A sparse matrix is one with a large number of zero entries. A more practical definition is that a matrix is sparse if the number or distribution of the zero entries makes it worthwhile to avoid storing or operating on the zero entries.
Sparsity is not to be confused with data sparsity, which refers to the situation where, because of redundancy, the data can be efficiently compressed while controlling the loss of information. Data sparsity typically manifests itself in low rank structure, whereas sparsity is solely a property of the pattern of nonzeros.
Important sources of sparse matrices include discretization of partial differential equations, image processing, optimization problems, and networks and graphs. In designing algorithms for sparse matrices we have several aims.
- Store the nonzeros only, in some suitable data structure.
- Avoid operations involving only zeros.
- Preserve sparsity, that is, minimize fill-in (a zero element becoming nonzero).
We wish to achieve these aims without sacrificing speed, stability, or reliability.
An important class of sparse matrices is banded matrices. A matrix 

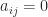
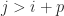

The most common type of banded matrix is a tridiagonal matrix 
![\notag A_5 = \left[ \begin{array}{@{}*{4}{r@{\mskip10mu}}r} 2 & -1 & 0 & 0 & 0\\ -1 & 2 & -1 & 0 & 0\\ 0 & -1 & 2 & -1 & 0\\ 0 & 0 &-1 & 2 & -1\\ 0 & 0 & 0 & -1 & 2 \end{array}\right].](https://s0.wp.com/latex.php?latex=%5Cnotag++++A_5+%3D+%5Cleft%5B++++%5Cbegin%7Barray%7D%7B%40%7B%7D%2A%7B4%7D%7Br%40%7B%5Cmskip10mu%7D%7Dr%7D+++++++++++++++++2+%26++-1++%26+0++%26+0+%26+0%5C%5C+++++++++++++++++-1+%26+2++%26+-1++%26+0+%26+0%5C%5C++++++++++++++++++0+%26+-1++%26+2+%26+-1+%26+0%5C%5C++++++++++++++++++0+%26++0++%26-1+%26+2++%26+-1%5C%5C++++++++++++++++++0+%26++0++%26+0+%26+-1+%26+2++++%5Cend%7Barray%7D%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
This matrix (or more precisely its negative) corresponds to a centered finite difference approximation to a second derivative: 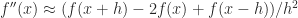
The following plots show the sparsity patterns for two symmetric positive definite matrices. Here, the nonzero elements are indicated by dots.
 The matrices are both from power network problems and they are taken from the SuiteSparse Matrix Collection (
The matrices are both from power network problems and they are taken from the SuiteSparse Matrix Collection (https://sparse.tamu.edu/). The matrix names are shown in the titles and the nz values below the 
W = ssget('HB/494_bus'); A = W.A; spy(A)
where the ssget function is provided with the collection. The matrix on the left shows no particular pattern for the nonzero entries, while that on the right has a structure comprising four diagonal blocks with a relatively small number of elements connecting the blocks.
It is important to realize that while the sparsity pattern often reflects the structure of the underlying problem, it is arbitrary in that it will change under row and column reorderings. If we are interested in solving 


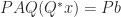





For the HB/494_bus matrix the symmetric reverse Cuthill-McKee permutation gives a reordered matrix with the following sparsity pattern, plotted with the MATLAB commands
r = symrcm(A); spy(A(r,r))

The reordered matrix with a variable band structure that is characteristic of the symmetric reverse Cuthill-McKee permutation. The number of nonzeros is, of course, unchanged by reordering, so what has been gained? The next plots show the Cholesky factors of the HB/494_bus matrix and the reordered matrix. The Cholesky factor for the reordered matrix has a much narrower bandwidth than that for the original matrix and has fewer nonzeros by a factor 3. Reordering has greatly reduced the amount of fill-in that occurs; it leads to a Cholesky factor that is cheaper to compute and requires less storage.

Because Cholesky factorization is numerically stable, the matrix can be permuted without affecting the numerical stability of the computation. For a nonsymmetric problem the choice of row and column interchanges also needs to take into account the need for numerical stability, which complicates matters.
The world of sparse matrix computations is very different from that for dense matrices. In the first place, sparse matrices are not stored as 

While it is always true that one should not solve 
Finally, we mention an interesting property of 


This property generalizes to other tridiagonal matrices. So while a tridiagonal matrix is sparse, its inverse is data sparse—as it has to be because in general 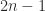


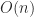
References
This is a minimal set of references, which contain further useful references within.
- Timothy A. Davis, Direct Methods for Sparse Linear Systems, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2006.
- Timothy A. Davis, Sivasankaran Rajamanickam, and Wissam M. Sid-Lakhdar, A Survey of Direct Methods for Sparse Linear Systems, Acta Numerica 25, 383–566, 2016.
- Timothy A. Davis and Yifan Hu, The University of Florida Sparse Matrix Collection, ACM Trans. Math. Software 38 (1), 1:1–1:25, 2011. Note: this collection is now called the SuiteSparse Matrix Collection.
- Gareth I. Hargreaves, Computing the Condition Number of Tridiagonal and Diagonal-Plus-Semiseparable Matrices in Linear Time, SIAM J. Matrix Anal. Appl. 27, 801–820, 2006.
- Gérard Meurant, A Review on the Inverse of Symmetric Tridiagonal and Block Tridiagonal Matrices, SIAM J. Matrix Anal. Appl. 13, 707–728, 1992.
- Yousef Saad, Iterative Methods for Sparse Linear Systems, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2003.
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
