A QR factorization of a rectangular matrix 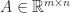
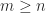

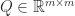
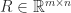

![R = \left[\begin{smallmatrix}R_1\\ 0\end{smallmatrix}\right]](https://s0.wp.com/latex.php?latex=R+%3D+%5Cleft%5B%5Cbegin%7Bsmallmatrix%7DR_1%5C%5C+0%5Cend%7Bsmallmatrix%7D%5Cright%5D&bg=ffffff&fg=222222&s=0&c=20201002)



![\notag A = QR = \begin{array}[b]{@{\mskip-20mu}c@{\mskip0mu}c@{\mskip-1mu}c@{}} & \mskip10mu\scriptstyle n & \scriptstyle m-n \\ \mskip15mu \begin{array}{r} \scriptstyle m \end{array}~ & \multicolumn{2}{c}{\mskip-15mu \left[\begin{array}{c@{~}c@{~}} Q_1 & Q_2 \end{array}\right] } \end{array} \mskip-10mu \begin{array}[b]{@{\mskip-25mu}c@{\mskip-20mu}c@{}} \scriptstyle n \\ \multicolumn{1}{c}{ \left[\begin{array}{@{}c@{}} R_1\\ 0 \end{array}\right]} & \mskip-12mu\ \begin{array}{l} \scriptstyle n \\ \scriptstyle m-n \end{array} \end{array} = Q_1 R_1.](https://s0.wp.com/latex.php?latex=%5Cnotag++++A+%3D+QR+++++%3D++++%5Cbegin%7Barray%7D%5Bb%5D%7B%40%7B%5Cmskip-20mu%7Dc%40%7B%5Cmskip0mu%7Dc%40%7B%5Cmskip-1mu%7Dc%40%7B%7D%7D++++%26+%5Cmskip10mu%5Cscriptstyle+n+%26+%5Cscriptstyle+m-n++%5C%5C+++++++%5Cmskip15mu++++++++++%5Cbegin%7Barray%7D%7Br%7D++++++++++++++%5Cscriptstyle+m++++++++++%5Cend%7Barray%7D%7E++++%26+++++++%5Cmulticolumn%7B2%7D%7Bc%7D%7B%5Cmskip-15mu++++++++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%40%7B%7E%7Dc%40%7B%7E%7D%7D++++++++++++++++++Q_1+%26+Q_2++++++++++++++++%5Cend%7Barray%7D%5Cright%5D+++++++%7D++++%5Cend%7Barray%7D+%5Cmskip-10mu++++%5Cbegin%7Barray%7D%5Bb%5D%7B%40%7B%5Cmskip-25mu%7Dc%40%7B%5Cmskip-20mu%7Dc%40%7B%7D%7D++++%5Cscriptstyle+n++++%5C%5C++++%5Cmulticolumn%7B1%7D%7Bc%7D%7B++++++++%5Cleft%5B%5Cbegin%7Barray%7D%7B%40%7B%7Dc%40%7B%7D%7D++++++++++++++++++R_1%5C%5C++++++++++++++++++0++++++++++++++%5Cend%7Barray%7D%5Cright%5D%7D++++%26+%5Cmskip-12mu%5C++++++++++%5Cbegin%7Barray%7D%7Bl%7D++++++++++++++%5Cscriptstyle+n+%5C%5C++++++++++++++%5Cscriptstyle+m-n++++++++++%5Cend%7Barray%7D++++%5Cend%7Barray%7D++++%3D+Q_1+R_1.+&bg=ffffff&fg=222222&s=0&c=20201002)
There are therefore two forms of QR factorization:
is the reduced (also called economy-sized, or thin) QR factorization.
To prove the existence of a QR factorization note that if 
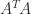
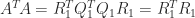
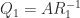


Therefore when 

When 
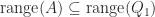
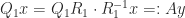
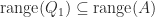
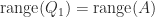

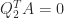

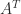
The QR factorization provides a way of orthonormalizing the columns of a matrix. An alternative is provided by the polar decomposition 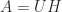


There are three standard ways of computing a QR factorization.
Gram–Schmidt orthogonalization computes the reduced factorization. It has the disadvantage that in floating-point arithmetic the computed 

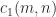

Householder QR factorization and Givens QR factorization both construct 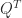

