26+I_r%5C%5C0_r+%26+0_r+%5Cend%7Bsmallmatrix%7D%5Cbigr%5D&bg=ffffff&fg=222222&s=0&c=20201002) , for which
, for which  and all the eigenvalues are zero. Since
and all the eigenvalues are zero. Since  , we have
, we have 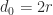 ,
,  , and
, and  . Hence
. Hence  and
and  , so there are
, so there are 
 matrix
matrix ![\notag A = \left[\begin{array}{ccccccccccc} 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0\\ 1 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0\\ 0 & 0 & 1 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0\\ 0 & 1 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0\\ 0 & 0 & 0 & 0 & 1 & 0 & 0 & 1 & 0 & 0 & 0\\ 0 & 0 & 1 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0\\ 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 1\\ 0 & 0 & 0 & 1 & 0 & 0 & 0 & 1 & 0 & 0 & 0\\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0\\ 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 1 & 0\\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cnotag+A+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccccccccc%7D+1+%26+1+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0%5C%5C+1+%26+1+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0%5C%5C+0+%26+0+%26+1+%26+0+%26+1+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0%5C%5C+0+%26+1+%26+0+%26+1+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0%5C%5C+0+%26+0+%26+0+%26+0+%26+1+%26+0+%26+0+%26+1+%26+0+%26+0+%26+0%5C%5C+0+%26+0+%26+1+%26+0+%26+0+%26+1+%26+0+%26+0+%26+0+%26+0+%26+0%5C%5C+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+1+%26+0+%26+0+%26+0+%26+1%5C%5C+0+%26+0+%26+0+%26+1+%26+0+%26+0+%26+0+%26+1+%26+0+%26+0+%26+0%5C%5C+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+1+%26+0+%26+0%5C%5C+0+%26+0+%26+0+%26+0+%26+1+%26+0+%26+0+%26+0+%26+0+%26+1+%26+0%5C%5C+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+0+%26+1+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=222222&s=0&c=20201002)
 and
and 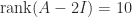 , so
, so  and
and  and
and 
 , one block of order
, one block of order  implies
implies
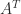 are similar.
are similar. . The main change is how complex eigenvalues are represented. Since the eigenvalues now occur in complex conjugate pairs
. The main change is how complex eigenvalues are represented. Since the eigenvalues now occur in complex conjugate pairs  , and each of the pair has the same Jordan structure (which follows from the fact that a matrix and its complex conjugate have the same rank), pairs of Jordan blocks corresponding to
, and each of the pair has the same Jordan structure (which follows from the fact that a matrix and its complex conjugate have the same rank), pairs of Jordan blocks corresponding to 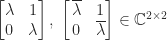
![\notag \left[\begin{array}{@{\mkern3mu}rr|rr@{\mkern7mu}} a & b & 1 & 0 \\ -b & a & 0 & 1 \\\hline 0 & 0 & a & b \\ 0 & 0 &-b & a \end{array}\right] \in\mathbb{R}^{4 \times 4}](https://s0.wp.com/latex.php?latex=%5Cnotag+++++%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%5Cmkern3mu%7Drr%7Crr%40%7B%5Cmkern7mu%7D%7D++++++++++a+%26+b+%26+1+%26+0+%5C%5C+++++++++-b+%26+a+%26+0+%26+1+%5C%5C%5Chline++++++++++0+%26+0+%26+a+%26+b+%5C%5C++++++++++0+%26+0+%26-b+%26+a++++++++++%5Cend%7Barray%7D%5Cright%5D++%5Cin%5Cmathbb%7BR%7D%5E%7B4+%5Ctimes+4%7D+&bg=ffffff&fg=222222&s=0&c=20201002)
 . Note that the eigenvalues of
. Note that the eigenvalues of ![\bigl[\begin{smallmatrix} a & b \\ -b & a \end{smallmatrix}\bigr]](https://s0.wp.com/latex.php?latex=%5Cbigl%5B%5Cbegin%7Bsmallmatrix%7D+a+%26+b+%5C%5C+-b+%26+a+%5Cend%7Bsmallmatrix%7D%5Cbigr%5D+&bg=ffffff&fg=222222&s=0&c=20201002) are
are  .
