
The 2008 revision of the IEEE Standard for Floating-Point Arithmetic introduced a half precision 16-bit floating point format, known as fp16, as a storage format. Various manufacturers have adopted fp16 for computation, using the obvious extension of the rules for the fp32 (single precision) and fp64 (double precision) formats. For example, fp16 is supported by the NVIDIA P100 and V100 GPUs and the AMD Radeon Instinct MI25 GPU, as well as the A64FX Arm processor that will power the Fujitsu Post-K exascale computer.
Bfloat16
Fp16 has the drawback for scientific computing of having a limited range, its largest positive number being 
The allocation of bits to the exponent and significand for bfloat16, fp16, and fp32 is shown in this table, where the implicit leading bit of a normalized number is counted in the significand.
| Format | Significand | Exponent |
|---|---|---|
| bfloat16 | 8 bits | 8 bits |
| fp16 | 11 bits | 5 bits |
| fp32 | 24 bits | 8 bits |
Bfloat16 has three fewer bits in the significand than fp16, but three more in the exponent. And it has the same exponent size as fp32. Consequently, converting from fp32 to bfloat16 is easy: the exponent is kept the same and the significand is rounded or truncated from 24 bits to 8; hence overflow and underflow are not possible in the conversion.
On the other hand, when we convert from fp32 to the much narrower fp16 format overflow and underflow can readily happen, necessitating the development of techniques for rescaling before conversion—see the recent EPrint Squeezing a Matrix Into Half Precision, with an Application to Solving Linear Systems by me and Sri Pranesh.
The drawback of bfloat16 is its lesser precision: essentially 3 significant decimal digits versus 4 for fp16. The next table shows the unit roundoff 
|
xmins | xmin | xmax | |
|---|---|---|---|---|
| bfloat16 | 3.91e-03 | (*) | 1.18e-38 | 3.39e+38 |
| fp16 | 4.88e-04 | 5.96e-08 | 6.10e-05 | 6.55e+04 |
| fp32 | 5.96e-08 | 1.40e-45 | 1.18e-38 | 3.40e+38 |
(*) Unlike the fp16 format, Intel’s bfloat16 does not support subnormal numbers. If subnormal numbers were supported in the same way as in IEEE arithmetic, xmins would be 9.18e-41.
The values in this table (and those for fp64 and fp128) are generated by the MATLAB function float_params that I have made available on GitHub and at MathWorks File Exchange.
Harmonic Series
An interesting way to compare these different precisions is in summation of the harmonic series 
| Arithmetic | Computed Sum | Number of terms |
|---|---|---|
| bfloat16 |  |
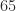 |
| fp16 |  |
 |
| fp32 |  |
 |
| fp64 | 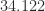 |
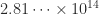 |
The differences are striking! I determined the first three values in MATLAB. The fp64 value is reported by Malone based on a computation that took 24 days, and he also gives analysis to estimate the limiting sum and corresponding number of terms for fp64.
Fused Multiply-Add
The NVIDIA V100 has tensor cores that can carry out the computation D = C + A*B in one clock cycle for 4-by-4 matrices A, B, and C; this is a 4-by-4 fused multiply-add (FMA) operation. Moreover, C and D can be in fp32. The benefits that the speed and accuracy of the tensor cores can bring over plain fp16 is demonstrated in Harnessing GPU Tensor Cores for Fast FP16 Arithmetic to Speed up Mixed-Precision Iterative Refinement Solvers.
Intel’s bfloat16 format supports a scalar FMA d = c + a*b, where c and d are in fp32.
Conclusion
A few years ago we had just single precision and double precision arithmetic. With the introduction of fp16 and fp128 in the IEEE standard in 2008, and now bfloat16 by Google and Intel, the floating-point landscape is becoming much more interesting.

