In numerical linear algebra a blocked algorithm organizes a computation so that it works on contiguous chunks of data. A blocked algorithm and the corresponding unblocked algorithm (with blocks of size 
A simple example of blocking is in computing an inner product 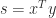

- for
-
- end
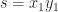
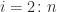

can be expressed in blocked form, with block size 
- for
-
% Compute by the unblocked algorithm.
- end


The sums of
To see the full benefits of blocking we need to consider an algorithm operating on matrices, of which matrix multiplication is the most important example. Suppose we wish to compute the product 



- for
- for
- for
-
- end
- end
- end


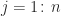

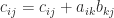
Let 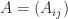
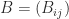
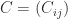

- for
- for
- for
-
- end
- end
- end

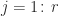


On a computer with a hierarchical memory the blocked form can be much more efficient than the point form if the blocks fit into the high speed memory, as much less data transfer is required. Indeed line 5 of the blocked algorithm performs 


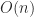
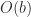
The LAPACK (first released in 1992) was the first program library to systematically use blocked algorithms for a wide range of linear algebra computations.
An extra advantage that blocked algorithms have over unblocked algorithms is a reduction in the error constant in a rounding error bound by a factor
The adjective “block” is sometimes used in place of “blocked”, but we prefer to reserve “block” for the meaning described in the next section.
Block Algorithms
A block algorithm is a generalization of a scalar algorithm in which the basic scalar operations become matrix operations (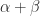

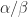

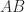

An example of a block factorization is block LU factorization. For a 
![\notag A = \left[ \begin{tabular}{cc|cc} 1 & & & \\ x & 1 & & \\ \hline x & x & 1 & \\ x & x & x & 1 \end{tabular} \right] \left[ \begin{tabular}{cc|cc} x & x & x & x \\ & x & x & x \\ \hline & & x & x \\ & & & x \end{tabular} \right].](https://s0.wp.com/latex.php?latex=%5Cnotag++++A+%3D++%5Cleft%5B+%5Cbegin%7Btabular%7D%7Bcc%7Ccc%7D++++++++++++++++++1+%26+++%26++++%26++++%5C%5C++++++++++++++++++x+%26+1+%26++++%26++++%5C%5C++%5Chline++++++++++++++++++x+%26+x+%26++1+%26++++%5C%5C++++++++++++++++++x+%26+x+%26++x+%26+1+++++++++++++++++%5Cend%7Btabular%7D++%5Cright%5D++++++%5Cleft%5B+%5Cbegin%7Btabular%7D%7Bcc%7Ccc%7D++++++++++++++++++x+%26+x+%26++x+%26+x++%5C%5C++++++++++++++++++++%26+x+%26++x+%26+x++%5C%5C++%5Chline++++++++++++++++++++%26+++%26++x+%26+x++%5C%5C++++++++++++++++++++%26+++%26++++%26+x+++++++++++++++++%5Cend%7Btabular%7D++%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
A block LU factorization has the form
![\notag A = \left[ \begin{tabular}{cc|cc} 1 & 0 & & \\ 0 & 1 & & \\ \hline x & x & 1 & 0 \\ x & x & 0 & 1 \end{tabular} \right] \left[ \begin{tabular}{cc|cc} x & x & x & x \\ x & x & x & x \\ \hline & & x & x \\ & & x & x \end{tabular} \right].](https://s0.wp.com/latex.php?latex=%5Cnotag++++A+++%3D++%5Cleft%5B+%5Cbegin%7Btabular%7D%7Bcc%7Ccc%7D++++++++++++++++++1+%26+0+%26++++%26++++%5C%5C++++++++++++++++++0+%26+1+%26++++%26++++%5C%5C++%5Chline++++++++++++++++++x+%26+x+%26++1+%26+0++%5C%5C++++++++++++++++++x+%26+x+%26++0+%26+1+++++++++++++++++%5Cend%7Btabular%7D++%5Cright%5D++++++%5Cleft%5B+%5Cbegin%7Btabular%7D%7Bcc%7Ccc%7D++++++++++++++++++x+%26+x+%26++x+%26+x++%5C%5C++++++++++++++++++x+%26+x+%26++x+%26+x++%5C%5C++%5Chline++++++++++++++++++++%26+++%26++x+%26+x++%5C%5C++++++++++++++++++++%26+++%26++x+%26+x+++++++++++++++++%5Cend%7Btabular%7D++%5Cright%5D.+&bg=ffffff&fg=222222&s=0&c=20201002)
Clearly, these are different factorizations. In general, a block LU factorization has the form 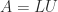


The adjective “block” also applies to a variety of matrix properties, for which there are often special-purpose block algorithms. For example, the matrix
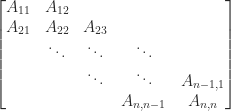
is a block tridiagonal matrix, and a block Toeplitz matrix has constant block diagonals:

One can define block diagonal dominance as a generalization of diagonal dominance. A block Householder matrix generalizes a Householder matrix: it is a perturbation of the identity matrix by a matrix of rank greater than or equal to
References
This is a minimal set of references, which contain further useful references within.
- Nicholas J. Higham, Accuracy and Stability of Numerical Algorithms, second edition, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2002. (Chapter 13, “Block LU Factorization”.)
- Nicholas J. Higham, Numerical Stability of Algorithms at Extreme Scale and Low Precisions, MIMS EPrint 2021.14, Manchester Institute for Mathematical Sciences, The University of Manchester, UK, September 2021.
Related Blog Posts
- Can We Solve Linear Algebra Problems at Extreme Scale and Low Precisions? (2021)
- What Is a Block Matrix? (2020)
- What Is an LU Factorization? (2021)
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