.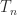 with diagonal elements
with diagonal elements ![\notag T_n = \left[ \begin{array}{@{}*{4}{r@{\mskip10mu}}r} 2 & -1 & & & \\ -1 & 2 & -1 & & \\[-5pt] & -1 & 2 & \ddots & \\ & & \ddots & \ddots & -1 \\ & & & -1 & 2 \end{array}\right] \in\mathbb{R}^{n\times n}.](https://s0.wp.com/latex.php?latex=%5Cnotag++++T_n+%3D+%5Cleft%5B++++%5Cbegin%7Barray%7D%7B%40%7B%7D%2A%7B4%7D%7Br%40%7B%5Cmskip10mu%7D%7Dr%7D+++++++++++++++++2++%26+-1+%26++++++++%26++++++++%26++++%5C%5C+++++++++++++++++-1+%26+2++%26+-1+++++%26++++++++%26++++%5C%5C%5B-5pt%5D++++++++++++++++++++%26+-1+%26+2++++++%26+%5Cddots+%26++++%5C%5C++++++++++++++++++++%26++++%26+%5Cddots+%26+%5Cddots+%26+-1+%5C%5C++++++++++++++++++++%26++++%26++++++++%26+-1+++++%26+2++++%5Cend%7Barray%7D%5Cright%5D+%5Cin%5Cmathbb%7BR%7D%5E%7Bn%5Ctimes+n%7D.+&bg=ffffff&fg=222222&s=0&c=20201002)
 . (Accordingly, the second difference matrix is sometimes defined as
. (Accordingly, the second difference matrix is sometimes defined as 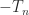 .) In MATLAB,
.) In MATLAB, 
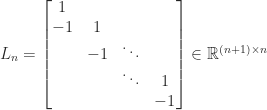
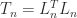 . The factorization corresponds to representing a central difference as the product of a forward difference and a backward difference. Other properties of the second difference matrix are that it is diagonally dominant, a Toeplitz matrix, and an
. The factorization corresponds to representing a central difference as the product of a forward difference and a backward difference. Other properties of the second difference matrix are that it is diagonally dominant, a Toeplitz matrix, and an  -matrix.
-matrix.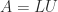 the pivots
the pivots 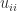 are
are 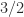 ,
, 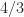 , …,
, …, 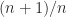 . Hence the pivots form a decreasing sequence tending to 1 as
. Hence the pivots form a decreasing sequence tending to 1 as 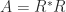 with
with 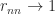 and
and  as
as  .
.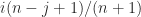 for
for 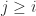 . For example,
. For example,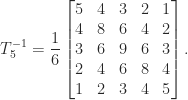
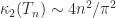 (as follows from the formula (1) below for the eigenvalues).
(as follows from the formula (1) below for the eigenvalues).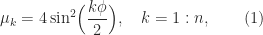
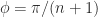 , with corresponding eigenvector
, with corresponding eigenvector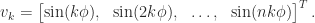
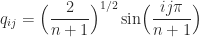
 .
.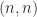 element to
element to ![\notag \widetilde{T}_n = \left[ \begin{array}{@{}*{4}{r@{\mskip10mu}}r} 2 & -1 & & & \\ -1 & 2 & -1 & & \\[-5pt] & -1 & 2 & \ddots & \\ & & \ddots & \ddots & -1 \\ & & & -1 & 1 \end{array}\right] \in\mathbb{R}^{n\times n}.](https://s0.wp.com/latex.php?latex=%5Cnotag++++%5Cwidetilde%7BT%7D_n+%3D+%5Cleft%5B++++%5Cbegin%7Barray%7D%7B%40%7B%7D%2A%7B4%7D%7Br%40%7B%5Cmskip10mu%7D%7Dr%7D+++++++++++++++++2++%26+-1+%26++++++++%26++++++++%26++++%5C%5C+++++++++++++++++-1+%26+2++%26+-1+++++%26++++++++%26++++%5C%5C%5B-5pt%5D++++++++++++++++++++%26+-1+%26+2++++++%26+%5Cddots+%26++++%5C%5C++++++++++++++++++++%26++++%26+%5Cddots+%26+%5Cddots+%26+-1+%5C%5C++++++++++++++++++++%26++++%26++++++++%26+-1+++++%26+1++++%5Cend%7Barray%7D%5Cright%5D+%5Cin%5Cmathbb%7BR%7D%5E%7Bn%5Ctimes+n%7D.+&bg=ffffff&fg=222222&s=0&c=20201002)
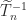 has
has 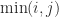 and eigenvalues
and eigenvalues  ,
,  .
