A real matrix is nonnegative if all its elements are nonnegative and it is positive if all its elements are positive. Nonnegative matrices arise in a wide variety of applications, for example as matrices of probabilities in Markov processes and as adjacency matrices of graphs. Information about the eigensystem is often essential in these applications.
Perron (1907) proved results about the eigensystem of a positive matrix and Frobenius (1912) extended them to nonnegative matrices.
The following three results of increasing specificity summarize the key spectral properties of nonnegative matrices proved by Perron and Frobenius. Recall that a simple eigenvalue of an 


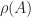

Theorem 1. (Perron–Frobenius) If
is nonnegative then
- there is a nonnegative eigenvector
such that
.
A matrix 

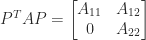
where 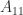
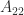
Theorem 2. (Perron–Frobenius) If
,
- there is a positive eigenvector
,
Theorem 3. (Perron) If
for any eigenvalue
with
.
For nonnegative, irreducible 
It is a good exercise to apply the theorems to all binary 
: Theorem 1 says that
is an eigenvalue and and that it has a nonnegative eigenvector. Indeed
is an eigenvector. Note that
is a repeated eigenvalue.
:
and
is the Perron vector for the Perron root
: Theorem 3 says that
is an eigenvalue with positive eigenvector and that the other eigenvalue has modulus less than
. Indeed the eigenvalues are the Perron root
For another example, consider the irreducible matrix

Note that 
![[1~1~1]^T/3](https://s0.wp.com/latex.php?latex=%5B1%7E1%7E1%5D%5ET%2F3&bg=ffffff&fg=222222&s=0&c=20201002)
A stochastic matrix is a nonnegative matrix whose row sums are all equal to 
![e = [1,1,\dots,1]^T](https://s0.wp.com/latex.php?latex=e+%3D+%5B1%2C1%2C%5Cdots%2C1%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002)

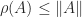

The next result is easily proved using Theorem 3 together with the Jordan canonical form. It shows that the powers of a positive matrix behave like multiples of a rank-1 matrix.
Theorem 4. If
is the Perron vector of
then
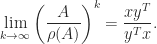
Note that 
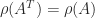
If 
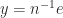
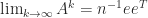
>> n = 4; M = magic(n), A = M/sum(M(1,:)) % Doubly stochastic matrix.
A =
16 2 3 13
5 11 10 8
9 7 6 12
4 14 15 1
A =
4.7059e-01 5.8824e-02 8.8235e-02 3.8235e-01
1.4706e-01 3.2353e-01 2.9412e-01 2.3529e-01
2.6471e-01 2.0588e-01 1.7647e-01 3.5294e-01
1.1765e-01 4.1176e-01 4.4118e-01 2.9412e-02
>> for k = 8:8:32, fprintf('%11.2e',norm(A^k-ones(n)/n,1)), end, disp(' ')
3.21e-05 7.37e-10 1.71e-14 8.05e-16
References
This is a minimal set of references, which contain further useful references within.
- Roger A. Horn and Charles R. Johnson, Matrix Analysis, second edition, Cambridge University Press, 2013. Chapter 8. My review of the second edition.
- Carl D. Meyer, Matrix Analysis and Applied Linear Algebra, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2000. Chapter 8.
- Helene Shapiro, Linear Algebra and Matrices. Topics for a Second Course, American Mathematical Society, Providence, RI, USA, 2015. Chapter 17.
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.

Hi, and thanks for the nice post. example: “…eigenvector and that the other eigenvalue has modulus less than 1” I think you meant to write “less than 2”.
example: “…eigenvector and that the other eigenvalue has modulus less than 1” I think you meant to write “less than 2”.
In the
Thanks – corrected.
I am hoping PFT will help prove a seemingly simple thing:
For square non negative Q with spectral radius < 1, (I hope that)
(I + Q)^{-1}Q is also non negative.
Any hints or thoughts?
It’s false. Here is a counterexample in MATLAB:
>> rng(6); n=2; A = rand(n)/(1.1*max(abs(eig(A)))); (eye(n)+A)\A
ans =
2.3058e-01 2.3561e-01
9.5246e-02 -1.3619e-02
With a change of sign, (I-Q)^{-1}Q is nonnegative, as can be seen
from a Neumann expansion of the inverse.
thanks. now I see why I couldn’t prove it. I will have to think if I really need it.