Does a symmetric positive definite matrix remain positive definite when we set one or more elements to zero? This question arises in thresholding, in which elements of absolute value less than some tolerance are set to zero. Thresholding is used in some applications to remove correlations thought to be spurious, so that only statistically significant ones are retained.
We will focus on the case where just one element is changed and consider an arbitrary target value rather than zero. Given an  symmetric positive definite matrix
symmetric positive definite matrix  we define
we define  to be the matrix resulting from adding
to be the matrix resulting from adding  to the
to the  and
and  elements and we ask when is positive definite. We can write
elements and we ask when is positive definite. We can write

where 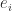 is the
is the  th column of the identity matrix. The perturbation
th column of the identity matrix. The perturbation  has rank
has rank  , with eigenvalues
, with eigenvalues  ,
,  , and
, and  repeated
repeated 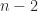 times. Hence we can write in the form
times. Hence we can write in the form  , where
, where  and
and 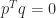 . Adding
. Adding  to causes each eigenvalue to increase or stay the same, while subtracting
to causes each eigenvalue to increase or stay the same, while subtracting  decreases or leaves unchanged each eigenvalue. However, more is true: after each of these rank- perturbations the eigenvalues of the original and perturbed matrices interlace, by Weyl’s theorem. Hence, with the eigenvalues of ordered as
decreases or leaves unchanged each eigenvalue. However, more is true: after each of these rank- perturbations the eigenvalues of the original and perturbed matrices interlace, by Weyl’s theorem. Hence, with the eigenvalues of ordered as  , we have (Horn and Johnson, Cor. 4.3.7)
, we have (Horn and Johnson, Cor. 4.3.7)

Because is positive definite these inequalities imply that 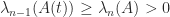 , so has at most one negative eigenvalue. Since
, so has at most one negative eigenvalue. Since  is the product of the eigenvalues of this means that is positive definite precisely when
is the product of the eigenvalues of this means that is positive definite precisely when  .
.
There is a simple expression for , which follows from a lemma of Chan (1984), as explained by Georgescu, Higham, and Peters (2018):

where 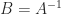 . Hence the condition for to be positive definite is
. Hence the condition for to be positive definite is

We can factorize
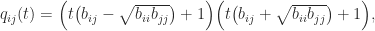
so 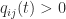 for
for

