A vector norm measures the size, or length, of a vector. For complex 

with equality if and only if
(nonnegativity),
for all
(homogeneity),
for all
(the triangle inequality).

An important class of norms is the Hölder 
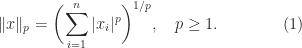
The 


Other important special cases are

A useful concept is that of the dual norm associated with a given vector norm, which is defined by

The maximum is attained because the definition is equivalent to 

We can rewrite the definition of dual norm, using the homogeneity of vector norms, as
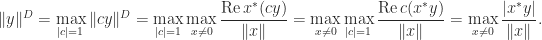
Hence we have the attainable inequality
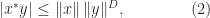
which is the generalized Hölder inequality.
The dual of the 
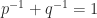

An important special case is the Cauchy–Schwarz inequality,

The notation 

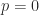



In numerical linear algebra, vector norms play a crucial role in the definition of a subordinate matrix norm, as we will explain in the next post in this series.
All norms on 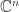
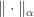
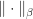
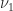
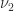
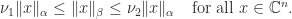
For example, it is easy to see that
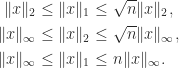
The 2-norm is invariant under unitary transformations: if 

Care must be taken to avoid overflow and (damaging) underflow when evaluating a vector 



References
This is a minimal set of references, which contain further useful references within.
- Takeyuki Harayama, Shuhei Kudo, Daichi Mukunoki, Toshiyuki Imamura, and Daisuke Takahashi, A Rapid Euclidean Norm Calculation Algorithm that Reduces Overflow and Underflow, in Computational Science and Its Applications–ICCSA 2021, O. Gervasi et al., eds, 95–110, Springer, 2021.
- Nicholas J. Higham, Accuracy and Stability of Numerical Algorithms, second edition, Society for Industrial and Applied Mathematics,
- Roger A. Horn and Charles R. Johnson, Matrix Analysis, second edition, Cambridge University Press, 2013. My review of the second edition.
Note: This article was revised on October 12, 2021 to change the definition of dual norm to use 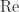
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
