The pseudoinverse is an extension of the concept of the inverse of a nonsingular square matrix to singular matrices and rectangular matrices. It is one of many generalized inverses, but the one most useful in practice as it has a number of special properties.
The pseudoinverse of a matrix 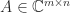
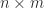

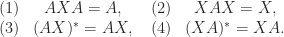
Here, the superscript 
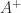
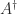
The most important property of the pseudoinverse is that for any system of linear equations 
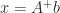
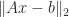

The pseudoinverse can be expressed in terms of the singular value decomposition (SVD). If 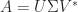
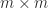




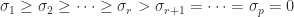


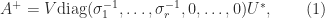
where the diagonal matrix is 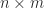
pinv computes
From the Moore–Penrose conditions or (1) it can be shown that 
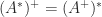
For full rank 
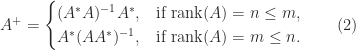
Consequently,

Some special cases are worth noting.
- The pseudoinverse of a zero
matrix is the zero
- The pseudoinverse of a nonzero vector
is
.
- For
,
and if
and
are nonzero then
.
- The pseudoinverse of a Jordan block with eigenvalue
is the transpose:

The pseudoinverse differs from the usual inverse in various respects. For example, the pseudoinverse of a triangular matrix is not necessarily triangular (here we are using MATLAB with the Symbolic Math Toolbox):
>> A = sym([1 1 1; 0 0 1; 0 0 1]), X = pinv(A) A = [1, 1, 1] [0, 0, 1] [0, 0, 1] X = [1/2, -1/4, -1/4] [1/2, -1/4, -1/4] [ 0, 1/2, 1/2]
Furthermore, it is not generally true that 

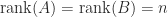
It is not usually necessary to compute the pseudoinverse, but if it is required it can be obtained using (1) or (2) or from the Newton–Schulz iteration
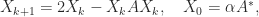
for which 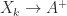

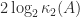

Notes and References
The pseudoinverse was first introduced by Eliakim Moore in 1920 and was independently discovered by Roger Penrose in 1955. For more on the pseudoinverse see, for example, Ben-Israel and Greville (2003) or Campbell and Meyer (2009). For analysis of the Newton–Schulz iteration see Pan and Schreiber (1991).
- Adi Ben-Israel and Thomas N. E. Greville, Generalized Inverses: Theory and Applications, second edition, Springer-Verlag, New York, 2003
- Stephen Campbell and Carl Meyer, Generalized Inverses of Linear Transformations, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 2009. published (Originally published by Pitman in 1979.)
- Victor Pan and Robert Schreiber, An Improved Newton Iteration for the Generalized Inverse of a Matrix, with Applications, SIAM J. Sci. Statist. Comput. 12 (5), 1109–1130, 1991.
Related Blog Posts
This article is part of the “What Is” series, available from https://nhigham.com/category/what-is and in PDF form from the GitHub repository https://github.com/higham/what-is.
 , also known as the field of values, is the set of complex numbers
, also known as the field of values, is the set of complex numbers
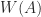 is compact and convex (a nontrivial property proved by Toeplitz and Hausdorff), and it contains all the eigenvalues of
is compact and convex (a nontrivial property proved by Toeplitz and Hausdorff), and it contains all the eigenvalues of  matrices, with the eigenvalues shown as black dots. They were plotted using the function
matrices, with the eigenvalues shown as black dots. They were plotted using the function 
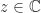 ,
,
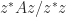 lies between the largest and smallest eigenvalues of the Hermitian matrix
lies between the largest and smallest eigenvalues of the Hermitian matrix  , which define a vertical strip in which the numerical range lies. Since
, which define a vertical strip in which the numerical range lies. Since 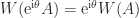 , we can apply the same reasoning to the rotated matrix
, we can apply the same reasoning to the rotated matrix  , and taking a range of
, and taking a range of ![\theta\in[0,\pi]](https://s0.wp.com/latex.php?latex=%5Ctheta%5Cin%5B0%2C%5Cpi%5D&bg=ffffff&fg=222222&s=0&c=20201002) we obtain an approximation the boundary of the numerical range.
we obtain an approximation the boundary of the numerical range.
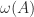 is the largest eigenvalue of the Hermitian matrix
is the largest eigenvalue of the Hermitian matrix 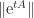 for small positive
for small positive  .
.
 . Also,
. Also,  , where
, where  is the spectral radius (the largest absolute value of any eigenvalue), since
is the spectral radius (the largest absolute value of any eigenvalue), since 
 .
. does not hold in general). However, it is it true that
does not hold in general). However, it is it true that

 then we can bound
then we can bound  for all
for all  .
.