where the endpoints are finite because  , like , is positive definite and so
, like , is positive definite and so 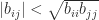 .
.
The condition for to remain positive definite when 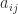 is set to zero is
is set to zero is  , or equivalently
, or equivalently  . To check either of these conditions we need just
. To check either of these conditions we need just  ,
,  , and
, and 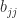 . These elements can be computed without computing the whole inverse by solving the equations
. These elements can be computed without computing the whole inverse by solving the equations 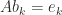 for
for  , for the
, for the  th column
th column  of , making use of a Cholesky factorization of .
of , making use of a Cholesky factorization of .
As an example, we consider the  Lehmer matrix, which has element
Lehmer matrix, which has element  for
for  :
:
![\notag A = \begin{bmatrix} 1 & \frac{1}{2} & \frac{1}{3} & \frac{1}{4} \\[3pt] \frac{1}{2} & 1 & \frac{2}{3} & \frac{1}{2} \\[3pt] \frac{1}{3} & \frac{2}{3} & 1 & \frac{3}{4} \\[3pt] \frac{1}{4} & \frac{1}{2} & \frac{3}{4} & 1 \end{bmatrix}.](https://s0.wp.com/latex.php?latex=%5Cnotag+++A+%3D+%5Cbegin%7Bbmatrix%7D+++++++++1+++++++++++%26+%5Cfrac%7B1%7D%7B2%7D++%26+%5Cfrac%7B1%7D%7B3%7D+%26+%5Cfrac%7B1%7D%7B4%7D+%5C%5C%5B3pt%5D+++++++++%5Cfrac%7B1%7D%7B2%7D+%26+++++++++++1++%26+%5Cfrac%7B2%7D%7B3%7D+%26+%5Cfrac%7B1%7D%7B2%7D+%5C%5C%5B3pt%5D+++++++++%5Cfrac%7B1%7D%7B3%7D+%26++%5Cfrac%7B2%7D%7B3%7D+%26+1+++++++++++%26+%5Cfrac%7B3%7D%7B4%7D+%5C%5C%5B3pt%5D+++++++++%5Cfrac%7B1%7D%7B4%7D+%26++%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B3%7D%7B4%7D+%26++1+++++++++%5Cend%7Bbmatrix%7D.+&bg=ffffff&fg=222222&s=0&c=20201002)
The smallest eigenvalue of is  . Any off-diagonal element except the
. Any off-diagonal element except the 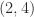 element can be zeroed without destroying positive definiteness, and if the element is zeroed then the new matrix has smallest eigenvalue
element can be zeroed without destroying positive definiteness, and if the element is zeroed then the new matrix has smallest eigenvalue  . For
. For  and
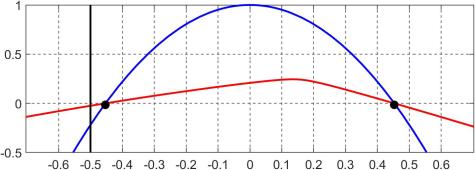
and  , the following plot shows in red
, the following plot shows in red  and in blue
and in blue 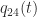 ; the black dots are the endpoints of the closure of the interval
; the black dots are the endpoints of the closure of the interval  and the vertical black line is the value
and the vertical black line is the value 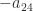 . Clearly, lies outside
. Clearly, lies outside 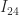 , which is why zeroing this element causes a loss of positive definiteness. Note that also tells us that we can increase
, which is why zeroing this element causes a loss of positive definiteness. Note that also tells us that we can increase  to any number less than
to any number less than  without losing definiteness.
without losing definiteness.
Given a positive definite matrix and a set  of elements to be modified we may wish to determine subsets (including a maximal subset) of for which the modifications preserve definiteness. Efficiently determining these subsets appears to be an open problem.
of elements to be modified we may wish to determine subsets (including a maximal subset) of for which the modifications preserve definiteness. Efficiently determining these subsets appears to be an open problem.
In practical applications thresholding may lead to an indefinite matrix. Definiteness must then be restored to obtain a valid correlation matrix. One way to do this is to find the nearest correlation matrix in the Frobenius norm such that the zeroed elements remain zero. This can be done by the alternating projections method with a projection to keep the zeroed elements fixed. Since the nearest correlation matrix is positive semidefinite, it is also desirable to to incorporate a lower bound 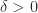 on the smallest eigenvalue, which corresponds to another projection. Both these projections are supported in the algorithm of Higham and Strabić (2016), implemented in the code at https://github.com/higham/anderson-accel-ncm. For the Lehmer matrix, the nearest correlation matrix with zero element and eigenvalues at least
on the smallest eigenvalue, which corresponds to another projection. Both these projections are supported in the algorithm of Higham and Strabić (2016), implemented in the code at https://github.com/higham/anderson-accel-ncm. For the Lehmer matrix, the nearest correlation matrix with zero element and eigenvalues at least  is (to four significant figures)
is (to four significant figures)

A related question is for what patterns of elements that are set to zero is positive definiteness guaranteed to be preserved for all positive definite ? Clearly, setting all the off-diagonal elements to zero preserves definiteness, since the diagonal of a positive definite matrix is positive. Guillot and Rajaratnam (2012) show that the answer to the question is that the new matrix must be a symmetric permutation of a block diagonal matrix. However, for particular this restriction does not necessarily hold, as the Lehmer matrix example shows.
References
- Tony F. Chan, On the Existence and Computation of
 -Factorizations with Small Pivots, Math. Comp. 42(166), 535–547, 1984.
-Factorizations with Small Pivots, Math. Comp. 42(166), 535–547, 1984.
- Dan I. Georgescu, Nicholas J. Higham, and Gareth W. Peters, Explicit Solutions to Correlation Matrix Completion Problems, with an Application to Risk Management and Insurance, Roy. Soc. Open Sci. 5(3), 1–11, 2018
- Dominique Guillot and Bala Rajaratnam, Retaining Positive Definiteness in Thresholded Matrices, Linear Algebra Appl. 436(11), 4143–4160, 2012.
- Nicholas J. Higham and Nataša Strabić, Anderson Acceleration of the Alternating Projections Method for Computing the Nearest Correlation Matrix, Numer. Algorithms 72(4), 1021–1042, 2016. Sections 3.1, 3.2.
- Roger A. Horn and Charles R. Johnson, Matrix Analysis, second edition, Cambridge University Press, 2013. My review of the second edition.