A matrix norm is a function 
with equality if and only if
(nonnegativity),
for all
,
(homogeneity),
for all
(the triangle inequality).
These are analogues of the defining properties of a vector norm.
An important class of matrix norms is the subordinate matrix norms. Given a vector norm on 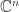


or, equivalently,
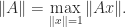
For the 



where 




An immediate implication of the definition of subordinate matrix norm is that

whenever the product is defined. A norm satisfying this condition is called consistent or submultiplicative.
Another commonly used norm is the Frobenius norm,

The Frobenius norm is not subordinate to any vector norm (since 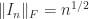
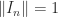
The 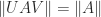


As for vector norms, all matrix norms are equivalent in that any two norms differ from each other by at most a constant. This table shows the optimal constants 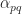

For any 
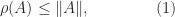
where 
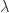

![X=[x,x,\dots,x] \in \mathbb{C}^{n\times n}](https://s0.wp.com/latex.php?latex=X%3D%5Bx%2Cx%2C%5Cdots%2Cx%5D+%5Cin+%5Cmathbb%7BC%7D%5E%7Bn%5Ctimes+n%7D&bg=ffffff&fg=222222&s=0&c=20201002)
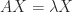

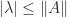
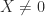
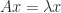
A useful relation is
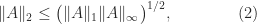
which follows from 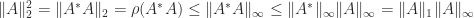
Mixed Subordinate Matrix Norms
A more general subordinate matrix norm can be defined by taking different vector norms in the numerator and denominator:
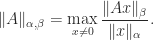
Some authors denote this norm by 
A useful characterization of 


Theorem 1. For
Proof. We have
where the second equality follows from the definition of dual vector norm and the fact that the dual of the dual norm is the original norm.

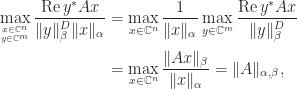
We can now obtain a connection between the norms of 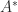
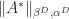
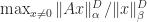
Theorem 2. If
.
Proof. Using Theorem 1, we have
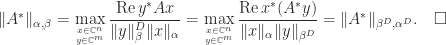
If we take the 
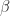

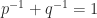
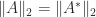

Now we give explicit formulas for the 
Theorem 3. For
For
,
where
and if
Proof. For (3),
with equality for
, where the maximum is attained for
. For (4), using the Hölder inequality,
Equality is attained for an
th row of
.
Turning to (5), we have
. The unit cube
, where
, is a convex polyhedron, so any point within it is a convex combination of the vertices, which are the elements of
. Hence
implies
and then
Hence
, but trivially
and (5) follows.
Finally, if
. Then, using a Cholesky factorization
(which exists even if
Conversely, for
we have
so
. Hence
, using (5).
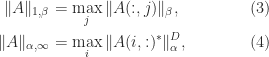

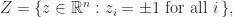




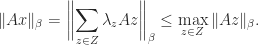

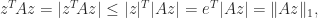

As special cases of (3) and (4) we have
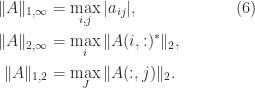
We also obtain by using Theorem 2 and (5), for

The 

the 
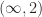

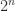

The (
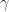
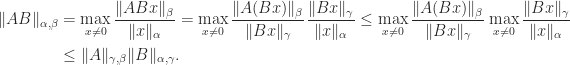
Matrices With Constant -Norms
Let 




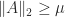
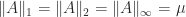
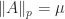
![p\in[1,\infty]](https://s0.wp.com/latex.php?latex=p%5Cin%5B1%2C%5Cinfty%5D&bg=ffffff&fg=222222&s=0&c=20201002)
Computing Norms
The problem of computing or estimating 

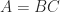

Let us focus on the case where pnorm and we use it here to estimate the 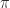
>> A = gallery('frank',4)
A =
4 3 2 1
3 3 2 1
0 2 2 1
0 0 1 1
>> [norm(A,1) norm(A,2) pnorm(A,pi), pnorm(A,99), norm(A,inf)]
ans =
8.0000e+00 7.6237e+00 8.0714e+00 9.8716e+00 1.0000e+01
The plot in the top half of the following figure shows the estimated gallery('binomial',8) for ![p \in[1,25]](https://s0.wp.com/latex.php?latex=p+%5Cin%5B1%2C25%5D&bg=ffffff&fg=222222&s=0&c=20201002)
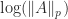

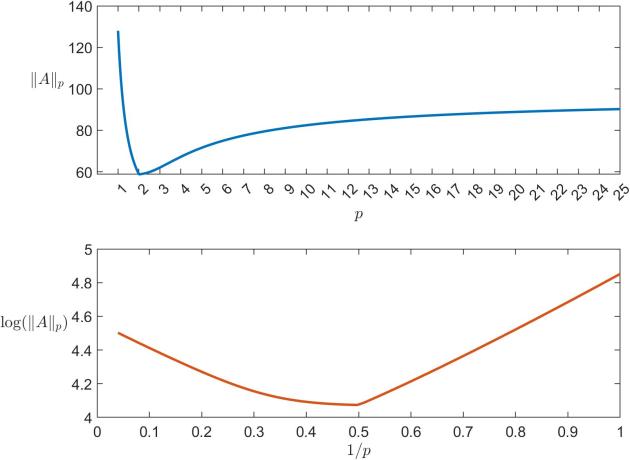
The power method for the 
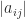
A Norm Related to Grothendieck’s Inequality
A norm on 
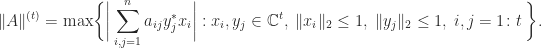
Note that

A famous inequality of Grothendieck states that 

![[1.33,1.41]](https://s0.wp.com/latex.php?latex=%5B1.33%2C1.41%5D&bg=ffffff&fg=222222&s=0&c=20201002)
![[1.67,1.79]](https://s0.wp.com/latex.php?latex=%5B1.67%2C1.79%5D&bg=ffffff&fg=222222&s=0&c=20201002)
Notes
The formula (5) with 
Computing mixed subordinate matrix norms based on
References
This is a minimal set of references, which contain further useful references within.
- Joshua Cape, Minh Tang, and Carey Priebe, The Two-To-Infinity Norm and Singular Subspace Geometry with Applications to High-Dimensional Statistics, Ann. Statist. 47(5), 2405–2439, 2019.
- Shmuel Friedland, Lek-Heng Lim and Jinjie Zhang, An Elementary and Unified Proof of Grothendieck’s Inequality, L’Enseignement Mathématique 64 (3), 327–351, 2018.
- Julien Hendrickx and Alex Olshevsky, Matrix
, SIAM J. Matrix Anal. Appl. 31(5), 2802–2812, 2010.
- Nicholas J. Higham, Accuracy and Stability of Numerical Algorithms, second edition, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2002.
- Nicholas J. Higham and Samuel Relton, Estimating the Largest Elements of a Matrix, SIAM J. Sci. Comput. 38(5), C584–C601, 2016,
- Andrew D. Lewis, A Top Nine List: Most Popular Induced Matrix Norms, Manuscript, 2010.
- E. Rebrova and R. Vershynin, Norms of Random Matrices: Local and Global Problems, Adv. Math. 324, 40–83, 2018.
- Josef Stoer and C. Witzgall, Transformations by Diagonal Matrices in a Normed Space, Numer. Math. 4(1), 158–171, 1962.
Related Blog Posts
- What Is a Unitarily Invariant Norm? (2021)
- What Is a Vector Norm? (2021)
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.

Thanks, Nick, this is a great summary!
Sir, how could we compute L-1/L-infinity Mixed induced matrix norms?
By (3) it is $\max_{i,j} |a_{ij}|$.