![\notag \qquad\qquad\qquad\qquad A^{(k)} = Q_{k-1}^T A = \begin{array}[b]{@{\mskip35mu}c@{\mskip20mu}c@{\mskip-5mu}c@{}c} \scriptstyle k-1 & \scriptstyle 1 & \scriptstyle n-k & \\ \multicolumn{3}{c}{ \left[\begin{array}{c@{\mskip10mu}cc} R_{k-1} & y_k & B_k \\ 0 & z_k & C_k \end{array}\right]} & \mskip-12mu \begin{array}{c} \scriptstyle k-1 \\ \scriptstyle m-k+1 \end{array} \end{array}, \qquad\qquad\qquad\qquad (*)](https://s0.wp.com/latex.php?latex=%5Cnotag+++%5Cqquad%5Cqquad%5Cqquad%5Cqquad++++A%5E%7B%28k%29%7D+%3D+Q_%7Bk-1%7D%5ET+A+%3D++++%5Cbegin%7Barray%7D%5Bb%5D%7B%40%7B%5Cmskip35mu%7Dc%40%7B%5Cmskip20mu%7Dc%40%7B%5Cmskip-5mu%7Dc%40%7B%7Dc%7D++++%5Cscriptstyle+k-1+%26++++%5Cscriptstyle+1+%26++++%5Cscriptstyle+n-k+%26++++%5C%5C++++%5Cmulticolumn%7B3%7D%7Bc%7D%7B++++%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%40%7B%5Cmskip10mu%7Dcc%7D++++R_%7Bk-1%7D+%26+y_k++%26+B_k+%5C%5C++++++++0+++%26+z_k++%26+C_k++++%5Cend%7Barray%7D%5Cright%5D%7D++++%26+%5Cmskip-12mu++++%5Cbegin%7Barray%7D%7Bc%7D++++%5Cscriptstyle+k-1+%5C%5C++++%5Cscriptstyle+m-k%2B1++++%5Cend%7Barray%7D++++%5Cend%7Barray%7D%2C+++%5Cqquad%5Cqquad%5Cqquad%5Cqquad+%28%2A%29+&bg=ffffff&fg=222222&s=0&c=20201002)
where 
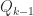
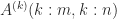

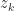
Householder QR factorization is the method of choice for general matrices, but Givens QR factorization is preferred for structured matrices with a lot of zeros, such as upper Hessenberg matrices and tridiagonal matrices.
Both these methods produce 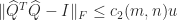
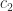
Modified Gram–Schmidt, Householder QR, and Givens QR all have the property that there exists an exactly orthogonal 
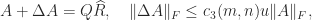
for some constant 
Another way of computing a QR factorization is by the technique in the existence proof above, via Cholesky factorization of 
Column Pivoting and Rank-Revealing QR Factorization
In practice, we often want to compute a basis for the range of 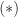



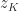




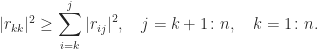
In particular,

If

with 
Near rank deficiency of
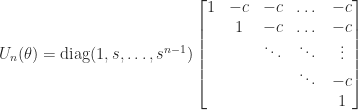
where 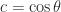
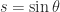

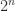
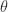
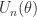
In practice, column pivoting reduces the efficiency of Householder QR factorization because it limits the amount of the computation that can be expressed in terms of matrix multiplication. This has motivated the development of methods that select the pivot columns using randomized projections. These methods gain speed and produce factorizations of similar rank-revealing quality, though they give up the inequalities 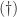
It is known that at least one permutation matrix 
References
This is a minimal set of references, which contain further useful references within.
- Shivkumar Chandrasekaran and Ilse Ipsen, On Rank-Revealing Factorisations, SIAM J. Matrix Anal. Appl. 15(2), 592–622, 1994.
- Per-Gunnar Martinsson and Joel A. Tropp, Randomized Numerical Linear Algebra: Foundations and Algorithms, Acta Numerica, 2020, to appear.
- Nicholas J. Higham, Accuracy and Stability of Numerical Algorithms, second edition, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2002.
- Takeshi Fukaya, Ramaseshan Kannan, Yuji Nakatsukasa, Yusaku Yamamoto and Yuka Yanagisawa, Shifted Cholesky QR for Computing the QR Factorization of Ill-Conditioned Matrices, SIAM J. Sci. Comput. 42(1), A477–A503, 2020.
Related Blog Posts
- What Is a Householder Matrix? (2020)
- What Is an Orthogonal Matrix? (2020)
- What is the Polar Decomposition? (2020)
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