.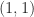 of
of 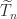 to
to 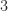 :
:![\notag \widehat{T}_n = \left[ \begin{array}{@{}*{4}{r@{\mskip10mu}}r} 3 & -1 & & & \\ -1 & 2 & -1 & & \\[-5pt] & -1 & 2 & \ddots & \\ & & \ddots & \ddots & -1 \\ & & & -1 & 1 \end{array}\right] \in\mathbb{R}^{n\times n}.](https://s0.wp.com/latex.php?latex=%5Cnotag++++%5Cwidehat%7BT%7D_n+%3D+%5Cleft%5B++++%5Cbegin%7Barray%7D%7B%40%7B%7D%2A%7B4%7D%7Br%40%7B%5Cmskip10mu%7D%7Dr%7D+++++++++++++++++3++%26+-1+%26++++++++%26++++++++%26++++%5C%5C+++++++++++++++++-1+%26+2++%26+-1+++++%26++++++++%26++++%5C%5C%5B-5pt%5D++++++++++++++++++++%26+-1+%26+2++++++%26+%5Cddots+%26++++%5C%5C++++++++++++++++++++%26++++%26+%5Cddots+%26+%5Cddots+%26+-1+%5C%5C++++++++++++++++++++%26++++%26++++++++%26+-1+++++%26+1++++%5Cend%7Barray%7D%5Cright%5D+%5Cin%5Cmathbb%7BR%7D%5E%7Bn%5Ctimes+n%7D.+&bg=ffffff&fg=222222&s=0&c=20201002)
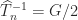 , where
, where  with
with 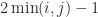 is a matrix of Givens, and the eigenvalues are
is a matrix of Givens, and the eigenvalues are  ,
,  is noted by Strang (2012).
is noted by Strang (2012).![\notag F_n = \left[\begin{array}{*{6}c} n & n-1 & n-2 & \dots & 2 & 1 \\ n-1 & n-1 & n-2 & \dots & 2 & 1 \\ 0 & n-2 & n-2 & \dots & 2 & 1 \\[-3pt] \vdots & 0 & \ddots & \ddots & \vdots & 1 \\[-3pt] \vdots & \vdots & \dots & 2 & 2 & 1 \\ 0 & 0 & \dots & 0 & 1 & 1 \\ \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cnotag+++F_n+%3D+++%5Cleft%5B%5Cbegin%7Barray%7D%7B%2A%7B6%7Dc%7D+++n++++++%26+n-1++++%26+n-2++++%26+%5Cdots++%26+2++++++%26+1+%5C%5C+++n-1++++%26+n-1++++%26+n-2++++%26+%5Cdots++%26+2++++++%26+1+%5C%5C+++0++++++%26+n-2++++%26+n-2++++%26+%5Cdots++%26+2++++++%26+1+%5C%5C%5B-3pt%5D+++%5Cvdots+%26+0++++++%26+%5Cddots+%26+%5Cddots+%26+%5Cvdots+%26+1+%5C%5C%5B-3pt%5D+++%5Cvdots+%26+%5Cvdots+%26+%5Cdots++%26+++2++++%26+2++++++%26+1+%5C%5C+++0++++++%26+0++++++%26+%5Cdots++%26+++0++++%26+1++++++%26+1+%5C%5C+++%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=222222&s=0&c=20201002)
 , and since
, and since  we have
we have  .
