Recall that the singular value decomposition (SVD) of a matrix 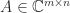
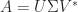
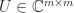
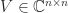
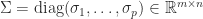
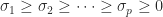

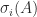
A standard technique for obtaining singular value inequalities for 
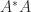
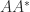
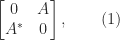
whose eigenvalues are plus and minus the singular values of 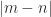
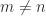
We begin with a variational characterization of singular values.
Theorem 1. For
,
where
.
Proof. The result is obtained by applying the Courant–Fischer theorem (a variational characterization of eigenvalues) to
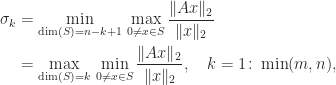

As a special case of Theorem 1, we have
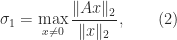
and, for 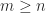

The expression in the theorem can be rewritten using 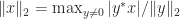
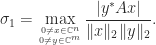
Our first perturbation result bounds the change in a singular value.
Theorem 2. For
,
Proof. The bound is obtained by applying the corresponding result for the Hermitian eigenvalue problem to (1).
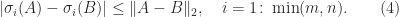
The bound (4) says that the singular values of a matrix are well conditioned under additive perturbation. Now we consider multiplicative perturbations.
The next result is an analogue for singular values of Ostrowski’s theorem for eigenvalues.
Theorem 3. For
and nonsingular
and
,
where
.
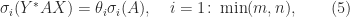
A corollary of this result is
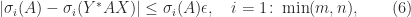
where 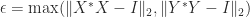

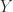
Next, we have an interlacing property.
Theorem 4. Let
, and
. Then
where we define
if
.
Proof. The result is obtained by applying the Cauchy interlace theorem to
is the leading principal submatrix of order
of
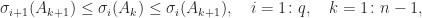
An analogous result holds with rows playing the role of columns (just apply Theorem 4 to 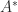
Theorem 4 encompasses two different cases, which we illustrate with 
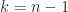

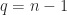
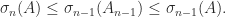
The second case is 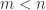
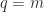

Therefore Theorem 3 shows that removing a column from 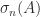
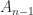
Here is a numerical example. Note that transposing
>> rng(1), A = rand(5,4); % Case 1. >> B = A(:,1:end-1); sv_A = svd(A)', sv_B = svd(B)' sv_A = 1.7450e+00 6.4492e-01 5.5015e-01 3.2587e-01 sv_B = 1.5500e+00 5.8472e-01 3.6128e-01 > A = A'; B = A(:,1:end-1); sv_B = svd(B)' % Case 2 sv_B = 1.7098e+00 6.0996e-01 4.6017e-01 1.0369e-01
By applying Theorem 4 repeatedly we find that if we partition ![A = [A_{11}~A_{12}]](https://s0.wp.com/latex.php?latex=A+%3D+%5BA_%7B11%7D%7EA_%7B12%7D%5D&bg=ffffff&fg=222222&s=0&c=20201002)
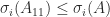

References
- Roger A. Horn and Charles R. Johnson, Matrix Analysis, second edition, Cambridge University Press, 2013. My review of the second edition.
- Ilse Ipsen, Relative Perturbation Results for Matrix Eigenvalues and Singular Values, Acta Numerica 7, 151–201, 1998.

Hi Prof! Where can I find the elaborate proof of Theorem 3 and how can I cite this work?
The reference for Theorem 3 is Stanley C. Eisenstat and Ilse C. F. Ipsen,Relative Perturbation Techniques for Singular Value Problems,https://epubs.siam.org/doi/10.1137/0732088. If you want to cite this blog post you can use this BibTeX entry:
@misc{high21s,
author = “Nicholas J. Higham”,
title = “Singular Value Inequalities”,
year = 2021,
month = may,
howpublished = “\url{https://nhigham.com/2021/05/04/singular-value-inequalities/}”
}
I see. Thanks for your time!