In finite precision arithmetic the result of an elementary arithmetic operation does not generally lie in the underlying number system, 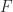
Round to nearest is deterministic: given the same number it always produces the same result. A form of rounding that randomly rounds to the next larger or next smaller number was proposed Barnes, Cooke-Yarborough, and Thomas (1951), Forysthe (1959), and Hull and Swenson (1966). Now called stochastic rounding, it comes in two forms. The first form rounds up or down with equal probability 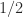
We focus here on the second form of stochastic rounding, which is more interesting. To describe it we let 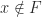
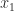
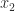


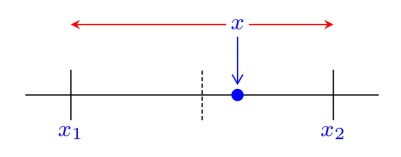
We round up to 


If stochastic rounding chooses to round to
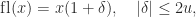
where 
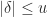
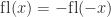
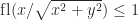
It is not hard to show that the expected value of the result of stochastically rounding 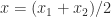
In certain situations, round to nearest produces correlated rounding errors that cause systematic error growth. This can happen when we form the inner product of two long vectors 
![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=222222&s=0&c=20201002)

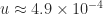
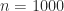

The figure is explained by recent results of Connolly, Higham, and Mary (2020). The key property is that the rounding errors generated by stochastic rounding are mean independent (a weaker version of independence). As a consequence, an error bound proportional to 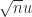
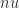
Another notable property of stochastic rounding is that the expected value of the computed inner product is equal to the exact inner product. The same is true more generally for matrix–vector and matrix–matrix products and the solution of triangular systems.
Stochastic rounding is proving popular in neural network training and inference when low precision arithmetic is used, because it avoids stagnation.
Implementing stochastic rounding efficiently is not straightforward, as the definition involves both a random number and an accurate value of the result that we are trying to compute. Possibilities include modifying low level arithmetic routines (Hopkins et al., 2020) and exploiting the augmented operations in the latest version of the IEEE standard floating-point arithmetic (Fasi and Mikaitis, 2020).
Hardware is starting to become available that supports stochastic rounding, including the Intel Lohi neuromorphic chip, the Graphcore Intelligence Processing Unit (intended to accelerate machine learning), and the SpiNNaker2 chip.
Stochastic rounding can be done in MATLAB using the chop function written by me and Srikara Pranesh. This function is intended for experimentation rather than efficient computation.
References
This is a minimal set of references, which contain further useful references within.
- R. C. M. Barnes, E. H. Cooke-Yarborough, and D. G. A. Thomas, An electronic digital computor using cold cathode counting tubes for storage, Electronic Eng. 23, 286–291, 1951.
- Michael P. Connolly, Nicholas J. Higham and Theo Mary, Stochastic Rounding and Its Probabilistic Backward Error Analysis, MIMS EPrint 2020.12, The University of Manchester, UK, April 2020.
- Massimiliano Fasi and Mantas Mikaitis, Algorithms for Stochastically Rounded Elementary Arithmetic Operations in IEEE 754 Floating-Point Arithmetic, MIMS EPrint 2020.9, The University of Manchester, UK, February 2020.
- George Forsythe, Reprint of a note on rounding-off errors, SIAM Rev. 1(1), 66–67, 1959.
- Suyog Gupta and Ankur Agrawal and Kailash Gopalakrishnan and Pritish Narayanan, Deep Learning with Limited Numerical Precision, in Proceedings of the 32nd International Conference on International Conference on Machine Learning – Volume 37, ICML’15, JMLR.org, 2015, pp. 1737–1746,
- Michael Hopkins, Mantas Mikaitis, Dave Lester, and Steve Furber, Stochastic rounding and reduced-precision fixed-point arithmetic for solving neural ordinary differential equations, Phil. Trans. R. Soc. A 378 (2166), 1–22, 2020.
- T. E. Hull and J. R. Swenson, Tests of probabilistic models for propagation of roundoff errors, Comm. ACM 9 (3), 108–113, 1966.
Related Blog Posts
- Stochastic Rounding Has Unconditional Probabilistic Error Bounds by Michael P. Connolly (2020)
- What Is Floating-Point Arithmetic? (2020)
- What Is IEEE Standard Arithmetic? (2020)
- What Is Rounding? (2020)
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