.
 element from 1 to
element from 1 to 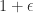 changes the determinant by
changes the determinant by  .
.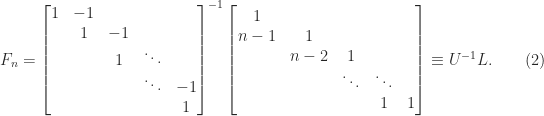
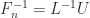 is lower Hessenberg with integer entries. This factorization provides another way to see that
is lower Hessenberg with integer entries. This factorization provides another way to see that 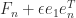 is singular for
is singular for 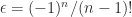 , which implies that
, which implies that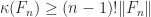
 of the condition number for the
of the condition number for the 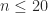 .
. the characteristic polynomial of
the characteristic polynomial of 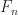 . By expanding about the first column one can show that
. By expanding about the first column one can show that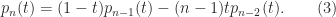
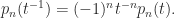
 is an eigenvalue when
is an eigenvalue when 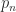 is palindromic when
is palindromic when  for any
for any  can perturb
can perturb 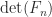 by
by 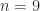 .
.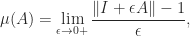
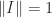 .
.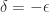 ,
,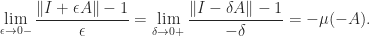
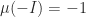 .
.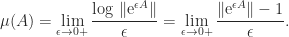
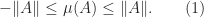
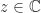 , we define
, we define 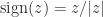 for
for 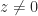 and
and  .
.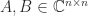 and
and 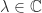 ,
,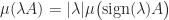 ,
, ,
, ,
,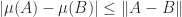 .
. features in an easily evaluated bound for the norm of
features in an easily evaluated bound for the norm of  and that, moreover,
and that, moreover, 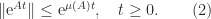

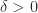 , by Lemma 1 there exists
, by Lemma 1 there exists 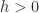 such that
such that![\notag \displaystyle\frac{ \| \mathrm{e}^{At}\| - 1}{t} - \mu(A) < \delta, \quad t\in[0,h],](https://s0.wp.com/latex.php?latex=%5Cnotag+++++%5Cdisplaystyle%5Cfrac%7B+%5C%7C+%5Cmathrm%7Be%7D%5E%7BAt%7D%5C%7C+-+1%7D%7Bt%7D+-+%5Cmu%28A%29+%3C+%5Cdelta%2C+++++%5Cquad+t%5Cin%5B0%2Ch%5D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
![\notag \| \mathrm{e}^{At}\| \le 1 + (\mu(A) + \delta)t \le \mathrm{e}^{(\mu(A) + \delta)t}, \quad t\in[0,h]](https://s0.wp.com/latex.php?latex=%5Cnotag+++++%5C%7C+%5Cmathrm%7Be%7D%5E%7BAt%7D%5C%7C+%5Cle+1+%2B+%28%5Cmu%28A%29+%2B+%5Cdelta%29t+++++++++%5Cle+%5Cmathrm%7Be%7D%5E%7B%28%5Cmu%28A%29+%2B+%5Cdelta%29t%7D%2C+++++%5Cquad+t%5Cin%5B0%2Ch%5D+&bg=ffffff&fg=222222&s=0&c=20201002)
 for all
for all 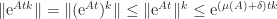 , and hence
, and hence  holds for all
holds for all  . Since
. Since 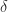 is arbitrary, it follows that
is arbitrary, it follows that 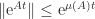 .
. for all
for all  then
then 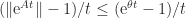 for all
for all  and taking
and taking  we conclude that
we conclude that  .
. , but
, but 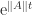 is increasing in
is increasing in 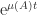 potentially decays, since
potentially decays, since  is possible.
is possible.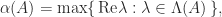
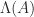 denotes the spectrum of
denotes the spectrum of 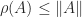 ), the logarithmic norm bounds the spectral abscissa, as shown by the next result.
