Given a symmetric matrix and a nonnegative number 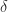
Distance can be measured in any norm, but the most common choice is the Frobenius norm, 
This problem occurs in a very wide range of applications. A typical scenario is that a covariance matrix is approximated in some way that does not guarantee positive semidefinitess, for example by treating blocks of the matrix independently. In machine learning, some methods use indefinite kernels and these can require an indefinite similarity matrix to be replaced by a semidefinite one. When 
The following theorem gives the solution to the problem for the Frobenius norm.
Theorem (Cheng and Higham, 1998).
Let the symmetric matrix
have the spectral decomposition
and let
. The unique matrix with smallest eigenvalue at least
in the Frobenius norm is given by

The theorem says that there is a unique nearest matrix and that is has the same eigenvectors as 




One can pose the same nearness problem for nonsymmetric 
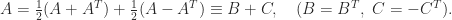
For the 
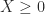

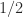
Theorem (Halmos, 1972).
The
where
and a nearest matrix is



When 

Clearly, 


The Frobenius norm solution 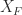

Halmos’s theorem simplifies the computation of 
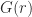

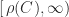

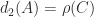
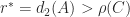

Example
For a numerical example (in MATLAB), we take the Jordan block

The symmetric part of 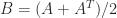
>> A = gallery('jordbloc',5,0); As = sym(A); eig_B = eig((As+As')/2)'
eig_B =
[-1/2, 0, 1/2, -3^(1/2)/2, 3^(1/2)/2]
>> double(eig_B)
ans =
-5.0000e-01 0 5.0000e-01 -8.6603e-01 8.6603e-01
The nearest symmetric positive semidefinite matrix to
B = (A + A')/2; [Q,D] = eig(B); d = diag(D); X_F = Q*diag(max(d,0))*Q';
We can improve this code by using the implicit expansion feature of MATLAB to avoid forming a diagonal matrix. Since the computed result is not exactly symmetric because of rounding errors, we also need to replace it by the nearest symmetric matrix:
[Q,d] = eig(B,'vector'); X_F = Q*(max(d,0).*Q'); X_F = (X_F + X_F')/2;
We obtain
X_F = 1.972e-01 2.500e-01 1.443e-01 -4.163e-17 -5.283e-02 2.500e-01 3.415e-01 2.500e-01 9.151e-02 -1.665e-16 1.443e-01 2.500e-01 2.887e-01 2.500e-01 1.443e-01 -4.163e-17 9.151e-02 2.500e-01 3.415e-01 2.500e-01 -5.283e-02 -1.665e-16 1.443e-01 2.500e-01 1.972e-01
which has eigenvalues
-3.517e-17 7.246e-17 9.519e-17 5.000e-01 8.660e-01
Notice that the three eigenvalues that would be zero in exact arithmetic are of order the unit roundoff. A nearest matrix in the
X_2 = 8.336e-01 5.000e-01 1.711e-01 0.000e+00 -1.756e-02 5.000e-01 6.625e-01 5.000e-01 1.887e-01 0.000e+00 1.711e-01 5.000e-01 6.450e-01 5.000e-01 1.711e-01 0.000e+00 1.887e-01 5.000e-01 6.625e-01 5.000e-01 -1.756e-02 0.000e+00 1.711e-01 5.000e-01 8.336e-01
and its eigenvalues are
-7.608e-17 1.281e-01 5.436e-01 1.197e+00 1.769e+00
The distances are

References
This is a minimal set of references, which contain further useful references within.
- Richard Bouldin, Positive Approximants, Trans. Amer. Math. Soc. 177, 391–403, 1973.
- Sheung Hun Cheng and Nicholas Higham, A Modified Cholesky Algorithm Based on a Symmetric Indefinite Factorization, SIAM J. Matrix Anal. Appl. 19(4), 1097–1110, 1998.
- Nicholas J. Higham, Computing a Nearest Symmetric Positive Semidefinite Matrix, Linear Algebra Appl. 103, 103-118, 1988
- Paul R. Halmos, Positive Approximants of Operators, Indiana Univ. Math. J. 21, 951–960, 1972.
Related Blog Posts
- What Is a Symmetric Positive Definite Matrix? (2020)
- What Is the Nearest Symmetric Matrix? (2020)
- What Is the Polar Decomposition? (2020)
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