numpy has had float16 for many years. (Of course, Matlab ivory towers are high, and one might have overlooked it :-))
in [23]: import numpy as np
In [24]: s=np.float16(0)
In [25]: for k in range(1,1000): s=s+np.float16(1)/np.float16(k)
In [26]: s
Out[26]: 7.086
Hi! You might be interested in this: https://blogs.mathworks.com/cleve/2017/05/08/half-precision-16-bit-floating-point-arithmetic/
Yes – we’ve made good use of Cleve’s fp16 class, most recently in http://eprints.maths.manchester.ac.uk/2678/
Hi Nick,
Nice post – the “squeezing” paper looks very interesting. Your first link to that paper on the blog post is currently linking to a different eprint, though (the correct link is in your reply to Andrea Picciau).
Best regards,
George
Thanks, George – I fixed the link.
Here’s the Julia version of the harmonic sum fun:
We have a BFloat16 package in Julia, which can be installed from the Julia package prompt with:
(v1.0) pkg> add git@github.com:JuliaComputing/BFloat16s.jl.git
Then, the harmonic sum is:
function harmonic(T, steps)
h = zero(T)
o = one(T)
for s in 1:steps
h += o/T(s)
end
return h
end
And then replicating the table:
julia> using BFloat16s
julia> harmonic(BFloat16, 65)
BFloat16(5.0625)
julia> harmonic(Float16, 513)
Float16(7.086)
julia> harmonic(Float32, 2097152)
15.403683f0
With a small modification, I can make the Julia code type stable. Performance testing with 1000 iterations, BFloat16 is about 5x slower than Float64, but Float16 is significantly slower.
function harmonic(::Type{T}, steps) where T
h = zero(T)
o = one(T)
for s in 1:steps
h += o/T(s)
end
return h
end
julia> using BenchmarkTools, BFloat16s
julia> @benchmark harmonic(BFloat16, 1000)
minimum time: 5.525 μs (0.00% GC)
julia> @benchmark harmonic(Float64, 1000)
minimum time: 1.115 μs (0.00% GC)
julia> @benchmark harmonic(Float16, 1000)
minimum time: 35.979 μs (0.00% GC)
julia> @benchmark harmonic(Float32, 1000)
minimum time: 1.135 μs (0.00% GC)
`harmonic(steps) = reduce(+, (BFloat16(1)/BFloat16(i) for i=1:steps))`
gives me the same performance as your harmonic function. Love the performance of generators in Julia.
I’ve revised the harmonic sum test with the posit number format, a recently proposed alternative to the floating-point standard. Using 16bit posits the harmonic sum only converges after 1024 terms yet these number formats have a much wider dynamic range than fp16 has.
Read my blog article http://www.milank.de/the-harmonic-sum-with-posit for more info.
In short, I get the sum yields 7.0859 after 513 terms for fp16
julia> harmsum(Float16)
(7.0859375, 513)
However, for posits (either Posit16, which has one exponent bit or Posit16_2 which has two) the sum converges only after 1024 or 1025 terms.
julia> harmsum(Posit16)
(7.77734375, 1024)
julia> harmsum(Posit16_2)
(7.78125, 1025)
See also my more recent posts
https://nhigham.com/2020/06/02/what-is-bfloat16-arithmetic/ and
https://nhigham.com/2020/05/07/what-is-ieee-standard-arithmetic/
I don’t understand your comments about overflow and underflow not being possible in converting fp32 to bfloat16. If we have a fp32 that is the max finite number (exponent is 11111110 and significand is all 1’s), then when you convert to bfloat16 using “round to even” for significand bits, this will convert to bfloat16 infinity (i.e., overflow). Similarly, a fp32 denormal number will convert to a bfloat16 zero (i.e., underflow). At least that is how I see it.
You’re right. I was more careful in my wording in https://nhigham.com/2020/06/02/what-is-bfloat16-arithmetic/
What’s missing from this analysis are the correct values of those harmonic numbers, which can be computed with an arbitrary precision library like mpmath:
>>> import mpmath
>>> mpmath.harmonic(65)
mpf(‘4.7592755190903846’)
>>> mpmath.harmonic(513)
mpf(‘6.8184658522885142’)
>>> mpmath.harmonic(2097152)
mpf(‘15.133306695078945’)
>>> mpmath.harmonic(2.81e14)
mpf(‘33.846591450163828’)
The Malone paper you reference discusses the errors for float64 in great detail.