The logarithmic norm of a matrix 
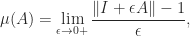
where the norm is assumed to satisfy 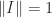
Note that the limit is taken from above. If we take the limit from below then we obtain a generally different quantity: writing 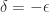
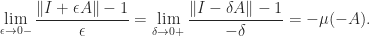
The logarithmic norm is not a matrix norm; indeed it can be negative: 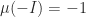
The logarithmic norm can also be expressed in terms of the matrix exponential.
Lemma 1. For
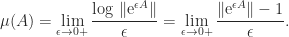
Properties
We give some basic properties of the logarithmic norm.
It is easy to see that
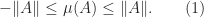
For 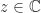
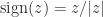
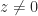

Lemma 2. For
and
,
,
,
,
.
The next result shows the crucial property that 

Theorem 3. For
Moreover,
Proof. Given any
, by Lemma 1 there exists
such that
or
(since
for all
). Then for any integer
,
, and hence
holds for all
. Since
is arbitrary, it follows that
.
Finally, if
for all
then
for all
and taking
we conclude that
.
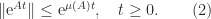

![\notag \displaystyle\frac{ \| \mathrm{e}^{At}\| - 1}{t} - \mu(A) < \delta, \quad t\in[0,h],](https://s0.wp.com/latex.php?latex=%5Cnotag+++++%5Cdisplaystyle%5Cfrac%7B+%5C%7C+%5Cmathrm%7Be%7D%5E%7BAt%7D%5C%7C+-+1%7D%7Bt%7D+-+%5Cmu%28A%29+%3C+%5Cdelta%2C+++++%5Cquad+t%5Cin%5B0%2Ch%5D%2C+&bg=ffffff&fg=222222&s=0&c=20201002)
![\notag \| \mathrm{e}^{At}\| \le 1 + (\mu(A) + \delta)t \le \mathrm{e}^{(\mu(A) + \delta)t}, \quad t\in[0,h]](https://s0.wp.com/latex.php?latex=%5Cnotag+++++%5C%7C+%5Cmathrm%7Be%7D%5E%7BAt%7D%5C%7C+%5Cle+1+%2B+%28%5Cmu%28A%29+%2B+%5Cdelta%29t+++++++++%5Cle+%5Cmathrm%7Be%7D%5E%7B%28%5Cmu%28A%29+%2B+%5Cdelta%29t%7D%2C+++++%5Cquad+t%5Cin%5B0%2Ch%5D+&bg=ffffff&fg=222222&s=0&c=20201002)
The logarithmic norm was introduced by Dahlquist (1958) and Lozinskii (1958) in order to obtain error bounds for numerical methods for solving differential equations. The bound (2) can alternatively be proved by using differential inequalities (see Söderlind (2006)). Not only is (2) sharper than 
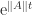

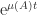

The spectral abscissa is defined by
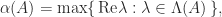
where 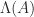

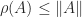
Theorem 4. For
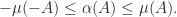
Combining (1) with (2) gives

In view of Lemma 1, the logarithmic norm 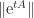
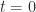
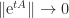
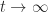
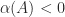
The next result provides a bound on the norm of the inverse of a matrix in terms of the logarithmic norm.
Theorem 5. For a nonsingular matrix
then

Formulas for Logarithmic Norms
Explicit formulas are available for the logarithmic norm s corresponding to the 


Theorem 6. For
where
denotes the largest eigenvalue of a Hermitian matrix.
Proof. We have
The formula for
follows, since
implies
. For the
, we have
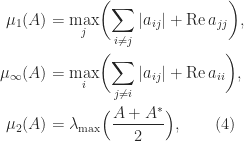
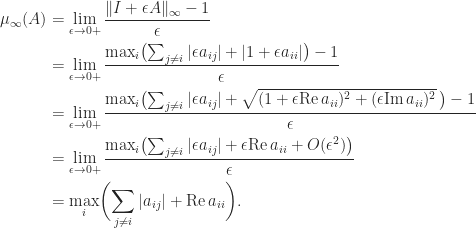

