
The Fugaku supercomputer that tops the HPL-AI mixed-precision benchmark in the June 2021 TOP500 list. It solved a linear system of order 10^7 using IEEE half precision arithmetic for most of the computations.
The largest dense linear systems being solved today are of order 
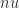


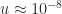
Half precision floating-point arithmetic is now readily available in hardware, in both the IEEE binary16 format and the bfloat16 format, and it is increasingly being used in machine learning and in scientific computing more generally. For the computation of the inner product of two 


The error bounds I have referred to are upper bounds and so bound the worst-case over all possible rounding errors. Their main purpose is to reveal potential instabilities rather than to provide realistic error estimates. Yet we do need to know the limits of what we can compute, and for mission critical applications we need to be able to guarantee a successful computation..
Can we understand the behavior of linear algebra algorithms at extreme scale and in low precision floating-point arithmetics?
To a large extent the answer is yes if we exploit three different features to obtain smaller error bounds.
Blocked Algorithms
Many algorithms are implemented in blocked form. For example, an inner product 


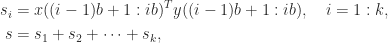
where 
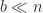





Backward errors for the inner product of two vectors with elements of the form -0.25 + randn, computed in single precision in MATLAB with block size 256.
In fact, one can do even better than an error bound of order 

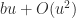
Architectural Features
Intel x86 processors support an 80-bit extended precision format with a 64-bit significand, which is compatible with that specified in the IEEE standard. When a compiler uses this format with 80-bit registers to accumulate sums and inner products it is effectively working with a unit roundoff of 


Some processors have a fused multiply–add (FMA) operation, which computes a combined multiplication and addition 

Mixed precision block FMA operations 

Probabilistic Bounds
Worst-case rounding error bounds suffer from the problem that they are not attainable for most specific sets of data and are unlikely to be nearly attained. Stewart (1990) noted that
To be realistic, we must prune away the unlikely. What is left is necessarily a probabilistic statement.
Theo Mary and I have recently developed probabilistic rounding error analysis, which makes probabilistic assumptions on the rounding errors and derives bounds that hold with a certain probability. The key feature of the bounds is that they are proportional to 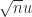
Putting the Pieces Together
The different features we have described can be combined to obtain significantly smaller error bounds. If we use a blocked algorithm with block size 
For example, for a linear system of order 

Our conclusion is that we can successfully solve linear algebra problems of greater size and at lower precisions than the standard rounding error analysis suggests. A priori bounds will always be pessimistic, though. One should compute a posteriori residuals or backward errors (depending on the problem) in order to assess the quality of a numerical solution.
For full details of the work summarized here, see Higham (2021).
References
- Pierre Blanchard, Nicholas Higham, and Theo Mary, A Class of Fast and Accurate Summation Algorithms, SIAM J. Sci. Comput. 42(3), A1541–A1557, 2020.
- Pierre Blanchard, Nicholas Higham, Florent Lopez, Theo Mary, and Srikara Pranesh, Mixed Precision Block Fused Multiply-Add: Error Analysis and Application to GPU Tensor Cores, SIAM J. Sci. Comput. 42(3), C124-C141, 2020
- Michael P. Connolly, Nicholas J. Higham, and Theo Mary, Stochastic Rounding and Its Probabilistic Backward Error Analysis, SIAM J. Sci. Comput. 43(1), A566–A585, 2021.
- Nicholas J. Higham, Numerical Stability of Algorithms at Extreme Scale and Low Precisions, MIMS EPrint 2021.14, Manchester Institute for Mathematical Sciences, The University of Manchester, UK, September 2021.
- Nicholas Higham and Theo Mary, A New Approach to Probabilistic Rounding Error Analysis, SIAM J. Sci. Comput. 41(5), A2815–A2835, 2019.
- G. W. Stewart, Stochastic Perturbation Theory, SIAM Rev. 32(4), 579–610, 1990.

The post “A faster and more accurate sum” by Christine Tobler at https://blogs.mathworks.com/loren/2021/09/07/a-faster-and-more-accurate-sum/ explains that the MATLAB sum function has been using blocked summation for all datatypes since MATLAB R2020b.
How much would a 16-bit [Kulish exact dot product](https://people.eecs.berkeley.edu/~biancolin/papers/arith17.pdf) accumulator change this error analysis?
“The largest dense linear systems being solved today are of order n = 10^7.” I wonder do you mean dense linear systems without any special structure (e.g., not FFT-able)?
Yes.