A norm on 
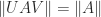
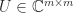
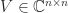
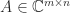
Two widely used matrix norms are unitarily invariant: the 




For the Frobenius norm, using 

since the trace is invariant under similarity transformations.
More insight into unitarily invariant norms comes from recognizing a connection with the singular value decomposition

Clearly, 
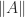



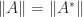

There is a beautiful characterization of unitarily invariant norms in terms of symmetric gauge functions, which are functions 
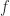




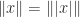

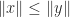

Theorem.
A norm on
for all
are the singular values of
The matrix 


The Schatten 

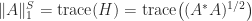
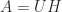
Another class of unitarily invariant norms is the Ky Fan 

We have 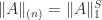
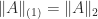
Among unitarily invariant norms, the
The benefit of the concept of unitarily invariant norm is that one can prove certain results for this whole class of norms, obtaining results for the particular norms of interest as special cases. Here are three important examples.
- For
, the matrix
is the nearest Hermitian matrix to
- For
(
), the unitary polar factor is the nearest matrix with orthonormal columns to
- The best rank-
Theorem.
Let
have SVDs with diagonal matrices
, where the diagonal elements are arranged in nonincreasing order. Then
for every unitarily invariant norm.
We also give a useful matrix norm inequality. For any matrices 


holds for any unitarily invariant norm, and in fact, any two of the norms on the right-hand side can be 2-norms.
Finally, here are three interesting facts about unitarily invariant norms.
- A unitarily invariant norm is consistent, that is, it satisfies
for all
if and only if
for all
- A unitarily invariant norm is absolute, that is,
for all
if and only if the norm is a positive scalar multiple of the Frobenius norm.
- The only subordinate unitarily invariant norm is the
References
This is a minimal set of references, which contain further useful references within.
- Roger Horn and Charles Johnson, Topics in Matrix Analysis, Cambridge University Press, 1991. Section 3.5.
- Roger A. Horn and Charles R. Johnson, Matrix Analysis, second edition, Cambridge University Press, 2013. Sections 5.6, 7.4. My review of the second edition.
- L. Mirsky, Symmetric Gauge Functions and Unitarily Invariant Norms, Quart. J. Math. 11, 50–59, 1960.
- Benjamin Recht, Maryam Fazel, and Pablo Parrilo, Guaranteed Minimum-Rank Solutions of Linear Matrix Equations via Nuclear Norm Minimization, SIAM Rev. 52 (3), 471–501, 2010.
Related Blog Posts
- What Is the Nearest Symmetric Matrix? (2020)
- What Is the Polar Decomposition? (2020)
- What Is the Singular Value Decomposition? (2020)
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.

Hi,
The trace must be missing the superscript $trace(V^*A^*AV)$ after the 3rd equal sign below “For the Frobenius norm, using”
Thanks – I have fixed the typo.