The adjugate of an 

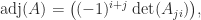
where 


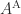
The adjugate satisfies
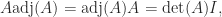
so for nonsingular
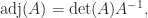
and this equation is often used to give a formula for 
Since the adjugate is a scalar multiple of the inverse, we would expect it to share some properties of the inverse. Indeed we have
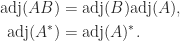
These properties can be proved by first assuming the matrices are nonsingular—in which case they follow from properties of the determinant and the inverse—and then using continuity of the entries of 

If 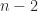




Less obviously, if 
If 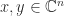
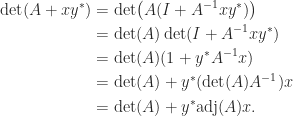
Again it follows by continuity that for any

This expression is useful when we need to deal with a rank-1 perturbation to a singular matrix. A related identity is

Let 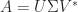


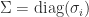
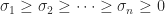
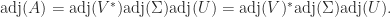
It is easy to see that 

Since

If 
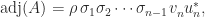
where 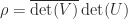


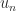
The definition of adjoint in the Symbolic Math Toolbox) uses the SVD formula.
function X = adj(A)
%ADJ Adjugate of a matrix.
% X = ADJ(A) computes the adjugate of the square matrix A via
% the singular value decomposition.
n = length(A);
[U,S,V] = svd(A);
D = zeros(n);
for i=1:n
d = diag(S);
d(i) = 1;
D(i,i) = prod(d);
end
X = conj(det(V))*det(U)*V*D*U';
Note that, in common with most SVD codes, the svd function does not return 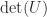

Finally, we note that Richter (1954) and Mirsky (1956) obtained the Frobenius norm bound
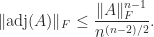
References
This is a minimal set of references, which contain further useful references within.
- Roger A. Horn and Charles R. Johnson, Matrix Analysis, second edition, Cambridge University Press, 2013. Section 0.8.2.
- L. Mirsky, The Norms of Adjugate and Inverse Matrices, Archiv der Mathematik 7(4), 276–277, 1956.
- Hans Richter, Bemerkung zur Norm der Inversen einer Matrix, Archiv der Mathematik 5, 447–448, 1954.
- G. W. Stewart, On the Adjugate Matrix, Linear Algebra Appl. 283, 151–164, 1998.
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
Update (August 10, 2020): added the second displayed equation.

Thanks for the post! A minor typo: in the sentence “If rank(A)=n-1 then the only nonzero singular value is \sigma_n”, “nonzero” should read “zero”.
Thanks – corrected.
Dear Professor Nick
1.Thank you very much for the post about the adjugate matrices . It is wonderful and useful and it opens the doors for additional research.
2. It would be great if you write a post ” what is Skew-Hermitian matrices and their properties ”
BEST WISHES and THANKS.