The log-sum-exp function takes as input a real 


where 
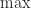

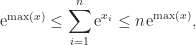
and on taking logs we obtain
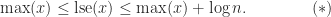
The log-sum-exp function can be thought of as a smoothed version of the max function, because whereas the max function is not differentiable at points where the maximum is achieved in two different components, the log-sum-exp function is infinitely differentiable everywhere. The following plots of 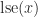
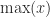


The log-sum-exp function appears in a variety of settings, including statistics, optimization, and machine learning.
For the special case where ![x = [0~t]^T](https://s0.wp.com/latex.php?latex=x+%3D+%5B0%7Et%5D%5ET&bg=ffffff&fg=222222&s=0&c=20201002)
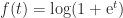
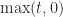
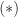
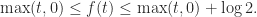
Two points are worth noting.
- While
, in general, we do (trivially) have
, and more generally
.
- The log-sum-exp function is not to be confused with the exp-sum-log function:
.
Here are some examples:
>> format long e
>> logsumexp([1 2 3])
ans =
3.407605964444380e+00
>> logsumexp([1 2 30])
ans =
3.000000000000095e+01
>> logsumexp([1 2 -3])
ans =
2.318175429247454e+00
The MATLAB function logsumexp used here is available at https://github.com/higham/logsumexp-softmax.
Straightforward evaluation of log-sum-exp from its definition is not recommended, because of the possibility of overflow. Indeed, 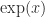
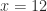

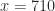
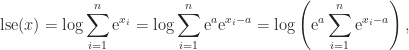
which gives
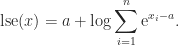
We take 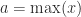
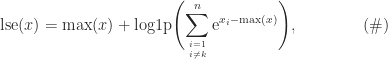
where 

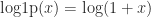
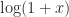

Whereas the original formula involves the logarithm of a sum of nonnegative quantities, when 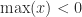

References
This is a minimal set of references, which contain further useful references within.
- Pierre Blanchard, Desmond J. Higham, and Nicholas J. Higham, Accurately Computing the Log-Sum-Exp and Softmax Functions, IMA J. Numer. Anal., Advance access, 2020.
- Ian Goodfellow, Yoshua Bengio, and Aaron Courville, Deep Learning, MIT Press, 2016.
Related Blog Posts
- What is Numerical Stability? (2020)
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.

Nice post! It’s nice to know the sign issue doesn’t cause problem, and to formalize the pulling-the-max-out trick. How is the `scipy.special.logsumexp` implementation?
Two variants that I would find interesting:
(1) if we want to approximate $\|x\|_\infty$, then we can use $f(x) = \log( \sum_i exp^{x_i} + exp^{-x_i} )$. In this case, we’d pull out $max |x_i|$ instead of $max x_i$, but I’m not sure we’d want to do log1p
(2) as for the logsumexp and its relationship to softmax (its derivative), many times each $x_i$ is parameterized by a vector $\theta$ and we want the gradient with respect to $\theta$, so then we have to modify the softmax formula to include the gradients of the $x_i$ terms. I’m thinking the naive implementation is not stable, but there ought to be similar tricks.