), the logarithmic norm bounds the spectral abscissa, as shown by the next result.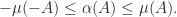

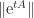 at
at 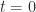 , so
, so 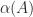 , since
, since 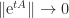 as
as 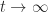 if and only if
if and only if 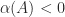 , which can be proved using the Jordan canonical form.
, which can be proved using the Jordan canonical form. then
then
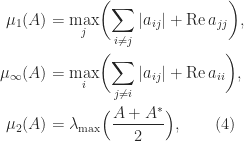
 denotes the largest eigenvalue of a Hermitian matrix.
denotes the largest eigenvalue of a Hermitian matrix.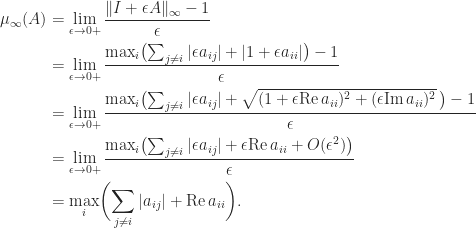
 follows, since
follows, since  implies
implies  . For the
. For the  , we have
, we have
 .
.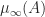 for
for 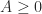 then
then  .
.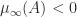 if and only if
if and only if 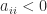 for all
for all 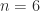 by
by![\notag A_6 = \left[\begin{array}{cccccc} -5 & 2 & 0 & 0 & 0 & 0\\ \frac{1}{2} & -7 & 3 & 0 & 0 & 0\\ 0 & \frac{1}{3} & -9 & 4 & 0 & 0\\ 0 & 0 & \frac{1}{4} & -11 & 5 & 0\\ 0 & 0 & 0 & \frac{1}{5} & -13 & 6\\ 0 & 0 & 0 & 0 & \frac{1}{6} & -15 \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cnotag+++++A_6+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccccc%7D++++++-5+%26+2+%26+0+%26+0+%26+0+%26+0%5C%5C++++++%5Cfrac%7B1%7D%7B2%7D+%26+-7+%26+3+%26+0+%26+0+%26+0%5C%5C++++++0+%26+%5Cfrac%7B1%7D%7B3%7D+%26+-9+%26+4+%26+0+%26+0%5C%5C++++++0+%26+0+%26+%5Cfrac%7B1%7D%7B4%7D+%26+-11+%26+5+%26+0%5C%5C++++++0+%26+0+%26+0+%26+%5Cfrac%7B1%7D%7B5%7D+%26+-13+%26+6%5C%5C++++++0+%26+0+%26+0+%26+0+%26+%5Cfrac%7B1%7D%7B6%7D+%26+-15++++++%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
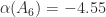 and
and 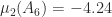 , and it is easy to see that
, and it is easy to see that  and
and  for all
for all 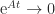 as
as 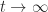 and
and  gives a faster decaying bound than
gives a faster decaying bound than 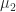 and
and 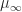 .
.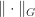 based on the vector norm
based on the vector norm 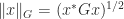 , where
, where 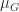 can be expressed as the largest eigenvalue of a Hermitian definite generalized eigenvalue problem.
can be expressed as the largest eigenvalue of a Hermitian definite generalized eigenvalue problem.
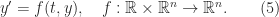
 be symmetric positive definite and consider the inner product
be symmetric positive definite and consider the inner product 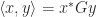 and the corresponding norm defined by
and the corresponding norm defined by 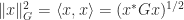 . It can be shown that for
. It can be shown that for 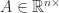 ,
,
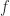 satisfies a one-sided Lipschitz condition if there is a function
satisfies a one-sided Lipschitz condition if there is a function  such that
such that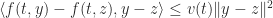
 in some region and all
in some region and all 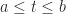 . For the linear differential equation with
. For the linear differential equation with 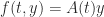 in (5), using (6) we obtain
in (5), using (6) we obtain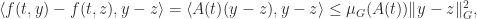
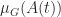 can be taken as a one-sided Lipschitz constant. This observation leads to results on contractivity of ODEs; see Lambert (1991) for details.
can be taken as a one-sided Lipschitz constant. This observation leads to results on contractivity of ODEs; see Lambert (1991) for details.