As a special case of (4), if 

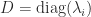

We can make some observations about 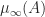

- If
then
.
if and only if
for all
and
- For the
For a numerical example, consider the 
anymatrix('gallery/lesp'), which has the form illustrated for 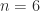
![\notag A_6 = \left[\begin{array}{cccccc} -5 & 2 & 0 & 0 & 0 & 0\\ \frac{1}{2} & -7 & 3 & 0 & 0 & 0\\ 0 & \frac{1}{3} & -9 & 4 & 0 & 0\\ 0 & 0 & \frac{1}{4} & -11 & 5 & 0\\ 0 & 0 & 0 & \frac{1}{5} & -13 & 6\\ 0 & 0 & 0 & 0 & \frac{1}{6} & -15 \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cnotag+++++A_6+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcccccc%7D++++++-5+%26+2+%26+0+%26+0+%26+0+%26+0%5C%5C++++++%5Cfrac%7B1%7D%7B2%7D+%26+-7+%26+3+%26+0+%26+0+%26+0%5C%5C++++++0+%26+%5Cfrac%7B1%7D%7B3%7D+%26+-9+%26+4+%26+0+%26+0%5C%5C++++++0+%26+0+%26+%5Cfrac%7B1%7D%7B4%7D+%26+-11+%26+5+%26+0%5C%5C++++++0+%26+0+%26+0+%26+%5Cfrac%7B1%7D%7B5%7D+%26+-13+%26+6%5C%5C++++++0+%26+0+%26+0+%26+0+%26+%5Cfrac%7B1%7D%7B6%7D+%26+-15++++++%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
We find that 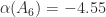
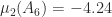



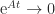
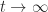

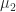
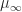
Now consider the subordinate matrix norm 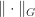
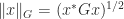

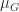
Theorem 7. For

Theorem 7 allows us to make a connection with the theory of ordinary differential equations (ODEs)
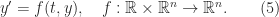
Let 
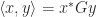
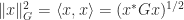
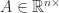

The function 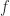

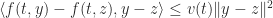
for all 
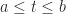
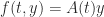
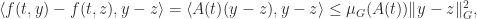
and so the logarithmic norm 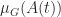
Notes
For more on the use of the logarithmic norm in differential equations see Coppel (1965) and Söderlind (2006).
The proof of Theorem 3 is from Hinrichsen and Pritchard (2005).
References
This is a minimal set of references, which contain further useful references within.
- W. A. Coppel, Stability and Asymptotic Behavior of Differential Equations}. D. C. Heath and Company, Boston, MA. USA, 1965.
- Germund Dahlquist. Stability and Error Bounds in the Numerical Integration of Ordinary Differential Equations. PhD thesis, Royal Inst. of Technology, Stockholm, Sweden, 1958.
- Diederich Hinrichsen and Anthony J. Pritchard. Mathematical Systems Theory I. Modelling, State Space Analysis, Stability and Robustness. Springer-Verlag, Berlin, Germany, 2005.
- J. D. Lambert. Numerical Methods for Ordinary Differential Systems. The Initial Value Problem. John Wiley, Chichester, 1991.
- Gustaf Söderlind, The Logarithmic Norm. History and Modern Theory. BIT, 46(3):631–652, 2006.
- Torsten Ström. On Logarithmic Norms. SIAM J. Numer. Anal., 12(5):741–753, 1975.
Related Blog Posts
- Anymatrix: An Extensible MATLAB Matrix Collection (2021)
- What is a Diagonally Dominant Matrix? (2021)
- What Is a Matrix Norm? (2021)
This article is part of the “What Is” series, available from https://nhigham.com/index-of-what-is-articles/ and in PDF form from the GitHub repository https://github.com/higham/what-is.
